press x to close
SYS> explain plan for select /*+ index(t1) */ c1 from t1 ;
SYS> @plan
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------
Plan hash value: 3617692013
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 10000 | 40000 | 6 (0)| 00:00:01 |
| 1 | TABLE ACCESS FULL| T1 | 10000 | 40000 | 6 (0)| 00:00:01 |
--------------------------------------------------------------------------
8 rows selected.
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 10000 | 40000 | 6 (0)| 00:00:01 |
| 1 | INDEX FULL SCAN |T1_N1`| 10000 | 40000 | 6 (0)| 00:00:01 |
--------------------------------------------------------------------------
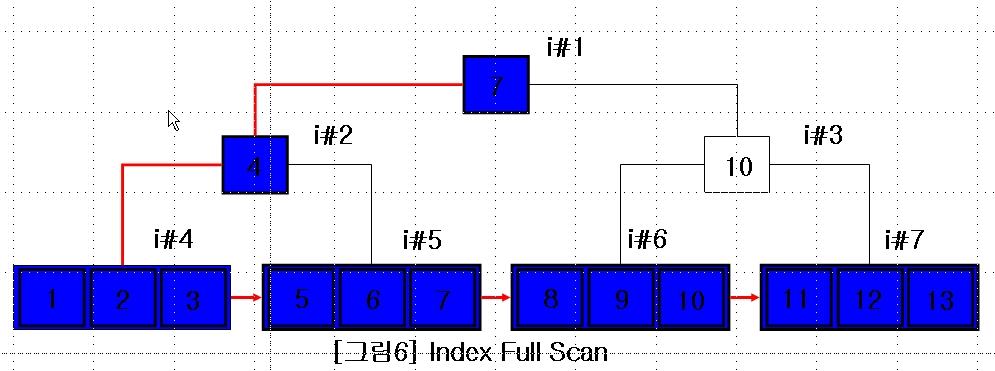 |
SYS>drop table t1 purge ;
Table dropped.
SYS>create table t1(c1 int , c2 int );
Table created.
SYS>create index t1_n1 on t1 ( c1 ) ;
Index created.
SYS>insert into t1 select level, level from dual connect by level <= 10000 ;
10000 rows created.
SYS>commit ;
Commit complete.
SYS>@gather t1
PL/SQL procedure successfully completed.
-- Index Hint 를 부여했음에도 불구하고 Table Full Scan 이 선택된다.
SYS>explain plan for select /* index(t1) */ c1 from t1 ;
Explained.
SYS>@plan
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------
Plan hash value: 3617692013
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 10000 | 40000 | 6 (0)| 00:00:01 |
| 1 | TABLE ACCESS FULL| T1 | 10000 | 40000 | 6 (0)| 00:00:01 |
--------------------------------------------------------------------------
8 rows selected.
-- Order By 구문을 이용해 정렬된 결과를 얻고자 할 경우에도 역시 Table Full Scan 이 선택된다.
SYS>explain plan for select /* index(t1) */ c1 from t1 order by c1 ;
Explained.
SYS>@plan
PLAN_TABLE_OUTPUT
---------------------------------------------------------------------------
Plan hash value: 2148421099
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 10000 | 40000 | 8 (25)| 00:00:01 |
| 1 | SORT ORDER BY | | 10000 | 40000 | 8 (25)| 00:00:01 |
| 2 | TABLE ACCESS FULL| T1 | 10000 | 40000 | 6 (0)| 00:00:01 |
---------------------------------------------------------------------------
9 rows selected.
SYS>alter table t1 modify c1 not null ;
Table altered.
SYS>explain plan for select /* index(t1) */ c1 from t1 ;
Explained.
SYS>@plan
PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------
Plan hash value: 587075276
------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 10000 | 40000 | 6 (0)| 00:00:01 |
| 1 | INDEX FAST FULL SCAN| T1_N1 | 10000 | 40000 | 6 (0)| 00:00:01 |
------------------------------------------------------------------------------
8 rows selected.
-- Order by 구문으로 원하는 Index Full Scan 을 사용한다.
SYS>explain plan for select c1 from t1 order by c1 ;
Explained.
SYS>@plan
PLAN_TABLE_OUTPUT
-------------------------------------------------------------------------------
Plan hash value: 3098903643
-------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 10000 | 40000 | 8 (25)| 00:00:01 |
| 1 | SORT ORDER BY | | 10000 | 40000 | 8 (25)| 00:00:01 |
| 2 | INDEX FAST FULL SCAN| T1_N1 | 10000 | 40000 | 6 (0)| 00:00:01 |
-------------------------------------------------------------------------------
9 rows selected.
SYS>explain plan for select /*+ index(t1) */ max(c1) from t1 ;
Explained.
SYS>@plan
PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------------
Plan hash value: 1426435604
------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 4 | 2 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 4 | | |
| 2 | INDEX FULL SCAN (MIN/MAX)| T1_N1 | 10000 | 40000 | 2 (0)| 00:00:01 |
------------------------------------------------------------------------------------
9 rows selected.
SYS>explain plan for select /*+ index(t1) */ max(c1) from t1 where c1 > 1 ;
Explained.
SYS>@plan
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------
Plan hash value: 227387708
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 4 | 2 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 4 | | |
| 2 | FIRST ROW | | 9999 | 39996 | 2 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN (MIN/MAX)| T1_N1 | 9999 | 39996 | 2 (0)| 00:00:01 |
--------------------------------------------------------------------------------------
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("C1">1)
15 rows selected.
SYS>explain plan for select /*+ index(t1) */ min(c1), max(c1) from t1 ;
Explained.
SYS>@plan
PLAN_TABLE_OUTPUT
-------------------------------------------------------------------------
Plan hash value: 232612676
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 4 | 20 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 4 | | |
| 2 | INDEX FULL SCAN| T1_N1 | 10000 | 40000 | 20 (0)| 00:00:01 |
--------------------------------------------------------------------------
9 rows selected.
SYS>explain plan for select /*+ index(t1) */ min(c1) from t1
union all
select /*+ index(t1) */ max(c1) from t1 ;
Explained.
SYS>@plan
PLAN_TABLE_OUTPUT
-------------------------------------------------------------------------------------
Plan hash value: 94001445
-------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2 | 8 | 4 (50)| 00:00:01 |
| 1 | UNION-ALL | | | | | |
| 2 | SORT AGGREGATE | | 1 | 4 | | |
| 3 | INDEX FULL SCAN (MIN/MAX)| T1_N1 | 10000 | 40000 | 2 (0)| 00:00:01 |
| 4 | SORT AGGREGATE | | 1 | 4 | | |
| 5 | INDEX FULL SCAN (MIN/MAX)| T1_N1 | 10000 | 40000 | 2 (0)| 00:00:01 |
SYS>@check_table_and_indexes.sql
TABLE_NAME ROW_S BLOCKS EMPTY_BLOCKS AVG_ROW_LEN SAMPLE_SIZE ANA
-------------------- ---------- ---------- ------------ ----------- ----------- -----------------
T1 10000 20 0 7 10,000 20090308 17:11:54
INDEX_NAME ROW_S BLEVEL LEAF_B DIS_KEY KEYPERLEAF CLUSETERING SAMPLE_SIZE ANA
-------------------- ---------- ---------- ---------- ---------- ---------- ----------- ----------- -----------------
T1_N1 10000 1 19 10000 1 18 10,000 20090308 17:11:54
SYS>explain plan for select count(*) from t1 where c1 like '%'||:b1||'%' ;
Explained.
SYS>@plan
PLAN_TABLE_OUTPUT
-------------------------------------------------------------------------------
Plan hash value: 3675732849
-------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 4 | 7 (15)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 4 | | |
|* 2 | INDEX FAST FULL SCAN| T1_N1 | 500 | 2000 | 7 (15)| 00:00:01 |
-------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter(TO_CHAR("C1") LIKE '%'||:B1||'%')
14 rows selected.
SYS>create table t1 ( c1 varchar2(10), c2 char(10));
Table created.
SYS>insert into t1 select level , 'a' from dual connect by level <= 10000 ;
10000 rows created.
SYS>commit ;
Commit complete.
SYS>create index t1_n1 on t1(c1) ;
Index created.
SYS>@gather t1
PL/SQL procedure successfully completed.
SYS>select * from t1 where rownum < 10 ;
C1 C2
---------- ----------
1 a
2 a
3 a
4 a
5 a
6 a
7 a
8 a
9 a
9 rows selected.
-- Table 및 Index 정보 체크
SYS>@check_table_and_indexes.sql
TABLE_NAME ROW_S BLOCKS EMPTY_BLOCKS AVG_ROW_LEN SAMPLE_SIZE ANA
-------------------- ---------- ---------- ------------ ----------- ----------- -----------------
T1 10000 31 0 15 10,000 20090310 21:05:58
INDEX_NAME ROW_S BLEVEL LEAF_B DIS_KEY KEYPERLEAF CLUSETERING SAMPLE_SIZE ANA
-------------------- ---------- ---------- ---------- ---------- ---------- ----------- ----------- -----------------
T1_N1 10000 1 23 10000 1 1885 10,000 20090310 21:05:58
C_NAME DATA_TYPE D_L NULL NUM_DISTINCT DEN NUM_NULLS NUM_BUC ANA SAMPLE_SIZE USER_STATS HIS
-------------------- ---------- ---- ---- ------------ ---- ------------ ------- ----------------- ------------ ---------- ---------------
C1 VARCHAR2 10 Y 10,000 0 0 1 20090310 21:05:58 10,000 NO NONE
C2 CHAR 10 Y 1 1 0 1 20090310 21:05:58 10,000 NO NONE
SYS>var b1 varchar2(1) ;
SYS>-- when value = 1
SYS>exec :b1 := '1' ;
PL/SQL procedure successfully completed.
SYS>select /*+ gather_plan_statistics */ count(*) from t1 where c1 like '%'||:b1||'%';
COUNT(*)
----------
3440
SYS>@stat
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------------
SQL_ID 824h9cx550a8q, child number 0
-------------------------------------
select /*+ gather_plan_statistics */ count(*) from t1 where c1 like '%'||:b1||'%'
Plan hash value: 73337487
--------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | Cost (%CPU)| A-Rows | A-Time | Buffers |
--------------------------------------------------------------------------------------------------
| 1 | SORT AGGREGATE | | 1 | 1 | | 1 |00:00:00.01 | 24 |
|* 2 | INDEX RANGE SCAN| T1_N1 | 1 | 500 | 3 (0)| 3440 |00:00:00.01 | 24 |
--------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("C1" LIKE '%'||:B1||'%')
filter("C1" LIKE '%'||:B1||'%')
19 rows selected.
-- BIND 변수 사용시
-- INDEX RANGE SCAN / COST - 3 , BUFFER - 24
SYS>select /*+ gather_plan_statistics index(t1) */ count(*) from t1 where c1 like '%1%';
COUNT(*)
----------
3440
SYS>@stat
PLAN_TABLE_OUTPUT
-------------------------------------------------------------------------------------------------
SQL_ID 685w3zrj87tzc, child number 0
-------------------------------------
select /*+ gather_plan_statistics index(t1) */ count(*) from t1 where c1 like '%1%'
Plan hash value: 232612676
-------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | Cost (%CPU)| A-Rows | A-Time | Buffers |
-------------------------------------------------------------------------------------------------
| 1 | SORT AGGREGATE | | 1 | 1 | | 1 |00:00:00.01 | 24 |
|* 2 | INDEX FULL SCAN| T1_N1 | 1 | 500 | 24 (0)| 3440 |00:00:00.01 | 24 |
-------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("C1" LIKE '%1%')
18 rows selected.
-- LITERAL 변수 사용시
-- INDEX FULL SCAN / COST - 24 , BUFFER - 24
-- BIND 변수 사용시
-- INDEX RANGE SCAN / COST - 3 , BUFFER - 24
SYS>-- when value = x ( non-existent value )
SYS>exec :b1 := 'x'
PL/SQL procedure successfully completed.
SYS>select /*+ gather_plan_statistics */ count(*) from t1 where c1 like '%'||:b1||'%';
COUNT(*)
----------
0
SYS>@stat
PLAN_TABLE_OUTPUT
------------------------------------------------------------------------------------------------
SQL_ID 824h9cx550a8q, child number 0
-------------------------------------
select /*+ gather_plan_statistics */ count(*) from t1 where c1 like '%'||:b1||'%'
Plan hash value: 73337487
--------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | Cost (%CPU)| A-Rows | A-Time | Buffers |
--------------------------------------------------------------------------------------------------
| 1 | SORT AGGREGATE | | 1 | 1 | | 1 |00:00:00.01 | 24 |
|* 2 | INDEX RANGE SCAN| T1_N1 | 1 | 500 | 3 (0)| 0 |00:00:00.01 | 24 |
--------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("C1" LIKE '%'||:B1||'%')
filter("C1" LIKE '%'||:B1||'%')
19 rows selected.
-- 실제 존재하지 않는 값을 Bind 변수로 사용
-- INDEX RANGE SCAN / Cost - 3, Buffers - 24
-- LITERAL 변수 사용시
-- INDEX FULL SCAN / COST - 24 , BUFFER - 24
-- BIND 변수 사용시
-- INDEX RANGE SCAN / COST - 3 , BUFFER - 24
SYS>select /*+ gather_plan_statistics index(t1) */ count(*) from t1 where c1 like '%x%';
COUNT(*)
----------
0
SYS>@stat
PLAN_TABLE_OUTPUT
-----------------------------------------------------------------------------------------------
SQL_ID 1phpx84ugxfm6, child number 0
-------------------------------------
select /*+ gather_plan_statistics index(t1) */ count(*) from t1 where c1 like '%x%'
Plan hash value: 232612676
-------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | Cost (%CPU)| A-Rows | A-Time | Buffers |
-------------------------------------------------------------------------------------------------
| 1 | SORT AGGREGATE | | 1 | 1 | | 1 |00:00:00.01 | 24 |
|* 2 | INDEX FULL SCAN| T1_N1 | 1 | 500 | 24 (0)| 0 |00:00:00.01 | 24 |
-------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("C1" LIKE '%x%')
18 rows selected.
-- 실제 존재하는 값을 Literal 변수로
-- INDEX FULL SCAN / Cost - 24, Buffers - 24
-- 실제 존재하지 않는 값을 Bind 변수로 사용
-- INDEX RANGE SCAN / Cost - 3, Buffers - 24
-- LITERAL 변수 사용시
-- INDEX FULL SCAN / COST - 24 , BUFFER - 24
-- BIND 변수 사용시
-- INDEX RANGE SCAN / COST - 3 , BUFFER - 24
SYS>select /*+ gather_plan_statistics index_ffs(t1) */ count(*) from t1 where c1 like '%x%' ;
COUNT(*)
----------
0
SYS>@stat
PLAN_TABLE_OUTPUT
-----------------------------------------------------------------------------------------------------
SQL_ID fvfds3ugz2296, child number 0
-------------------------------------
select /*+ gather_plan_statistics index_ffs(t1) */ count(*) from t1 where c1 like '%x%'
Plan hash value: 3675732849
------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | Cost (%CPU)| A-Rows | A-Time | Buffers |
------------------------------------------------------------------------------------------------------
| 1 | SORT AGGREGATE | | 1 | 1 | | 1 |00:00:00.01 | 28 |
|* 2 | INDEX FAST FULL SCAN| T1_N1 | 1 | 500 | 7 (0)| 0 |00:00:00.01 | 28 |
------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("C1" LIKE '%x%')
18 rows selected.
- 강좌 URL : http://www.gurubee.net/lecture/3862
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.