관계형 데이터 모델링 프리미엄 가이드 DB구축 (2014년)
13.4 비정규화 방법
엔터티 합체
1:1 관계의 엔터티 합체
- 엄밀히 비정규화는 아니다.단지 성능 향상을 위해서 엔터티를 합치지만넓은 의미의 비정규화로 본다.
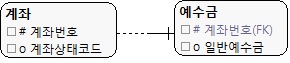 |
| (그림 13.6) 경합이 발생하지 않도록 분해한 모델 |
1:M 관계의 엔터티 합체
- 마스터(MASTER)와 상세(DETAIL)관계의 엔터티도 합체 대상이 될수있다.
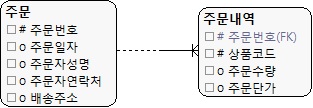 |
| (그림 13.7) Master 와 Detail의 일대다(1:M) 관계인 모델과 릴레이션 |
- 주문
| #주문번호 | 주문일자 | 주문자 성명 | 주문자 연락처 | 배송주소 |
|---|---|---|---|---|
| 100 | 2025-01-01 | 홍길동 | 1234-5678 | 경기도 |
- 주문내역
| #주문번호 | #상품코드 | 주문수량 | 주문단가 |
|---|---|---|---|
| 100 | A10 | 1 | 500 |
| 200 | B20 | 2 | 100 |
- 위와 같은 관계에서 주문을 빠르게 조회해야 하는 특별한 요건이 있다만 그림 13.8과 같이 비정규해야한다.
- 주문내역의 엔터티의 속성은 그대로 두고 주문 엔터티의 속성을 포함한다. 그러면 주문속성값이 중복으로 관리된다.
- 그림 13.8 은 많은중복을 발생하므로 도저히 해결할 수 없는 성능 이슈가 아니라면 채택하지 않는다.
 |
| (그림 13.8) 일대다 관계인 엔터티를 합체한 비정규형 모델과 릴레이션 |
- 주문내역
| #주문번호 | #상품코드 | 주문일자 | 주문자성명 | 주문자연락처 | 배송주소 | 주문수량 | 주문단가 |
|---|---|---|---|---|---|---|---|
| 100 | A10 | 2025-01-01 | 홍길동 | 1234-5678 | 경기도 | 1 | 500 |
| 100 | B20 | 2025-01-01 | 홍길동 | 1234-5678 | 경기도 | 2 | 100 |
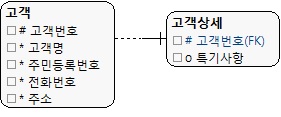
엔터티 분해
- 엔터티 분해는 수직 분해와 수평분해로 나눌수 있다.
- 수직분해는 엔터티의 일부 속성을 별도의 엔터티로 분해하는것이다.
- 수직분해는 속성의 사용빈도로 기준을 나누거나 VACHAR2(4000) , LOB 과 같은 특별한데이터 타입의 속성을 기준으로 분해한다.
- 성능을 고려해서 하나의 엔터티를 일대일 관계로 분해하는것은 자주 사용하는 속성과 그렇지 않은 속성으로 분리한다.
- 자주 쓰이는 속성많으로 구성하면 성능 측면에서 최적이 될수있다.
- 조회가 빈번한 속성과 UPDATE가빈번한 속성을 분리하기도 한다. (ROCK에 의한 성능 저하를 방지)
- 엔터티 전체 속성 사이즈가 기본 블록 사이즈를 초과할때 트랜재션등을 검토하여수직분리한다.
- 수평분해는 파티셔닝(Partitioning)을 의미한다.
단순 수직 분리한모델
 |
| (그림 13.9) 긴텍스트를 일대일 관계로 분리 |
텍스트 속성을 따로 분리한 모델
 |
| (그림 13.10) 긴 텍스트 속성을 통합해서 관리하는 모델 |
관리가 힘든 분리 모델
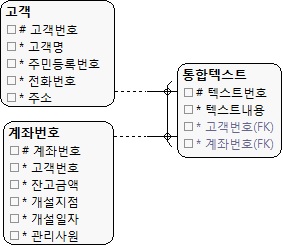 |
| (그림 13.11) 베타 관계가 발생하는 유연하지 못한 모델 |
요약 엔터티 추가
- 비정규화 방법중 하나가 요약 엔터티를 생성하는것이다.
- 합계나 집계등을 미리 계산해서 저장해 놓음으로써 조회 성능을 향상 시킬수 있다.
- 미리 계산되는것도 중복해서 관리하는 방법이므로 데이터 정합성에 주의해야한다.
- 원천데이터가 수정되는 시점에 실시간으로 요약 엔터티를 수정하는 방법과 배치(BATCH)로 데이트를 맞추는 방법이 있다.
- 요약 엔터티와 비슷한 중복엔터티도 있다.
- 1. 서버가 다를때 원격 조인을 없애기 위해 엔터티를 복사해서 한다. (EAI 솔류션에 사용)
- 2. 많이 조회되는 엔터티가 있다면 조회성능 향상을 위해 복사해 사용할수있다. (메모리 WAIT 때문에 사용하나 정확한 근거를 기반으로 해야한다.)
중복 속성 채택
- 중복 속성은 말그대로 이미 존재하는 속성의 값을 중복해서 쓰는 속성이다.
- 어떤 엔터티에 존재하는 값을 복사해서 그대로 가져다 놓고 사용하는 속성을 의미한다.
- 엔터티의 관계는 참조 관계보다 종속적 관계일때 적당하다.
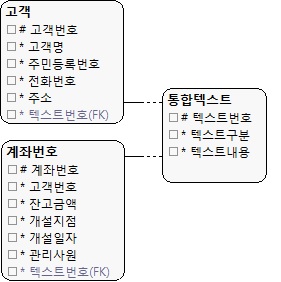
시점 데이터 모델
- 계좌테이블에서 고객 테이블에서주민등호를 조회하지 않아도 된다.
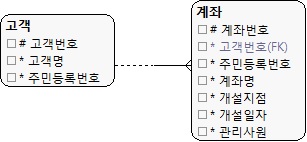 |
| (그림 13.12) 중복 속성(주민등록번호)이 사용된 모습 |
시점 데이터와 이력데이터모델
- 고객 변경일자에 주민번호가 변경될시점의 주민번호를 조회 해야할경우 (HISTORY TABLE )
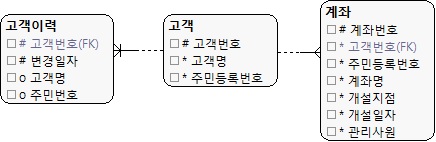 |
| (그림 13.13) 시점 데이터와 이력 데이터가 존재하는 주민등록번호 속성 |
추출 속성 채택
- 추출속성은 기존속성의 SUM, COUNT , LAST , FIRST , MAX , MIN , AVG등의 값을 관리하는 속성이다.
- 추출속성은 처리 범위가 넓을때 한해서 제한적으로 사용해야한다.
- 추출속성은 대부분 실시간으로 맞춰야하므로 데이터 정합성에 문제가 발생한다.
추출 속성 모델 예시
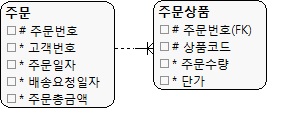 |
| (그림 13.14) 더한 값의 추출속성 |
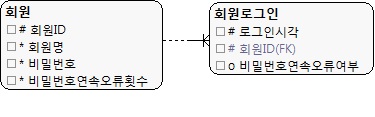 |
| (그림 13.15) 총횟수를 추출해서 관리하는 모델 |
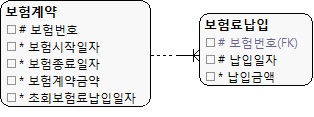 |
| (그림 13.16) 최초 값을 추출해서 관리하는 모델 |
관계속성 예시
- 여러단계를 거쳐 상위 엔터티를 조인해야할경우 성능 문제로 해당 엔터티와 직접관계를 관리한다.
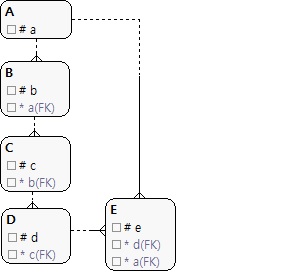 |
| (그림 12.22) 추출(중복) 관계를 사용한 모델 |
추출 속성 채택
- 엔터티에서 반복되는 속성이 존재하면 정규화해야한다. 하지만 성능이슈가 발생하면 비정규형을 고려해야 한다.
- 그림13.23 모델의 왼쪽 엔터티가 정규형이며 오른쪽 엔터티가 비정규형이다.
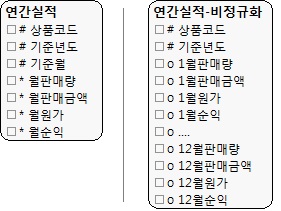 |
| (그림 13.23) 정규형 엔터티 & 비정규형 엔터티 |
추출 속성 채택
- 모델 구조적으로는 달라지는 것은 없지만 중복 데이터를 채탹하는것도 넓은 의미에서 비정규화에 포함된다.
- 그림 13.25 계좌 엔터티에서는 현재의 계좌 관리 사원을 관리하고 계좌 관리사원이력 엔터티에서는 과거의 관리 사원을 관리한다. 하지만 현재와 과거의 관리 사원 데이타를 동시에 추출하는 요건이 많으면 조회의 효율성을 위해 계좌관리사원이력 엔터티에서 현재 시점의 관리 사원도 중복으로 관리한다.
 |
| (그림 13.25) 현재 데이터를 중복으로 관리하는 계좌 관리 이력사원 |
"구루비 데이터베이스 스터디모임" 에서 2014년에 "관계형 데이터 모델링 프리미엄 가이드" 도서를 스터디하면서 정리한 내용 입니다.
- 강좌 URL : http://www.gurubee.net/lecture/3657
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.