- 1. 전체스캔
- 1.1 전체 스캔과 다중 블록 읽기 계수
- 1.2 전체 스캔과 최고 수위선(HWM)
- 2. ROWID 액세스
- ROWID FORMAT
- 2.1 ROWID 활용으로 검색속도 높이기
- 2.2 ROWID 범위
- 3. 인덱스 스캔
- 3.1 B*트리구조
- 3.2 인덱스 고유 스캔
- 3.3 인덱스 범위 스캔
- 3.4 인덱스 건너뛰기 스캔 ( INDEX SKIP SCAN )
- 3.5 인덱스 전체 스캔
- 3.6 빠른 인덱스 전체 스캔
- 3.7 인덱스 조인
1. 전체스캔
- 단순히 모든 블록을 순차적으로 읽는 것.
- 다중블록읽기 채용
- 초대형작업에서 전체스캔은 인덱스를 사용하는 것 보다 훨씬 빠르다.
1.1 전체 스캔과 다중 블록 읽기 계수
<실습>
1.2 전체 스캔과 최고 수위선(HWM)
- 전체스캔은 항상 세그먼트의 최고수위선(HWM) 아래에 있는 모든 블록을 읽는다.
- 데이터 삭제(delete)시에도 HWM까지 읽게 되므로 결과건수는 적더라도 실제 논리적인I/O는 삭제되기 전과 동일하다.
- 이를 방지하려면 테이블을 재편성 해야 한다.
- ( 테이블을 재편성하는 방법으로는 table move, export/import, rename/ctas 등이 있음 )
- 혹은 주삭제 대상 데이터 단위별로 파티션을 구성한 후 파티션별로 TRUNCATE PARTITION 혹은 DROP PARTITION을 한다.
2. ROWID 액세스
- ROWID : 데이터의 물리적인 주소로서 파일에 관한행, 블록, 블록의 행에 관한 정보를 갖고 있다.
- 인덱스 스캔이 이루어진 후 테이블액세스 시에 사용된다.

- Data Object Number : DB Segmemet식별정보(해당 row가 속해있는 Object 번호)
- Relative File Number : Tablespace에 상대적인 Data file 번호(해당 row가 속해있는 데이터파일번호)
- Block Number : Row를 포함하는 Data Block번호(해당 row가 속해있는 데이터 파일의 데이터블록 주소값)
- Row Number : Block에서의 Row Slot(데이터 블록내의 해당 로우의 주소값)
2.1 ROWID 활용으로 검색속도 높이기
ROWID 액세스는 언제 발생하는가?
- Rowid가 조건으로 공급된 경우
- 인덱스를 사용하여 Table 을 access 한경우
ROWID 액세스의 특징
- Rowid를 이용해서 해당테이블의 특정 Block의 특정 Row를 찾아간다.
- 가장 빠른 Access 방식이다.
- 주로 max/min 일자를 찾아서 그일자에 해당하는 값을 select 할때 유용하게 사용된다.
ROWID 액세스를 하기 위한 힌트
2.2 ROWID 범위
- ROWID의 범위를 사용하면 하나의 테이블에 대한 모든 작업을 병렬로 처리가능
- (각 프로그램이 하나의 테이블에 대해서 물리적으로 뭉쳐있는 데이터에 대하여 수행되도록 보장하기 때문)
- 각 프로그램이 같은 공유 디스크 리소스로 다투지 않음
3. 인덱스 스캔
3.1 B*트리구조
이진트리
- 이진 트리(Binary tree)는 모든 노드의 차수가 2이하인 트리(Tree)로 하나의 노드는 두 개의 자식 노드(child)를 가질 수 있다.
- 부모가 왼쪽, 오른쪽 두개의 자식을 가지는 트리.
- 인덱스를 조직하는 방법으로 가장 많이 사용되는 것.
- 검색은 루트에서부터 시작한다.
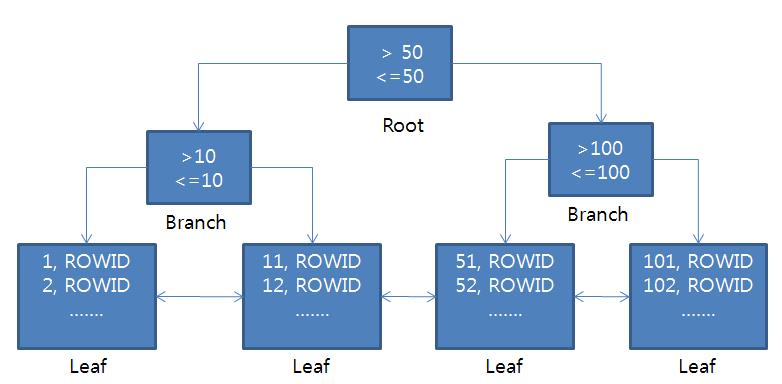
- Root : 인덱스의 다음 레벨을 가리키는 엔트리 포함
- Branch : 인덱스의 다음 레벨을 가리키는 엔트리 포함
- Leaf : 테이블의 행을 가리키는 인덱스 엔트리를 포함. 양방향 Linked List로 연결
이진탐색 트리
- 이진 탐색 트리는 이진 트리의 일종으로 모든 노드는 유일한 키 값을 가짐.
- 루트 노드의 왼쪽 서브 트리에 있는 노드는 모두 루트 노드보다 작은 키 값을 가짐.
- 루트 노드의 오른쪽 서브 트리에 있는 노드는 모두 루트 노드보다 큰 키 값을 가짐.
- 왼쪽 자식 < 부모 < 오른쪽 자식
3.2 인덱스 고유 스캔
- 인덱스 조회로부터 번환되는 행은 1개.
- 고유인덱스에서는 오직 인덱스 키값에 따라 정렬된다.
- ( 고유하지 않은 인덱스에서는 인덱스 키값에 의해 정렬된 다음 동일한 값에 대해서는 ROWID에 따라 또다시 정렬됨)
- 인덱스 고유스캔을 하기 위한 힌트 : /*+ index(테이블) */
3.3 인덱스 범위 스캔
- 행이 하나도 반환되지 않거나, 하나 또는 그 이상의 행이 반환됨.
인덱스 범위스캔을 하기 위한 힌트
- /*+ index(테이블) */
- /*+ index_desc(테이블) */
참고-Index Range Scan
3.4 인덱스 건너뛰기 스캔 ( INDEX SKIP SCAN )
- 테이블의 데이터 분포에 대한 통계정보가 정상적으로 생성되어져 있고 결합인덱스를 가진 테이블에 질의를 할 때 선행하는 컬럼에 대한 조건절이 오지 않더라도 인덱스 스캔을 하는 스캔.(오라클9i 이상)
- Oracle 옵티마이저를 비용기반 옵티마이져(CBO)로 사용해야만 한다.
- (규칙기반 옵티마이져(RBO)가 사용되고 있다면, Index Skip Scan은 사용할 수 없음)
- Index Skip Scan을 이용하기 위해서는 INDEX_SS, INDEX_SS_ASC, INDEX_SS_DESC 힌트를 사용함.
- Index Skip Scan을 수행 했을 경우 실행 계획은 다음과 같이 나타난다.
SELECT STATEMENT Optimizer=CHOOSE (Cost=6 Card=1 Bytes=5)
0 SORT (AGGREGATE)
1 INDEX (SKIP SCAN) OF 'EMP_ID' (NON-UNIQUE)
인덱스 건너뛰기 스캔을 하기 위한 힌트
3.5 인덱스 전체 스캔
- 인덱스의 모든 잎블록을 처리한다.
- 테이블 전체스캔과는 달리 인덱스 구조의 모든 블록을 읽지는 않는다. (첫블록을 찾을때 까지만 가지블록을 처리함)
- 이중 연결리스트를 이용하여 인덱스 구조를 앞, 뒤로 순회함.
- 그러므로 단일블록I/O를 사용함. (<= 테이블 전체 스캔과의 차이점)
- 별도의 정렬작업을 피하기 위하여 인덱스 전체스캔이 사용될 수도 있음.
- 직접적으로 full scan 을 유도하는 힌트는 없음.
- 참고 Index Full Scan
3.6 빠른 인덱스 전체 스캔
- 내부 가지 블록을 포함하여 인덱스 구조의 모든 블록을 읽음.
- 다중블록읽기를 사용함.
- 데이터를 정렬된 순서대로 검색하지 않음.
빠른 인덱스 전체 스캔을 하기 위한 힌트
3.7 인덱스 조인
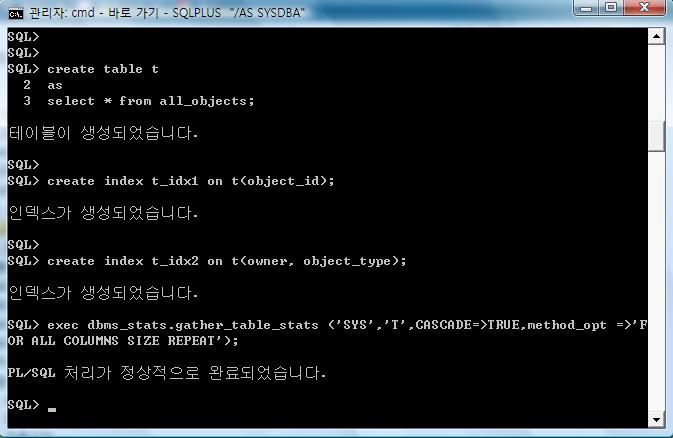
create table t
as
select * from all_objects;
create index t_idx1 on t(object_id);
create index t_idx2 on t(owner, object_type);
exec dbms_stats.gather_table_stats ('SYS','T',CASCADE=>TRUE,method_opt =>'FOR ALL COLUMNS SIZE REPEAT');
select object_id, owner, object_type
from t
where object_id between 100 and 2000
and owner = 'SYS';
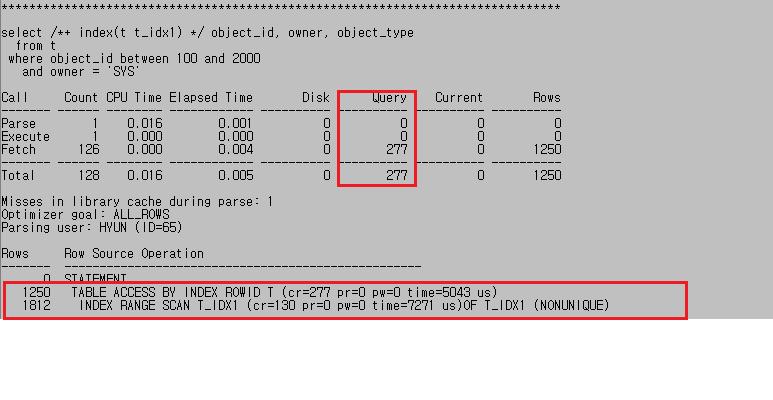
select /*+ index(t t_idx1) */ object_id, owner, object_type
from t
where object_id between 100 and 2000
and owner = 'SYS';
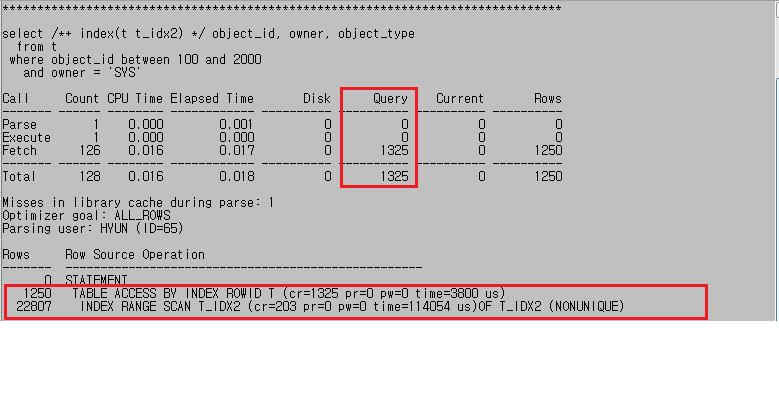
select /*+ index(t t_idx2) */ object_id, owner, object_type
from t
where object_id between 100 and 2000
and owner = 'SYS';
TEST
- 테이블 및 인덱스 생성, 통계정보 수집
- 인덱스 조인
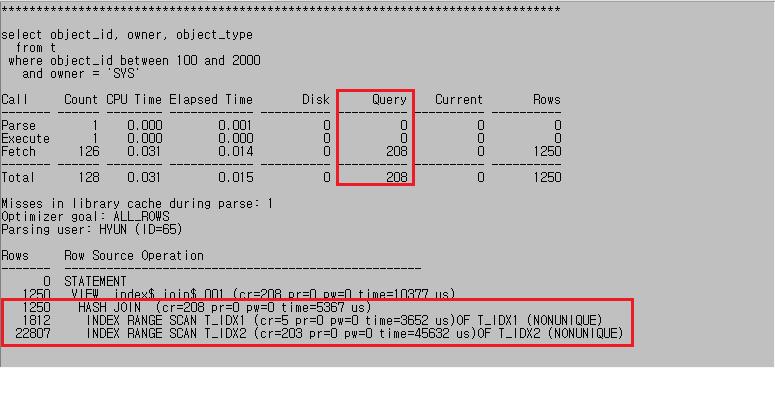
- t_idx1 인덱스 사용
- t_idx2 인덱스 사용