press x to close
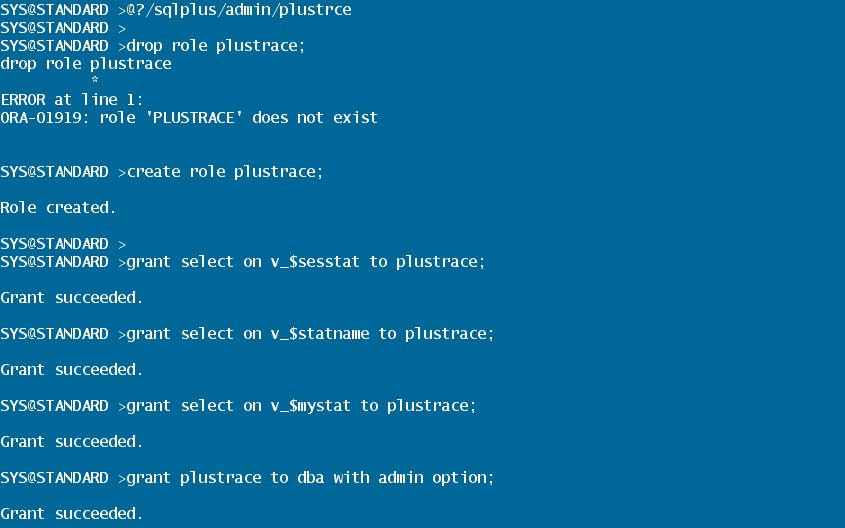
sqlplus /as sysdba
grant plustrace to hr

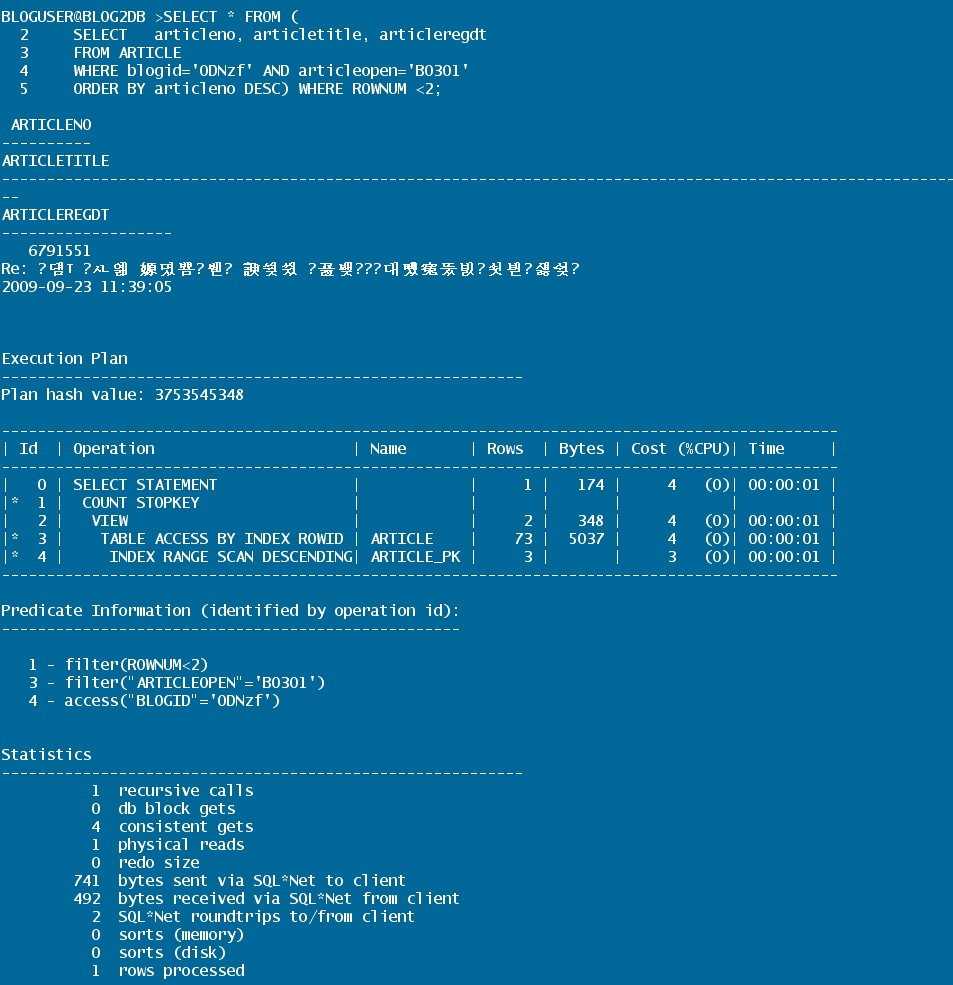
| 반환된 통계 | 의미 |
|---|---|
| Recursive calls | 사용자의 SQL문을 실행하기 위하여 수행된 SQL 문의 수 |
| Db block gets | 현재 모드(current mode)에서 버퍼 캐시로부터 읽어온 블록의 총 수 |
| Consistent gets | 버퍼 캐시의 블록에 대한 일관된 읽기의 요청 횟수. 일관된 읽기는 언두 정보, 즉 롤백 정보에 대한 읽기를 요구할 수도 있으며 이들 언두에 대한 읽기도 계산된다. |
| Physical reads | 물리적으로 데이터 파일을 읽어 버퍼 캐시에 넣은 횟수 |
| Redo size | 해당 문이 실행되는 동안 생성된 리두의 전체 크기를 바이트 단위로 나타낸 수 |
| Byte sent via SQL*Net to client | 서버로부터 클라이언트에 전송된 총 바이트 수 |
| Byte recevied via SQL*Net from client | 클라이언트로부터 받은 총 바이트 수 |
| SQL*Net roundtrips to/from client | 클라이언트로(부터) 전송된 SQL*Net 메시지의 총 수. 다중 행 결과 집합으로부터 꺼내오기 위한 왕복을 포함한다. |
| Sorts(memory) | 사용자의 세션 메모리(정렬 영역)에서 수행된 정렬 sort_area_size 데이터베이스 매개변수에 의해 제어된다. |
| Sorts(disk) | 사용자의 정렬 영역의 크기를 초과하여 디스크(임시 테이블 영역)를 사용하는 정렬 |
| Rows processed | 수정되거나 select 문으로부터 반환된 행 |
- 강좌 URL : http://www.gurubee.net/lecture/3462
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.