press x to close
select rpad('*',2*level,'*') || ename ename
from scott.emp
start with mgr is null
connect by prior empno = mgr;
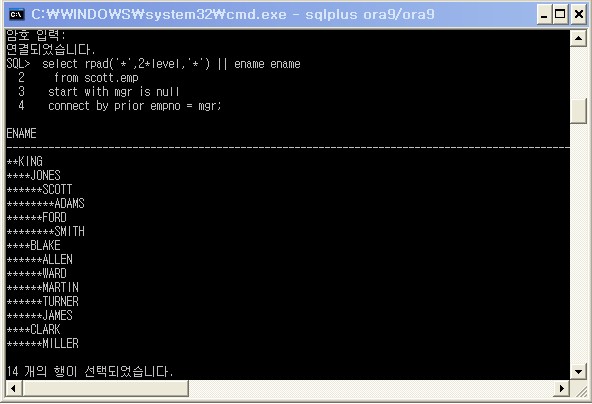
column pct_dept format 99.9;
column pct_oveall format 99.9;
break on deptno skip 1;
select deptno -- 부서 번호
,ename -- 사원 이름
,sal -- 월급
,sum(sal) over (partition by deptno order by sal, ename) cum_sal
-- 부서별 급여
,round(100*ratio_to_report(sal) over(partition by deptno),1) pct_dept
-- 종업원의 월급이 부서에서 차지하는 비율
,round(100*ratio_to_report(sal) over(), 1) pct_overall
-- 종업원의 월급이 회사 전체에서 차지하는 비율
from scott.emp
order by 1,3;
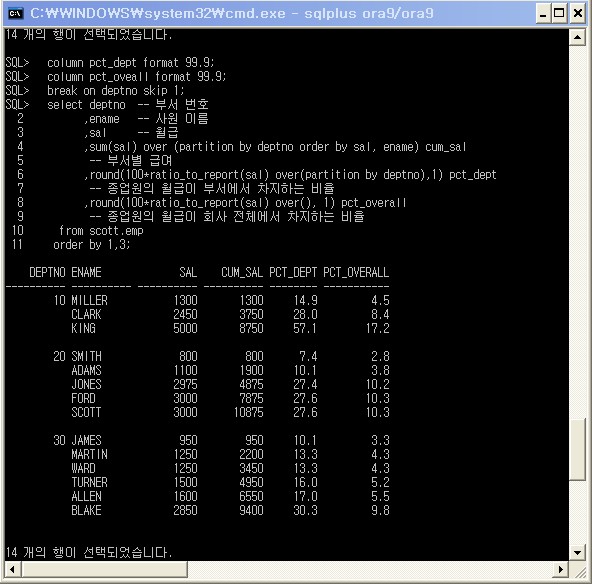
select emp1.deptno -- 부서 번호
,emp1.ename -- 사원 이름
,emp1.sal -- 월급
,sum(emp4.sal) cum_sal
-- 부서별 급여
,round(100*emp1.sal/emp2.sal_by_dept,1) pct_dept
-- 종업원의 월급이 부서에서 차지하는 비율
,round(100*emp1.sal/emp3.sal_overall,1) pct_overall
-- 종업원의 월급이 회사 전체에서 차지하는 비율
from scott.emp emp1
,( select deptno, sum(sal) sal_by_dept
from scott.emp
group by deptno ) emp2
,( select sum(sal) sal_overall
from scott.emp ) emp3
, scott.emp emp4
where emp1.deptno = emp2.deptno
and emp1.deptno = emp4.deptno
and ( emp1.sal > emp4.sal or
( emp1.sal = emp4.sal and emp1.ename >= emp4.ename ) )
group by emp1.deptno
,emp1.ename
,emp1.sal
,round(100*emp1.sal/emp2.sal_by_dept,1)
,round(100*emp1.sal/emp3.sal_overall,1)
order by 1,3;
| 테이블의 행 수 | CPU/분석 | CPU/일반 | 차이 |
|---|---|---|---|
| 2000 | 0.05 | 2.13 | 42배 |
| 4000 | 0.09 | 8.57 | 95배 |
| 8000 | 0.19 | 35.88 | 188배 |
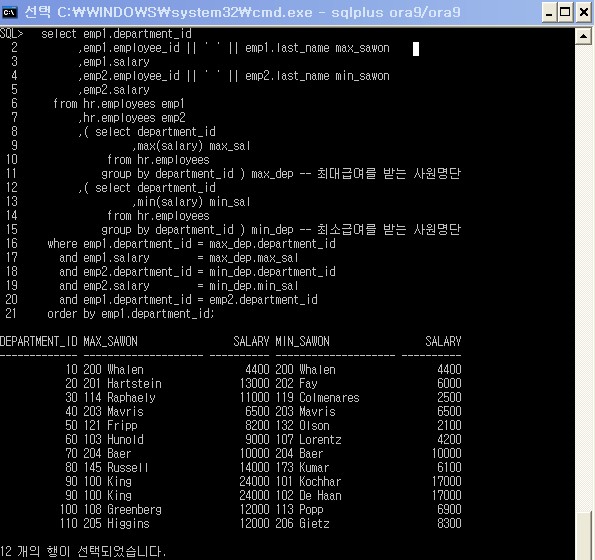
select emp1.department_id
,emp1.employee_id || ' ' || emp1.last_name max_sawon
,emp1.salary
,emp2.employee_id || ' ' || emp2.last_name min_sawon
,emp2.salary
from hr.employees emp1
,hr.employees emp2
,( select department_id
,max(salary) max_sal
from hr.employees
group by department_id ) max_dep -- 최대급여를 받는 사원명단
,( select department_id
,min(salary) min_sal
from hr.employees
group by department_id ) min_dep -- 최소급여를 받는 사원명단
where emp1.department_id = max_dep.department_id
and emp1.salary = max_dep.max_sal
and emp2.department_id = min_dep.department_id
and emp2.salary = min_dep.min_sal
and emp1.department_id = emp2.department_id
order by emp1.department_id;
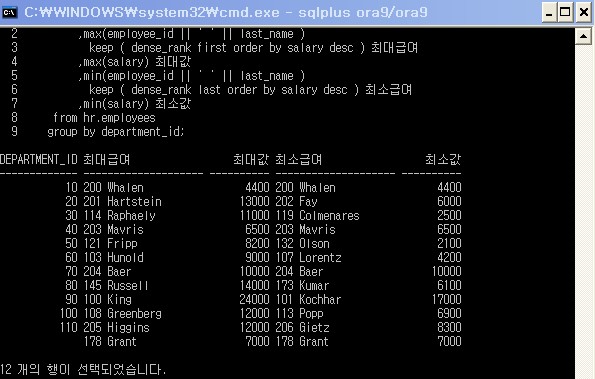
select department_id
,max(employee_id || ' ' || last_name )
keep ( dense_rank first order by salary desc ) 최대급여
,max(salary) 최대값
,min(employee_id || ' ' || last_name )
keep ( dense_rank last order by salary desc ) 최소급여
,min(salary) 최소값
from hr.employees
group by department_id;
select department_id
,max(employee_id || ' ' || last_name )
keep ( dense_rank last order by salary desc ) max_sawon
,min(employee_id || ' ' || last_name )
keep ( dense_rank last order by salary desc ) min_sawon
,min(salary)
from hr.employees
where department_id = 90
group by department_id;
create table ora9.s_emp (
empno varchar2(4) not null
, dept_no varchar2(2) not null
, salary number(10) null
)
tablespace ora9;
create table ora9.s_dept (
dept_no varchar2(2) not null
, sum_of_salary number(10) null
)
tablespace ora9;
alter table ora9.s_emp add (
constraint s_emp_pk primary key ( empno )
using index tablespace ora9 );
alter table ora9.s_dept add (
constraint s_dept_pk primary key ( dept_no )
using index tablespace ora9 );
alter table ora9.s_emp
add constraint s_dept_fk1 foreign key ( dept_no )
references ora9.s_dept ( dept_no ) ;
create index idx1
on ora9.s_emp(dept_no)
tablespace ora9;
insert into s_dept values ( '1', null );
insert into s_dept values ( '2', null );
insert into s_dept values ( '3', null );
commit;
insert into s_emp values ( '100', '1', 600 );
insert into s_emp values ( '101', '1', 800 );
insert into s_emp values ( '102', '2', 400 );
insert into s_emp values ( '103', '2', 1000 );
insert into s_emp values ( '104', '3', 1200 );
insert into s_emp values ( '105', '3', 300 );
commit;
update ora9.s_dept
set sum_of_salary = ( select sum(salary)
from ora9.s_emp
where s_emp.dept_no = s_dept.dept_no );
select *
from ora9.s_emp;
select *
from ora9.s_dept;
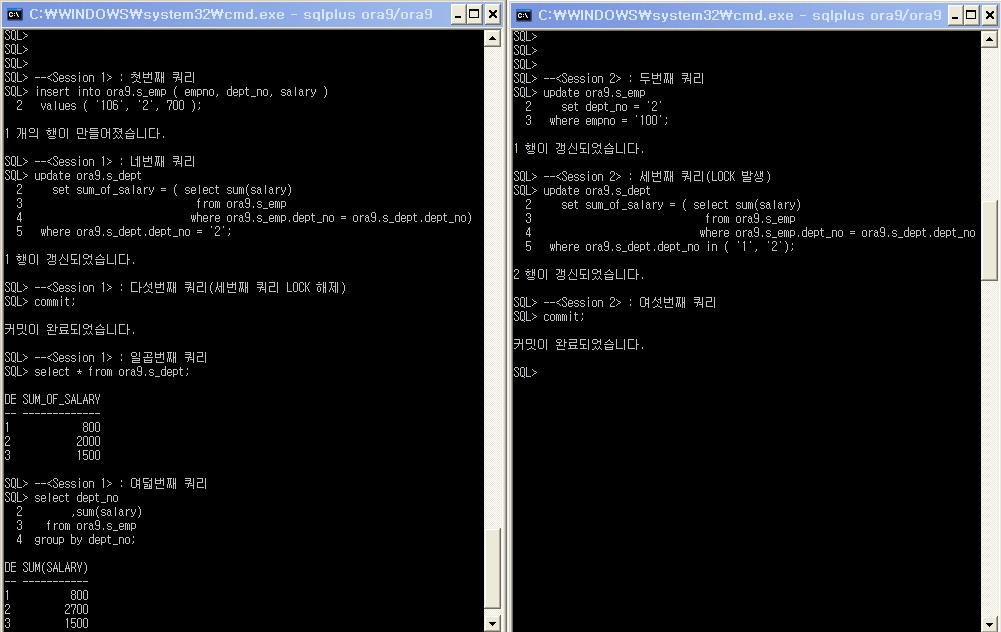
--<Session 1> : 첫번째 쿼리
insert into ora9.s_emp ( empno, dept_no, salary )
values ( '106', '2', 700 );
--<Session 2> : 두번째 쿼리
update ora9.s_emp
set dept_no = '2'
where empno = '100';
--<Session 2> : 세번째 쿼리(LOCK 발생)
update ora9.s_dept
set sum_of_salary = ( select sum(salary)
from ora9.s_emp
where ora9.s_emp.dept_no = ora9.s_dept.dept_no )
where ora9.s_dept.dept_no in ( '1', '2');
--<Session 1> : 네번째 쿼리
update ora9.s_dept
set sum_of_salary = ( select sum(salary)
from ora9.s_emp
where ora9.s_emp.dept_no = ora9.s_dept.dept_no)
where ora9.s_dept.dept_no = '2';
--<Session 1> : 다섯번째 쿼리(세번째 쿼리 LOCK 해제)
commit;
--<Session 2> : 여섯번째 쿼리
commit;
--<Session 1> : 일곱번째 쿼리
select * from ora9.s_dept;
--<Session 1> : 여덟번째 쿼리
select dept_no
,sum(salary)
from ora9.s_emp
group by dept_no;
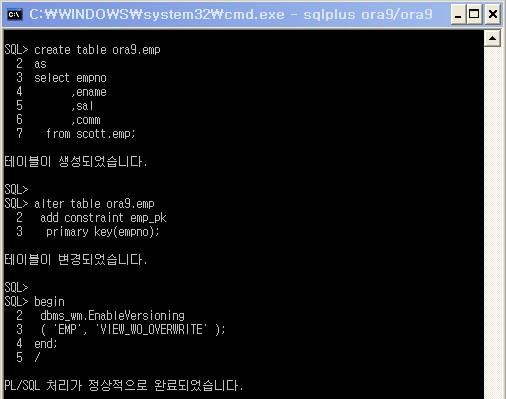
create table ora9.emp
as
select empno
,ename
,sal
,comm
from scott.emp;
alter table ora9.emp
add constraint emp_pk
primary key(empno);
begin
dbms_wm.EnableVersioning
( 'EMP', 'VIEW_WO_OVERWRITE' );
end;
/
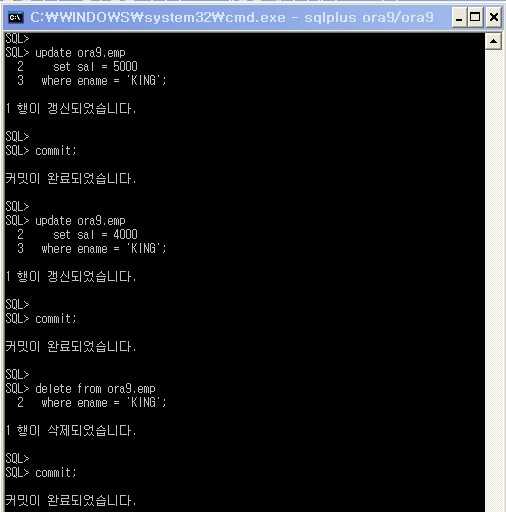
update ora9.emp
set sal = 5000
where ename = 'KING';
commit;
update ora9.emp
set sal = 4000
where ename = 'KING';
commit;
delete from ora9.emp
where ename = 'KING';
commit;
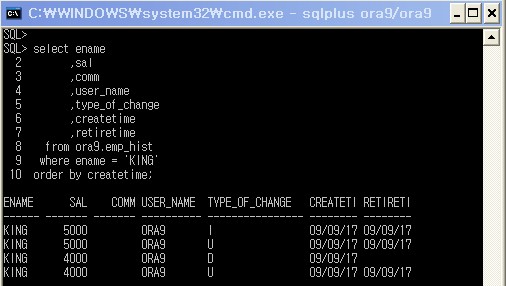
select ename
,sal
,comm
,user_name
,type_of_change
,createtime
,retiretime
from ora9.emp_hist
where ename = 'KING'
order by createtime;
- 강좌 URL : http://www.gurubee.net/lecture/3448
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.