04. 테이블 Random 액세스 부하
(1) 인덱스 ROWID에 의한 테이블 액세스
-인덱스 스캔후 Random 액세스 발생하고 실행계획중 "Table Access By lndex ROWID" 표시
물리적 주소? 논리적 주소?
- 인덱스에 저장된 rowid 는 "물리적 주소"
cf. 논리적 주소 : rowid 가 물리적 주소로 구성되지만 인덱스에서 데이터로 직접 연결되는 구조는 아님.
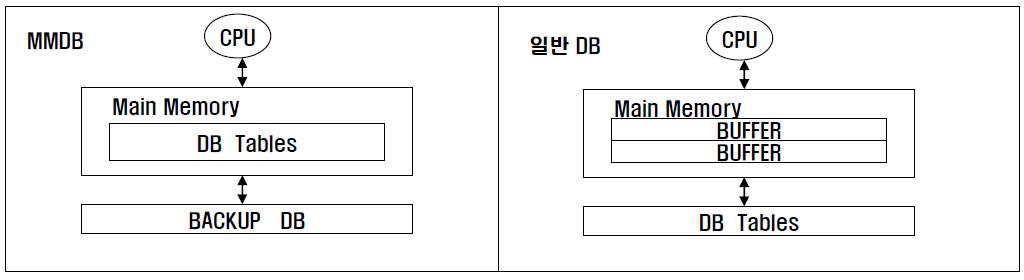
메인 메모리 DB와의 비교
- 메인 메모리 DB 는 인스턴스를 기동하면 디스크에 저장된 데이터를 버퍼캐시로 로딩하고, 인덱스를 실시간으로 만든다.
이때 인덱스는 메모리상의 주소정보(포이터)를 담는다.
메모리상의 데이터를 찾아가는데는 포인터만큼 빠른 방법은 없으면 그 비용은 0에 가까워 인덱스 경유해 테이블에 액세스 하는 데 비용이 낮다 - 오라클은 데이터 블록이 수시로 버퍼캐시에 밀려났다가 다시 캐싱되어 직접 포인터로 연결할수 없음
디스크 상의 블록위치를 해싱 알고리즘을 통한 해시값으로 버퍼블록을 찾는다 - 메인 메모리 DB 는 데이터볼륨이 크지 않으며, 빠른 트랜잭션 처리가 요구되는 업무에만 제한적으로 사용해야 함.
rowid는 우편주소에 해당
- 오라클에서 rowid : 우편번호, 메인메모리 DB 포인터 : 전화번호
인텍스 rowid에 의한 테이블 액세스 구조
- 인덱스 rowid 는 테이블 레코드와 물리적으로 연결돼 있지 않기 때문에 인덱스를 통한 테이블 액세스는 고비용구조
- DBA 해싱, 래치획득 반복하며, 액세스가 심할 경우는 래치과 버퍼 Lock 에 대한 경합까지 발생함.
(2) 인덱스 클러스터링 팩터
군집성 계수(= 데이터가 모여 있는 정도)
- 클러스터링 팩터 (Clustering Factor, CF = '군집성 계수') : 특정 컬럼을 기준으로 같은 값을 갖는 데이터가 서로 모여있는 정도를 의미
- CF가 좋은 컬럼에 생성한 인텍스는 검색 효율이 매우 좋음, 데이터가 물리적으로 근접해 있다면 흩어져 있을 때보다 데이터를 찾는 속도가 향상
클러스터링 팩터조회
select i.index_name, t.blocks table_blocks, i.num_rows, i.clustering_factor
from user_tables t , user_indexes i
where t.table_name = 'XXXXXX'
and i.table_name = t.table_name;
INDEX_NAME TABLE_BLOCKS NUM_ROWS CLUSTERING_FACTOR
------------------------------ ------------------------ ---------------- ----------------------------------
IX_XXXXXX_COUNT_CHARGE_PRSN 2040 75918 18870
IX_XXXXXX 2040 75920 47723
IX_XXXXXX_CONT_YEARMON 2040 75920 8951
- clustering_factor 가 테이블 블록(table_blocks)에 가까울수록 데이터가 잘 정 렬돼 있음을, 레코드 개수(num_rows)에 가까울수록 흩어져 있음을 의미
1) counter 변수 선언
2) 인덱스 리프 블록을 처음부터 끝까지 스캔하면서 인텍스 rowid로부터 블록 번호를 취한다.
3) 현재 읽고 있는 인덱스 레코드의 블록 번호가 바로 직전에 읽은 레묘드의 블록 번호와 다를때마다 counter 변수 값을 1씩 증가
4) 스캔을 완료하고서,최종 counter 변수 값을 clustering_factor 로서 인덱스 통계에 저장
인덱스 이용한 테이블 액세스 비용을 계산하기 위해 오라클이 시용하는 공식
비용 = blevel -- 인덱스 수직적 탐색 비용
+ (리프 블록 수 × 유효 인덱스 선택도) -- 인덱스 수평적 탐색 비용
+ (클러스터링 팩터 × 유효 테이블 선택도) -- 테이블 Random 액세스 비용
- blevel : 리프 블록에 도달하기 전 읽게 될 브랜치 블록 개수
- 유효 인덱스 선택도 : 전체 인덱스 레코드 중에서 조건절을 만족하는 레코드를 찾기 위해 스캔할 것으로 예상되는 비율(%)
- 유효 테이블 선택도 : 전체 레코드 중에서 인덱스 스캔을 완료하고서 최종적으로 테이블을방문할 것으로 예상되는 비율(%)
클러스터링 팩터와 물리적 I/O
- '인덱스 CF가 좋다' : 인덱스 정렬 순서와 태이블 정렬 순서가 서로 비슷 의미
- 인덱스 레코드는 항상 100% 정렬된 상태를 유지하는데, 테이블 레코드도 이와 비슷한 정렬순서를 갖는다면 값이 같은 레코드들이 서로 군집해 있음
- 물리적인 디스크 I/O 횟수를 감소
- 오라클에서 I/O는 블록 단위로 이루어지므로 인덱스를 통해 하나의 레코드를 읽으면 같은 블록에 속한 다른 레코드들도 함께 캐싱되어, 그 레코드들도 가까운 시점에 읽힐 가능성이 높음
- 인덱스를 스캔하면서 읽는 테이블 블록들의 캐시 히트율이 높아지므로 물리적인 디스크 I/0 횟수가 감소
- CF 나쁘다 :
- 값이 같은 레코드이 서로 멀리 떨어져 있다면 논리적으로 더 많은 블록을 읽어야 하므로 물리적인 디스크 I/O 횟수도 같이 증가
- 앞서 읽었던 테이블 블록을 다시 방문하고자 할 때 이미 캐시에서 밀려나고 없다면 같은 블록을 디스크에서 여러 번 읽게 되므로 I/O 효율은 더 나빠짐
클러스터링 팩터와 논리적 I/O
- 인덱스 CF는 인덱스를 경유해 테이블 전체 로우를 액세스할 때 읽을 것으로 예상되는 논리적인 블록 개수를 의미
CF가 가장 좋을 때는 인덱스 통계에 나타나는 clustering_factor가 전체 테이블 블록 개수와 일치, 하고,가장 안 좋을 때는 총 레코드 개수와 일치(모든 블록에 레코드가 하나씩만 저장돼 있다면 clustering_factor 는 항상 총 레코드 개수와 일치 )
물리적 I/O 계산을 위해 논리적 I/O 를 측정
오라클은 인덱스가 가리키는 데이터의 흩어짐 정도를 인덱스 비용 계산식에 표현하기 위해 CF를 고안
옵티마이저가 사용하는 비용 계산식은 기본적으로 물리적인 I/O 만을 고려(논리적 I/0가 모두 물리적 I/0를 수반한다고 가정)하므로 CF도 궁극적으로 물리적 I/0 비용을 평가하기 위한 수단
논리적 I/0 가 100% 물리적 I/0 를 수반한다는 가정은 매우 비현실적, 앞서 읽었던 테이블 블록을 다시 읽을 때 실제로는 캐싱된 블록을 읽을 가능성이 훨씬 높다.
한번 읽었던 테이블 블록이 벼퍼 캐시에서 밀려나지 않도록 충분한 버퍼 캐시를 확보한 상태에서 인덱스를 통해 전체 테이블 레코드를 읽는 경우를 가정
해 보자. 그러면 위에서 본 t_object_name_idx 인덱스의 clustering_factor 수치(24,936}는 실제 발생할 수 있는 물리적 I/0 횟수와 전혀 동떨어진 값이 되고 만다.
물리적으로 읽어야 할 전체 테이블 블록 개수는 고정(앞선 예에서는 709개)돼 있기 때문이다.
그럼에도 캐싱 효과를 예측하기가 매우 어렵기 때문에 옵티마이저는 CF를 통해 계산된 논리적 I/0 횟수를 그대로 물리적 I/0 횟수로 인정하고 인덱스 비용을 평가하는 것이다.
결론적으로 말해, 인덱스 통계에서 볼 수 있는 clustering_factor는 인덱스를 통해 테이블을 액세스할 때 예상되는 논리적 I/O 개수를 더 정확히 표현하고 있다.
 |
버퍼 Pinning에 의한 논리적 I/O 감소 원리
- 똑같은 개수의 레코드를 읽는데 인덱스 CF에 따라 논리적인 블록 I/O 개수 차이 나는 이유는 테이블 버퍼 블록을 Pinning하기 때문
- 연속된 인덱스 레코드가 같은 블록을 가리킨다면,래치 획득 과정을 생략하고 버퍼를 Pin한 상태에서 읽기 때문에 논리적인 블록 읽기 (Logical Reads) 횟수가 증가
(3) 인덱스 손익분기점
- 손익 분기점 : Index Range Scan에 의한 테이블 액세스가 Table Full Scan보다 느려지는 지점
- 인덱스에 의한 액세스가 Full Table Scan보다 더 느려지게 만드는 가장 핵심적인 두 가지 요인
1) 인덱스 rowid 에 의한 테이블 액세스는 Random 액세스인 반면, Full Table Scan은 Sequential 액세스 방식
2) 디스크 I/O 시, 인덱스 rowid에 의한 테이블 액세스는 Single Block Read 방식을 사용하는 반면, Full Table Scan은 Multiblock Read 방식
- 인덱스 손익분기점은 데이터 상황에 따라 달라지므로 정해진 수치 또는 범위를 정해 놓고 인덱스의 효용성을 판단하기 어려움
- 인덱스가 항상 좋을 수 없음을 설명하려고 도입한 개념일 뿐 이를 높이기 위해 어떤 조치를 취하라는 것은 아니다. 즉 테이블 스캔이 항상 나쁜 것은 아니며 바꿔 말해, 인덱스 스캔이 항상 좋은 것도 아니라는 사실을 인식시키기 위함
손익분기점을 극복하기 위한 기능들
- IOT(Index-Organized Table)
- 클러스터 테이블(Clustered Table) : 키 값이 같은 레코드는 같은 블록에 모이도록 저장
- 파티셔닝이
- 강좌 URL : http://www.gurubee.net/lecture/3332
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.