press x to close
SQL> CREATE TABLE 고객
2 AS
3 SELECT ROWNUM 고객ID
4 , DBMS_RANDOM.STRING('U', 10) 고객명
5 , MOD(ROWNUM, 10) + 1 고객등급
6 , TO_CHAR(TO_DATE('20090101', 'yyyymmdd') + (ROWNUM-1), 'yyyymmdd') 가입일
7 FROM dual
8 CONNECT BY LEVEL <= 1000
9 ;
테이블이 생성되었습니다.
SQL> exec dbms_stats.gather_table_stats(user, '고객');
PL/SQL 처리가 정상적으로 완료되었습니다.
SQL> set autot traceonly exp
SQL> SELECT /*+ full(고객) parallel(고객 2) */
2 고객ID, 고객명, 고객등급
3 FROM 고객
4 ORDER BY 고객명
5 ;
Execution Plan
----------------------------------------------------------
Plan hash value: 2364220803
-----------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | TQ |IN-OUT| PQ Distrib |
-----------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1000 | 18000 | 3 (34)| 00:00:01 | | | |
| 1 | PX COORDINATOR | | | | | | | | |
| 2 | PX SEND QC (ORDER) | :TQ10001 | 1000 | 18000 | 3 (34)| 00:00:01 | Q1,01 | P->S | QC (ORDER) |
| 3 | SORT ORDER BY | | 1000 | 18000 | 3 (34)| 00:00:01 | Q1,01 | PCWP | |
| 4 | PX RECEIVE | | 1000 | 18000 | 2 (0)| 00:00:01 | Q1,01 | PCWP | |
| 5 | PX SEND RANGE | :TQ10000 | 1000 | 18000 | 2 (0)| 00:00:01 | Q1,00 | P->P | RANGE |
| 6 | PX BLOCK ITERATOR | | 1000 | 18000 | 2 (0)| 00:00:01 | Q1,00 | PCWC | |
| 7 | TABLE ACCESS FULL| 고객 | 1000 | 18000 | 2 (0)| 00:00:01 | Q1,00 | PCWP | |
-----------------------------------------------------------------------------------------------------------------
SQL> set autot off
SQL> /
...
1000 개의 행이 선택되었습니다.
SQL> break on dfo_no on tq_id on server_type
SQL> SELECT tq_id
2 , server_type
3 , process
4 , num_rows
5 , bytes
6 , waits
7 FROM v$pq_tqstat
8 ORDER BY dfo_number
9 , tq_id
10 , DEcode(SUBSTR(server_type, 1, 4), 'Rang', 1, 'Prod', 2, 'Cons', 3)
11 , process
12 ;
TQ_ID SERVER_TYPE PROCESS NUM_ROWS BYTES WAITS
---------- -------------------- -------------------- ---------- ---------- ----------
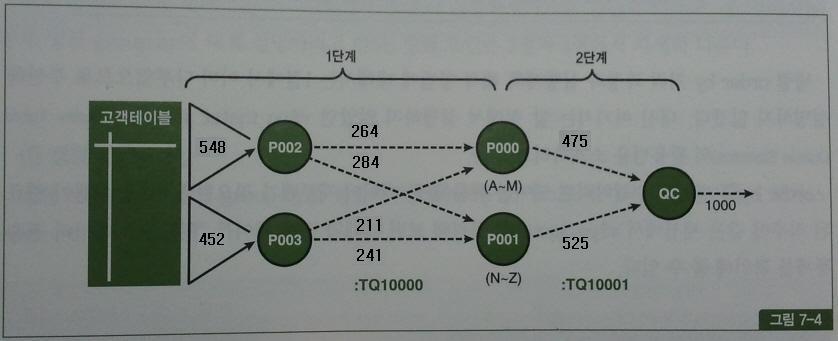
0 Ranger QC 182 7604 0
Producer P002 548 11608 4
P003 452 9691 3
Consumer P000 475 10068 5
P001 525 11141 6
1 Producer P000 475 10065 0
P001 525 11114 0
Consumer QC 1000 21179 1
8 개의 행이 선택되었습니다.
 |
SQL> set autot traceonly exp
SQL> SELECT /*+ full(고객) parallel(고객 2) */
2 고객명, COUNT(*) cnt
3 FROM 고객
4 GROUP BY 고객명
5 ;
Execution Plan
----------------------------------------------------------
Plan hash value: 3413408456
-----------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | TQ |IN-OUT| PQ Distrib |
-----------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1000 | 11000 | 3 (34)| 00:00:01 | | | |
| 1 | PX COORDINATOR | | | | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10001 | 1000 | 11000 | 3 (34)| 00:00:01 | Q1,01 | P->S | QC (RAND) |
| 3 | HASH GROUP BY | | 1000 | 11000 | 3 (34)| 00:00:01 | Q1,01 | PCWP | |
| 4 | PX RECEIVE | | 1000 | 11000 | 2 (0)| 00:00:01 | Q1,01 | PCWP | |
| 5 | PX SEND HASH | :TQ10000 | 1000 | 11000 | 2 (0)| 00:00:01 | Q1,00 | P->P | HASH |
| 6 | PX BLOCK ITERATOR | | 1000 | 11000 | 2 (0)| 00:00:01 | Q1,00 | PCWC | |
| 7 | TABLE ACCESS FULL| 고객 | 1000 | 11000 | 2 (0)| 00:00:01 | Q1,00 | PCWP | |
-----------------------------------------------------------------------------------------------------------------
SQL> set autot off
SQL> -- Hash Group By 쿼리 실행--
SQL> /
...
1000 개의 행이 선택되었습니다.
SQL> break on dfo_no on tq_id on server_type
SQL> SELECT tq_id
2 , server_type
3 , process
4 , num_rows
5 , bytes
6 , waits
7 FROM v$pq_tqstat
8 ORDER BY dfo_number
9 , tq_id
10 , DEcode(SUBSTR(server_type, 1, 4), 'Rang', 1, 'Prod', 2, 'Cons', 3)
11 , process
12 ;
TQ_ID SERVER_TYPE PROCESS NUM_ROWS BYTES WAITS
---------- -------------------- -------------------- ---------- ---------- ----------
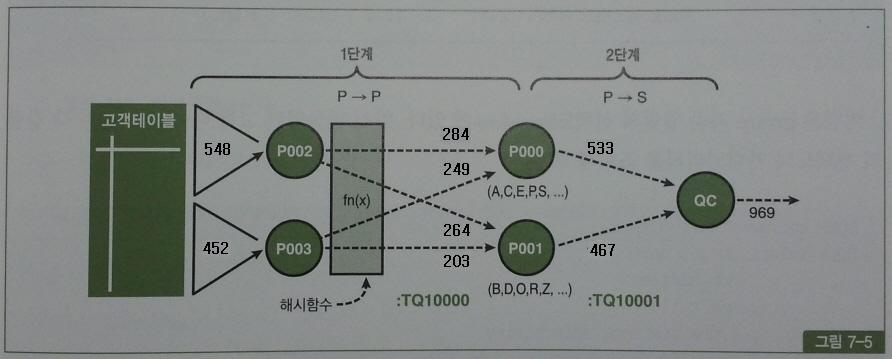
0 Producer P002 548 6672 3
P003 452 5520 2
Consumer P000 533 6492 81
P001 467 5700 80
1 Producer P000 533 8648 4
P001 467 7568 2
Consumer QC 1000 16216 3
7 개의 행이 선택되었습니다.
 |
SQL> SELECT /*+ full(고객) parallel(고객 2) */
2 고객명, COUNT(*) cnt
3 FROM 고객
4 GROUP BY 고객명
5 ORDER BY 고객명
6 ;
Execution Plan
----------------------------------------------------------
Plan hash value: 3764717107
-----------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | TQ |IN-OUT| PQ Distrib |
-----------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1000 | 11000 | 3 (34)| 00:00:01 | | | |
| 1 | PX COORDINATOR | | | | | | | | |
| 2 | PX SEND QC (ORDER) | :TQ10001 | 1000 | 11000 | 3 (34)| 00:00:01 | Q1,01 | P->S | QC (ORDER) |
| 3 | SORT GROUP BY | | 1000 | 11000 | 3 (34)| 00:00:01 | Q1,01 | PCWP | |
| 4 | PX RECEIVE | | 1000 | 11000 | 2 (0)| 00:00:01 | Q1,01 | PCWP | |
| 5 | PX SEND RANGE | :TQ10000 | 1000 | 11000 | 2 (0)| 00:00:01 | Q1,00 | P->P | RANGE |
| 6 | PX BLOCK ITERATOR | | 1000 | 11000 | 2 (0)| 00:00:01 | Q1,00 | PCWC | |
| 7 | TABLE ACCESS FULL| 고객 | 1000 | 11000 | 2 (0)| 00:00:01 | Q1,00 | PCWP | |
-----------------------------------------------------------------------------------------------------------------
SQL> -- Sort Group By 쿼리 실행--
SQL> /
...
1000 개의 행이 선택되었습니다.
SQL>
SQL> break on dfo_no on tq_id on server_type
SQL> SELECT tq_id
2 , server_type
3 , process
4 , num_rows
5 , bytes
6 , waits
7 FROM v$pq_tqstat
8 ORDER BY dfo_number
9 , tq_id
10 , DEcode(SUBSTR(server_type, 1, 4), 'Rang', 1, 'Prod', 2, 'Cons', 3)
11 , process
12 ;
TQ_ID SERVER_TYPE PROCESS NUM_ROWS BYTES WAITS
---------- -------------------- -------------------- ---------- ---------- ----------
0 Ranger QC 182 4494 1
Producer P002 548 6732 5
P003 452 5580 3
Consumer P000 475 5823 5
P001 525 6423 5
1 Producer P000 475 7720 0
P001 525 8520 0
Consumer QC 1000 16240 1
8 개의 행이 선택되었습니다.
SQL> set autot traceonly exp
SQL> SELECT /*+ full(고객) parallel(고객 2) */
2 고객등급, COUNT(*) cnt
3 FROM 고객
4 GROUP BY 고객등급
5 ;
Execution Plan
----------------------------------------------------------
Plan hash value: 406695692
------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | TQ |IN-OUT| PQ Distrib |
------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 10 | 30 | 3 (34)| 00:00:01 | | | |
| 1 | PX COORDINATOR | | | | | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10001 | 10 | 30 | 3 (34)| 00:00:01 | Q1,01 | P->S| QC (RAND) |
| 3 | HASH GROUP BY | | 10 | 30 | 3 (34)| 00:00:01 | Q1,01 | PCWP| |
| 4 | PX RECEIVE | | 10 | 30 | 3 (34)| 00:00:01 | Q1,01 | PCWP| |
| 5 | PX SEND HASH | :TQ10000 | 10 | 30 | 3 (34)| 00:00:01 | Q1,00 | P->P| HASH |
| 6 | HASH GROUP BY | | 10 | 30 | 3 (34)| 00:00:01 | Q1,00 | PCWP| |
| 7 | PX BLOCK ITERATOR | | 1000 | 3000 | 2 (0)| 00:00:01 | Q1,00 | PCWC| |
| 8 | TABLE ACCESS FULL| 고객 | 1000 | 3000 | 2 (0)| 00:00:01 | Q1,00 | PCWP| |
------------------------------------------------------------------------------------------------------------------
SQL> set autot off
SQL> /
고객등급 CNT
---------- ----------
6 100
5 100
1 100
3 100
4 100
7 100
8 100
2 100
9 100
10 100
10 개의 행이 선택되었습니다.
SQL> break on dfo_no on tq_id on server_type
SQL> SELECT tq_id
2 , server_type
3 , process
4 , num_rows
5 , bytes
6 , waits
7 FROM v$pq_tqstat
8 ORDER BY dfo_number
9 , tq_id
10 , DEcode(SUBSTR(server_type, 1, 4), 'Rang', 1, 'Prod', 2, 'Cons', 3)
11 , process
12 ;
TQ_ID SERVER_TYPE PROCESS NUM_ROWS BYTES WAITS
---------- -------------------- -------------------- ---------- ---------- ----------
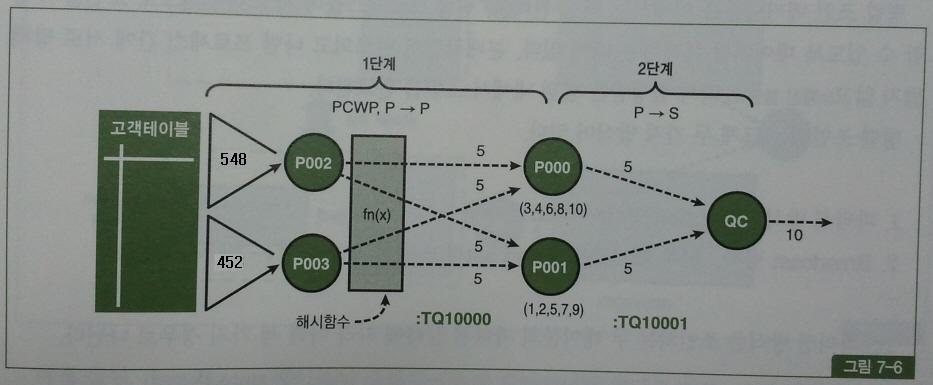
0 Producer P002 10 208 0
P003 10 208 0
Consumer P000 10 208 4
P001 10 208 3
1 Producer P000 5 64 3
P001 5 64 3
Consumer QC 10 128 3
7 개의 행이 선택되었습니다.
SQL> SELECT column_name
2 , num_distinct
3 , num_nulls
4 , 1/num_distinct selectivity
5 , ROUND(1/num_distinct * t.num_rows, 2) cardinality
6 FROM user_tables t
7 , user_tab_columns c
8 WHERE t.table_name = '고객'
9 AND c.table_name = t.table_name
10 ORDER BY column_id
11 ;
COLUMN_NAME NUM_DISTINCT NUM_NULLS SELECTIVITY CARDINALITY
------------------------------ ------------ ---------- ----------- -----------
고객ID 1000 0 .001 1
고객명 1000 0 .001 1
고객등급 10 0 .1 100
가입일 1000 0 .001 1
 |
- 강좌 URL : http://www.gurubee.net/lecture/3310
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.