press x to close
SQL> SELECT DISTINCT empno FROM emp;
Execution Plan
----------------------------------------------------------
Plan hash value: 179099197
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 14 | 56 | 1 (0)| 00:00:01 |
| 1 | INDEX FULL SCAN | PK_EMP | 14 | 56 | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------
SQL> SELECT DISTINCT empno FROM emp ORDER BY empno;
Execution Plan
----------------------------------------------------------
Plan hash value: 179099197
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 14 | 56 | 1 (0)| 00:00:01 |
| 1 | INDEX FULL SCAN | PK_EMP | 14 | 56 | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------
SQL> CREATE TABLE emp1 AS SELECT * FROM emp;
테이블이 생성되었습니다.
SQL> CREATE INDEX idx_emp1 ON emp1(empno);
인덱스가 생성되었습니다.
SQL> SELECT DISTINCT empno FROM emp1;
Execution Plan
----------------------------------------------------------
Plan hash value: 3282348538
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 14 | 182 | 4 (25)| 00:00:01 |
| 1 | HASH UNIQUE | | 14 | 182 | 4 (25)| 00:00:01 |
| 2 | TABLE ACCESS FULL| EMP1 | 14 | 182 | 3 (0)| 00:00:01 |
---------------------------------------------------------------------------
Note
-----
- dynamic sampling used for this statement (level=2)
SQL> SELECT DISTINCT empno FROM emp1 ORDER BY empno;
Execution Plan
----------------------------------------------------------
Plan hash value: 2849225206
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 14 | 182 | 5 (40)| 00:00:01 |
| 1 | SORT UNIQUE | | 14 | 182 | 4 (25)| 00:00:01 |
| 2 | TABLE ACCESS FULL| EMP1 | 14 | 182 | 3 (0)| 00:00:01 |
---------------------------------------------------------------------------
Note
-----
- dynamic sampling used for this statement (level=2)
SQL> CREATE TABLE customer
2 AS
3 SELECT LEVEL custid
4 , CHR(64 + CEIL(LEVEL / 100)) region
5 , dbms_random.string('U', 4) name
6 , ROUND(dbms_random.value(10, 70)) age
7 FROM dual
8 CONNECT BY LEVEL <= 1000
9 ;
테이블이 생성되었습니다.
SQL> CREATE INDEX customer_x01 ON customer(region);
인덱스가 생성되었습니다.
SQL> SELECT *
2 FROM customer
3 WHERE region = 'A'
4 ORDER BY custid
5 ;
Execution Plan
----------------------------------------------------------
Plan hash value: 3806818772
--------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time
--------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 100 | 198K| 3 (34)| 00:00:01
| 1 | SORT ORDER BY | | 100 | 198K| 3 (34)| 00:00:01
| 2 | TABLE ACCESS BY INDEX ROWID| CUSTOMER | 100 | 198K| 2 (0)| 00:00:01
|* 3 | INDEX RANGE SCAN | CUSTOMER_X01 | 100 | | 1 (0)| 00:00:01
--------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("REGION"='A')
Note
-----
- dynamic sampling used for this statement (level=2)
SQL> CREATE INDEX customer_x02 ON customer(region, custid);
인덱스가 생성되었습니다.
SQL> SELECT *
2 FROM customer
3 WHERE region = 'A'
4 ORDER BY custid
5 ;
Execution Plan
----------------------------------------------------------
Plan hash value: 2477059019
--------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 100 | 198K| 3 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| CUSTOMER | 100 | 198K| 3 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | CUSTOMER_X02 | 100 | | 2 (0)| 00:00:01 |
--------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("REGION"='A')
Note
-----
- dynamic sampling used for this statement (level=2)
SQL>
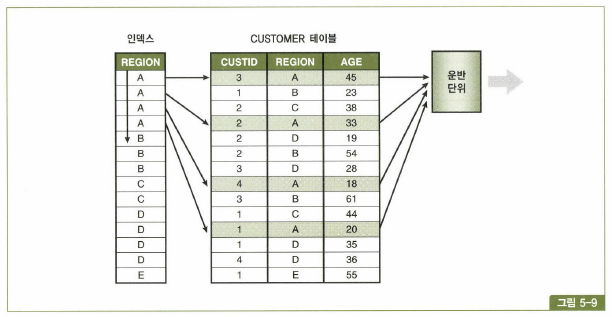 |
SQL> SELECT region
2 , AVG(age) age
3 , COUNT(*) cnt
4 FROM customer
5 GROUP BY region
6 ;
Execution Plan
----------------------------------------------------------
Plan hash value: 3656427734
-------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1000 | 16000 | 4 (25)| 00:00:01 |
| 1 | HASH GROUP BY | | 1000 | 16000 | 4 (25)| 00:00:01 |
| 2 | TABLE ACCESS FULL| CUSTOMER | 1000 | 16000 | 3 (0)| 00:00:01 |
-------------------------------------------------------------------------------
Note
-----
- dynamic sampling used for this statement (level=2)
SQL> SELECT region
2 , AVG(age) age
3 , COUNT(*) cnt
4 FROM customer
5 GROUP BY region
6 ORDER BY region
7 ;
Execution Plan
----------------------------------------------------------
Plan hash value: 3481805491
-------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1000 | 16000 | 4 (25)| 00:00:01 |
| 1 | SORT GROUP BY | | 1000 | 16000 | 4 (25)| 00:00:01 |
| 2 | TABLE ACCESS FULL| CUSTOMER | 1000 | 16000 | 3 (0)| 00:00:01 |
-------------------------------------------------------------------------------
Note
-----
- dynamic sampling used for this statement (level=2)
SQL> SELECT region
2 , AVG(age) age
3 , COUNT(*) cnt
4 FROM customer
5 WHERE region IS NOT NULL
6 GROUP BY region
7 ;
Execution Plan
----------------------------------------------------------
Plan hash value: 3656427734
-------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1000 | 16000 | 4 (25)| 00:00:01 |
| 1 | HASH GROUP BY | | 1000 | 16000 | 4 (25)| 00:00:01 |
|* 2 | TABLE ACCESS FULL| CUSTOMER | 1000 | 16000 | 3 (0)| 00:00:01 |
-------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("REGION" IS NOT NULL)
Note
-----
- dynamic sampling used for this statement (level=2)
SQL> SELECT region
2 , AVG(age) age
3 , COUNT(*) cnt
4 FROM customer
5 WHERE region IS NOT NULL
6 GROUP BY region
7 ORDER BY region
8 ;
Execution Plan
----------------------------------------------------------
Plan hash value: 3481805491
-------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1000 | 16000 | 4 (25)| 00:00:01 |
| 1 | SORT GROUP BY | | 1000 | 16000 | 4 (25)| 00:00:01 |
|* 2 | TABLE ACCESS FULL| CUSTOMER | 1000 | 16000 | 3 (0)| 00:00:01 |
-------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("REGION" IS NOT NULL)
Note
-----
- dynamic sampling used for this statement (level=2)
SQL> SELECT /*+ first_rows(10) */ region
2 , AVG(age) age
3 , COUNT(*) cnt
4 FROM customer
5 WHERE region IS NOT NULL
6 GROUP BY region
7 ;
Execution Plan
----------------------------------------------------------
Plan hash value: 89828339
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1000 | 16000 | 3 (0)| 00:00:01 |
| 1 | SORT GROUP BY NOSORT | | 1000 | 16000 | 3 (0)| 00:00:01 |
| 2 | TABLE ACCESS BY INDEX ROWID| CUSTOMER | 1000 | 16000 | 3 (0)| 00:00:01 |
|* 3 | INDEX FULL SCAN | CUSTOMER_X02 | 1 | | 2 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter("REGION" IS NOT NULL)
Note
-----
- dynamic sampling used for this statement (level=2)
SQL> CREATE INDEX emp_deptno_ename_idx ON emp(deptno, ename);
인덱스가 생성되었습니다.
SQL> SELECT *
2 FROM emp
3 WHERE deptno = 30
4 ORDER BY ename
5 ;
Execution Plan
----------------------------------------------------------
Plan hash value: 3268462453
----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 5 | 190 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 5 | 190 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | EMP_DEPTNO_ENAME_IDX | 5 | | 1 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("DEPTNO"=30)
SQL> SELECT *
2 FROM emp
3 WHERE deptno = 30
4 ORDER BY ename NULLS FIRST
5 ;
Execution Plan
----------------------------------------------------------
Plan hash value: 4293037890
-----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 5 | 190 | 3 (34)| 00:00:01 |
| 1 | SORT ORDER BY | | 5 | 190 | 3 (34)| 00:00:01 |
| 2 | TABLE ACCESS BY INDEX ROWID| EMP | 5 | 190 | 2 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | EMP_DEPTNO_ENAME_IDX | 5 | | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("DEPTNO"=30)
SQL> SELECT *
2 FROM emp
3 WHERE deptno = 30
4 ORDER BY ename NULLS LAST
5 ;
Execution Plan
----------------------------------------------------------
Plan hash value: 3268462453
----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 5 | 190 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 5 | 190 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | EMP_DEPTNO_ENAME_IDX | 5 | | 1 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("DEPTNO"=30)
SQL> SELECT *
2 FROM emp
3 WHERE deptno = 30
4 ORDER BY ename DESC
5 ;
Execution Plan
----------------------------------------------------------
Plan hash value: 3122309019
-----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 5 | 190 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID | EMP | 5 | 190 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN DESCENDING| EMP_DEPTNO_ENAME_IDX | 5 | | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("DEPTNO"=30)
SQL> SELECT *
2 FROM emp
3 WHERE deptno = 30
4 ORDER BY ename DESC NULLS LAST
5 ;
Execution Plan
----------------------------------------------------------
Plan hash value: 4293037890
-----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 5 | 190 | 3 (34)| 00:00:01 |
| 1 | SORT ORDER BY | | 5 | 190 | 3 (34)| 00:00:01 |
| 2 | TABLE ACCESS BY INDEX ROWID| EMP | 5 | 190 | 2 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | EMP_DEPTNO_ENAME_IDX | 5 | | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("DEPTNO"=30)
- 강좌 URL : http://www.gurubee.net/lecture/3301
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.