press x to close
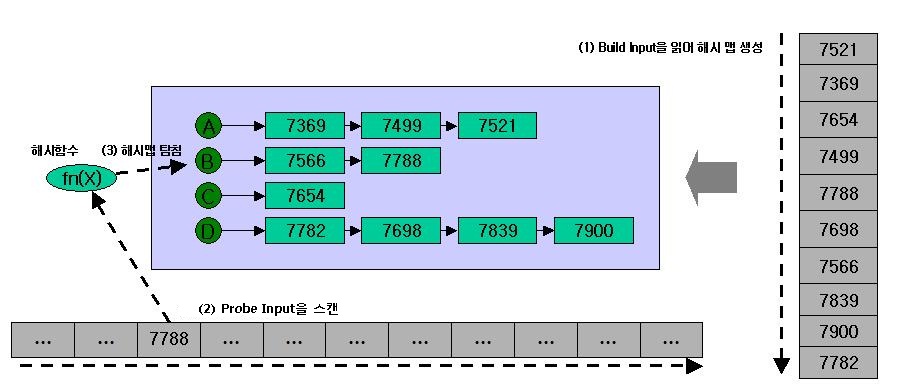 |
select /*+ use_hash(d e) */ => 통계정보를 근거로, 옵티마이저가 Build Input을 선택하여 Hash Join 하라!
d.deptno, d.dname, e.empno, e.ename
from dept d, emp e
where d.deptno = e.deptno
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
Plan hash value: 615168685
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 14 | 364 | 7 (15)| 00:00:01 |
|* 1 | HASH JOIN | | 14 | 364 | 7 (15)| 00:00:01 |
| 2 | TABLE ACCESS FULL| DEPT | 4 | 52 | 3 (0)| 00:00:01 | => Build Input
| 3 | TABLE ACCESS FULL| EMP | 14 | 182 | 3 (0)| 00:00:01 | => Probe Input
---------------------------------------------------------------------------
select /*+ use_hash(d e) swap_join_inputs(e) */
d.deptno, d.dname, e.empno, e.ename
from dept d, emp e
where d.deptno = e.deptno;
select /*+ leading(e) use_hash(d) */
d.deptno, d.dname, e.empno, e.ename
from dept d, emp e
where d.deptno = e.deptno;
select /*+ leading(r, c, l, d, e)
use_hash(c) use_hash(l) use_hash(d) use_hash(e) */
e.first_name, e.last_name, d.department_name
, l.street_address, l.city, c.country_name, r.region_name
from hr.regions r
, hr.countries c
, hr.locations l
, hr.departments d
, hr.employees e
where d.department_id = e.department_id
and l.location_id = d.location_id
and c.country_id = l.country_id
and r.region_id = c.region_id;
----------------------------------------------------------------------------------------
Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
0 | SELECT STATEMENT | | 106 | 10706 | 15 (14)| 00:00:01 |
* 1 | HASH JOIN | | 106 | 10706 | 15 (14)| 00:00:01 |
* 2 | HASH JOIN | | 27 | 2241 | 12 (17)| 00:00:01 |
* 3 | HASH JOIN | | 23 | 1472 | 8 (13)| 00:00:01 |
* 4 | HASH JOIN | | 25 | 700 | 5 (20)| 00:00:01 |
5 | TABLE ACCESS FULL| REGIONS | 4 | 56 | 3 (0)| 00:00:01 |
6 | INDEX FULL SCAN | COUNTRY_C_ID_PK | 25 | 350 | 1 (0)| 00:00:01 |
7 | TABLE ACCESS FULL | LOCATIONS | 23 | 828 | 3 (0)| 00:00:01 |
8 | TABLE ACCESS FULL | DEPARTMENTS | 27 | 513 | 3 (0)| 00:00:01 |
9 | TABLE ACCESS FULL | EMPLOYEES | 107 | 1926 | 3 (0)| 00:00:01 |
----------------------------------------------------------------------------------------
select /*+ leading(r, c, l, d, e)
use_hash(c) use_hash(l) use_hash(d) use_hash(e)
swap_join_inputs(l)
swap_join_inputs(d)
swap_join_inputs(e) */
e.first_name, e.last_name, d.department_name
, l.street_address, l.city, c.country_name, r.region_name
from hr.regions r
, hr.countries c
, hr.locations l
, hr.departments d
, hr.employees e
where d.department_id = e.department_id
and l.location_id = d.location_id
and c.country_id = l.country_id
and r.region_id = c.region_id;
-----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 106 | 10706 | 15 (14)| 00:00:01 |
|* 1 | HASH JOIN | | 106 | 10706 | 15 (14)| 00:00:01 |
| 2 | TABLE ACCESS FULL | EMPLOYEES | 107 | 1926 | 3 (0)| 00:00:01 |
|* 3 | HASH JOIN | | 27 | 2241 | 12 (17)| 00:00:01 |
| 4 | TABLE ACCESS FULL | DEPARTMENTS | 27 | 513 | 3 (0)| 00:00:01 |
|* 5 | HASH JOIN | | 23 | 1472 | 8 (13)| 00:00:01 |
| 6 | TABLE ACCESS FULL | LOCATIONS | 23 | 828 | 3 (0)| 00:00:01 |
|* 7 | HASH JOIN | | 25 | 700 | 5 (20)| 00:00:01 |
| 8 | TABLE ACCESS FULL| REGIONS | 4 | 56 | 3 (0)| 00:00:01 |
| 9 | INDEX FULL SCAN | COUNTRY_C_ID_PK | 25 | 350 | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------
select /*+ leading(d, e, l, c, r)
use_hash(e) use_hash(l) use_hash(c) use_hash(r)
swap_join_inputs(l)
swap_join_inputs(c)
swap_join_inputs(r) */
e.first_name, e.last_name, d.department_name
, l.street_address, l.city, c.country_name, r.region_name
from hr.regions r
, hr.countries c
, hr.locations l
, hr.departments d
, hr.employees e
where d.department_id = e.department_id
and l.location_id = d.location_id
and c.country_id = l.country_id
and r.region_id = c.region_id;
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 106 | 10706 | 15 (14)| 00:00:01 |
|* 1 | HASH JOIN | | 106 | 10706 | 15 (14)| 00:00:01 |
| 2 | TABLE ACCESS FULL | REGIONS | 4 | 56 | 3 (0)| 00:00:01 |
|* 3 | HASH JOIN | | 106 | 9222 | 12 (17)| 00:00:01 |
| 4 | INDEX FULL SCAN | COUNTRY_C_ID_PK | 25 | 350 | 1 (0)| 00:00:01 |
|* 5 | HASH JOIN | | 106 | 7738 | 10 (10)| 00:00:01 |
| 6 | TABLE ACCESS FULL | LOCATIONS | 23 | 828 | 3 (0)| 00:00:01 |
|* 7 | HASH JOIN | | 106 | 3922 | 7 (15)| 00:00:01 |
| 8 | TABLE ACCESS FULL| DEPARTMENTS | 27 | 513 | 3 (0)| 00:00:01 |
| 9 | TABLE ACCESS FULL| EMPLOYEES | 107 | 1926 | 3 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------
 |
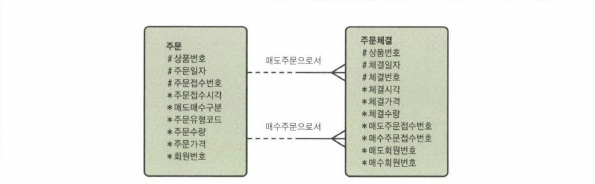 |
select /*+ use hash(t o) index(t) index(o) */
o.상품번호,o.주문접수번호,o.회원번호
, o.매도매수구분,o.주문유형코드,
, o.주문수량,o.주문가격
,t.체결가격, t.체결수량,(t.체결가격 * t.체결수량) 체결금액
from 주문체결 t, 주문 o
where t.상품번호 = :상품번호
and t.체결일자 = :체결일자
and o.상품번호 = t.상품번호 => 해시키
and o.주문일자 = t.체결일자 => 해시키
and o.주문접수번호 in (t.매도주문접수번호, t.매수주문접수번호)
select /*+ use hash(t o) index(o) */
o.상품번호,o.주문접수번호,o.회원번호,o.매도매수구분,o.주문유형코드
'o.주문수량,o.주문가격,o.체결가격
't.체결수량, (t.체결가격 * t.체결수량) 체결금액
from (
select /*+ index(t) */
상품번호, 체결일자, 체결가격, 체결수량, 매도주문접수번호, 주문접수번호
from 주문체결 t
union all
select /*+ index (t) */
상품번호, 체결일자, 체결가격, 체결수량, 매수주문접수번호, 주문접수번호
from 주문체결 t
) t
, 주문 o
where t.상품번호 = :상품번호
and t.체결일자 = :체결일자
and o.상품변호 = t.상품번호
and o.주문일자 = t.체결일자
and o.주문접수변호 = t.주문접수번호 =>해시 키 값으로 사용
create table 복제테이블 as select rownum 번호 from dual connect by level <=100;
select /*+ use_hash(t o) index(o) */
from o.상품번호, o.주문접수번호, o.회원번호, o.매도매수구분, o.주문유형코드
, o.주문수량, o.주문가격, t.체결가격, t.체결수량
, (t.체결가격*t.체결수량) 체결금액
from ( select /*+ index(t) index(c) */
t.상품번호, t.체결일자, t.체결가격, t.체결수량
, decode(c.번호, 1, t.매도주문접수번호, 2, t.매수주문접수번호) 주문접수번호
from 주문체결 t, 복제테이블 c
where c.번호 <=2
) t,
주문 o
where t.상품번호 =: 상품번호
and t.체결일자 =: 체결일자
and o.상품번호 = t.상품번호
and o.주문일자 = t.체결일자
and o.주문접수번호 = t.주문접수번호 => 해시키값으로 사용
- 강좌 URL : http://www.gurubee.net/lecture/3268
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.