press x to close
인덱스에 사용할 컬럼을 선택하고
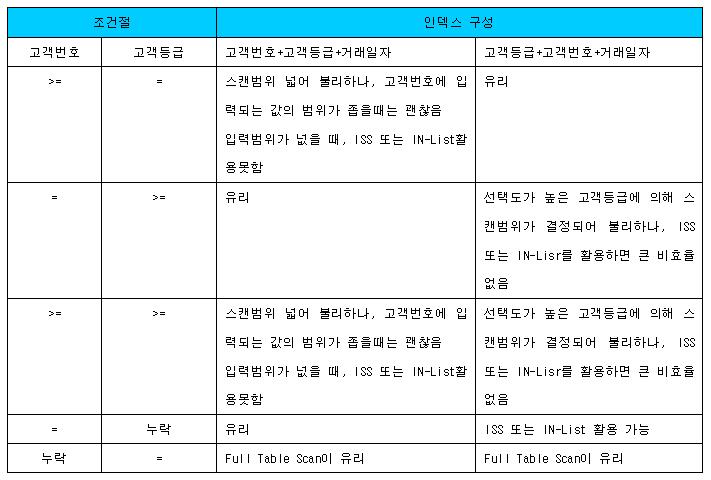
<검색조건1>
where 고객번호 = 1
and 거래일자 between '20090101'and '20090331'
<검색조건2>
where 상품번호 = 'A'
and 거래일자 between '20090101'and '20090331'
<검색조건3>
where 고객번호 = 1
and 상품번호 = 'A'
and 거래일자 between '20090101'and '20090331'
<검색조건4>
where 거래일자 between '20090101'and '20090331'
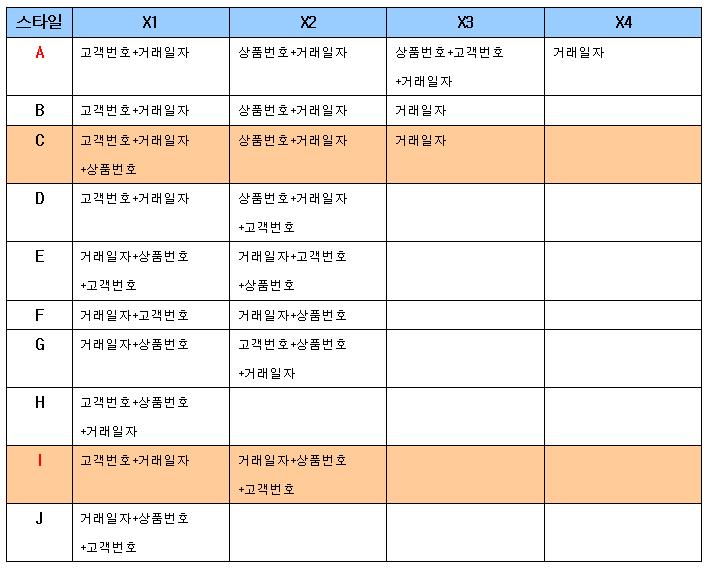 |
| 스타일A | 스타일I |
|---|---|
| X1:고객번호+거래일자 X2:상품번호+거래일자 X3:상품번호+고객번호+거래일자 X4:거래일자 | X1:고객번호+거래일자 X2:거래일자+상품번호+고객번호 |
| 조건 | 스타일A | 스타일I | 비고 |
|---|---|---|---|
| 조건1 | X1 | X1 | 두번의 테이블 Random Access |
| 조건2 | X2 | X2-불필요한 상품번호까지 스캔하는 비효율존재 | 세번의 테이블 Random Access |
| 조건3 | X3-단 한건의 Random Access | X1-두번의 테이블액세스, 거래범위가 좁으면 X2를 이용해 불필요한 Random Access를 없애는게 좋을수도 | |
| 조건4 | X4 | X2 | 동일한 테이블 Random Access, Range파티션 고려 |
<쿼리1> - 사용빈도 높음
select * from 고객
where 고객번호 = :no;
<쿼리2>
select * from 고객
where 연령 = :age
and 성별 = :gender
and 이름 like :name || '%';
<쿼리3>
select * from 고객
where 연령 between :age1 and :age2
and 거주지역 = :region
and 등록일 like :rdate || '%';
<쿼리4> - 사용빈도 높음
select /*+ orderd use_nl(b) */ * from 주문 a, 고객 b
where a.거래일자 = :tdate
and a.상품번호 = :good
and a.고객번호 = b.고객번호
and b.거주지역 = :region;
 |
SQL> create table t
as select rownum a, rownum b, rownum c, rownum d, rownum e
from dual
connect by level <= 100000;
테이블이 생성되었습니다.
SQL> create index t_idx on t(a, b, c, d);
인덱스가 생성되었습니다.
select * from t where a=1 order by a, b, c;
select * from t where a=1 and b=1 order by c, d;
select * from t where a=1 and c=1 order by b, d;
select * from t where a=1 and b=1 order by a, c, b, d;
SQL> explain plan for
2 select * from t
3 where a between 1 and 2
4 and b not in (1, 2)
5 and c between 2 and 3
6 order by a, b, c, d;
해석되었습니다.
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
Plan hash value: 470836197
-------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 24 | 3 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| T | 1 | 24 | 3 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | T_IDX | 1 | | 2 (0)| 00:00:01 |
-------------------------------------------------------------------------------------
SQL> explain plan for
2 select * from t
3 where a between 1 and 2
4 and c between 2 and 3
5 order by a, b, c;
해석되었습니다.
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
Plan hash value: 470836197
-------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 24 | 3 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| T | 1 | 24 | 3 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | T_IDX | 1 | | 2 (0)| 00:00:01 |
-------------------------------------------------------------------------------------
SQL> explain plan for
2 select * from t
3 where a between 1 and 2
4 and b <> 3
5 order by a, b, c;
해석되었습니다.
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
Plan hash value: 470836197
-------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 24 | 3 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| T | 1 | 24 | 3 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | T_IDX | 1 | | 2 (0)| 00:00:01 |
-------------------------------------------------------------------------------------
SQL> explain plan for
2 select /*+ index(t) */ * from t
3 where b between 2 and 3
4 order by a, b, c, d;
해석되었습니다.
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
Plan hash value: 3778778741
-------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 24 | 434 (2)| 00:00:06 |
| 1 | TABLE ACCESS BY INDEX ROWID| T | 1 | 24 | 434 (2)| 00:00:06 |
|* 2 | INDEX FULL SCAN | T_IDX | 1 | | 433 (2)| 00:00:06 |
-------------------------------------------------------------------------------------
SQL> explain plan for
2 select * from t where a=1 order by c;
해석되었습니다.
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
Plan hash value: 1454352066
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 24 | 4 (25)| 00:00:01 |
| 1 | SORT ORDER BY | | 1 | 24 | 4 (25)| 00:00:01 |
| 2 | TABLE ACCESS BY INDEX ROWID| T | 1 | 24 | 3 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | T_IDX | 1 | | 2 (0)| 00:00:01 |
--------------------------------------------------------------------------------------
SQL> explain plan for
2 select * from t
3 where a=1
4 and b between 1 and 2
5 order by c, d;
해석되었습니다.
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
Plan hash value: 1454352066
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 24 | 4 (25)| 00:00:01 |
| 1 | SORT ORDER BY | | 1 | 24 | 4 (25)| 00:00:01 |
| 2 | TABLE ACCESS BY INDEX ROWID| T | 1 | 24 | 3 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | T_IDX | 1 | | 2 (0)| 00:00:01 |
--------------------------------------------------------------------------------------
SQL> explain plan for
2 select * from t
3 where a=1
4 and b between 1 and 2
5 order by a, c, b;
해석되었습니다.
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------
Plan hash value: 1454352066
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 24 | 4 (25)| 00:00:01 |
| 1 | SORT ORDER BY | | 1 | 24 | 4 (25)| 00:00:01 |
| 2 | TABLE ACCESS BY INDEX ROWID| T | 1 | 24 | 3 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | T_IDX | 1 | | 2 (0)| 00:00:01 |
--------------------------------------------------------------------------------------
- 강좌 URL : http://www.gurubee.net/lecture/3263
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.