press x to close
-- 쿼리 1)
SELECT ENAME FROM EMP WHERE SAL >= 2000;
Optimizer mode: ALL_ROWS
Rows Row Source Operation
------- ---------------------------------------------------
6 TABLE ACCESS FULL EMP (cr=4 pr=0 pw=0 time=0 us cost=3 size=120 card=6)
-- 쿼리 2)
SELECT * FROM EMP WHERE SAL >= 2000;
Rows Row Source Operation
------- ---------------------------------------------------
6 TABLE ACCESS FULL EMP (cr=4 pr=0 pw=0 time=0 us cost=3 size=522 card=6)
-- 쿼리 3)
SELECT EMPNO, ENAME FROM EMP WHERE SAL >= 2000;
Rows Row Source Operation
------- ---------------------------------------------------
6 TABLE ACCESS FULL EMP (cr=4 pr=0 pw=0 time=0 us cost=3 size=198 card=6)
select deptno, avg(sal) from emp group by deptno ;
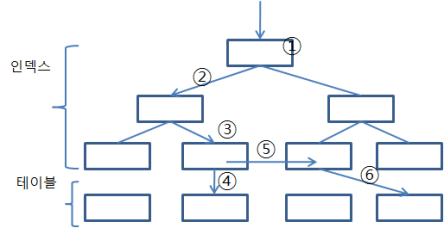 |
--------------------------------------------------------------------------------
Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - 64bit Production
--------------------------------------------------------------------------------
create table t
as
select * from all_objects
order by dbms_random.value;
Table created.
SUNSHINY@ORACLE11> select count(*) from t;
COUNT(*)
----------
70456
-- T 테이블에는 70,456건의 레코드가 저장돼 있음.
select count(*) from t
where owner like 'SYS%'
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 5 0.02 0.02 0 5 0 0
Execute 5 0.00 0.00 0 0 0 0
Fetch 10 0.10 0.10 0 5045 0 5
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 20 0.12 0.12 0 5050 0 5
Misses in library cache during parse: 3
Optimizer mode: ALL_ROWS
Rows Row Source Operation
------- ---------------------------------------------------
1 SORT AGGREGATE (cr=1009 pr=0 pw=0 time=0 us)
34143 TABLE ACCESS FULL T (cr=1009 pr=0 pw=0 time=19436 us cost=282 size=566151 card=33303)
select count(*) from t
where owner like 'SYS%'
and object_name = 'ALL_OBJECTS'
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 2 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 0.00 0.00 0 1009 0 1
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 0.01 0.01 0 1011 0 1
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Rows Row Source Operation
------- ---------------------------------------------------
1 SORT AGGREGATE (cr=1009 pr=0 pw=0 time=0 us)
1 TABLE ACCESS FULL T (cr=1009 pr=0 pw=0 time=0 us cost=282 size=1156 card=34)
SUNSHINY@ORACLE11> create index t_idx on t (owner, object_name);
Index created.
SUNSHINY@ORACLE11> select /*+ index(t t_idx) */ count(*) from t
2 where owner like 'SYS%'
3 and object_name = 'ALL_OBJECTS';
COUNT(*)
----------
1
select /*+ index(t t_idx) */ count(*) from t
where owner like 'SYS%'
and object_name = 'ALL_OBJECTS'
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 2 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 0.00 0.00 102 100 0 1
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 0.00 0.00 102 102 0 1
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Rows Row Source Operation
------- ---------------------------------------------------
1 SORT AGGREGATE (cr=100 pr=102 pw=0 time=0 us)
1 INDEX RANGE SCAN T_IDX (cr=100 pr=102 pw=0 time=0 us cost=212 size=1156 card=34)(object id 84124)
-- 1개 레코드를 얻으려고 실제 스캔한 레코드 수.
SUNSHINY@ORACLE11> select /*+ index(t t_idx) */ count(*) from t
2 where owner like 'SYS%'
3 and ((owner = 'SYS' and object_name >= 'ALL_OBJECTS' ) or (owner >'SYS'));
COUNT(*)
----------
18855
-- 인덱스 컬럼 순서를 변경하고 같은 쿼리를 수행.
drop index t_idx;
create index t_idx on t(object_name, owner);
select /*+ index(t t_idx) */ count(*) from t
where owner like 'SYS%'
and object_name = 'ALL_OBJECTS'
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.01 0.01 0 3 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 0.00 0.00 0 3 0 1
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 0.01 0.01 0 6 0 1
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Rows Row Source Operation
------- ---------------------------------------------------
1 SORT AGGREGATE (cr=3 pr=0 pw=0 time=0 us)
1 INDEX RANGE SCAN T_IDX (cr=3 pr=0 pw=0 time=0 us cost=3 size=34 card=1)(object id 84125)
ONE PLUS SCAN
drop index t_idx;
create index t_idx on t(owner);
select object_id from t
where owner = 'SYS'
and object_name = 'ALL_OBJECTS'
Rows Row Source Operation
------- ---------------------------------------------------
1 TABLE ACCESS BY INDEX ROWID T (cr=1072 pr=0 pw=0 time=0 us cost=39 size=47 card=1)
30677 INDEX RANGE SCAN T_IDX (cr=67 pr=0 pw=0 time=11120 us cost=6 size=0 card=337)(object id 84126)
drop index t_idx;
create index t_idx on t(owner, object_name);
select object_id from t
where owner = 'SYS'
and object_name = 'ALL_OBJECTS'
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 0.00 0.00 0 5 0 1
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 0.00 0.00 0 5 0 1
Misses in library cache during parse: 0
Optimizer mode: FIRST_ROWS
Parsing user id: 85
Rows Row Source Operation
------- ---------------------------------------------------
1 TABLE ACCESS BY INDEX ROWID T (cr=5 pr=0 pw=0 time=0 us cost=5 size=47 card=1)
1 INDEX RANGE SCAN T_IDX (cr=4 pr=0 pw=0 time=0 us cost=3 size=0 card=1)(object id 84128)
- 강좌 URL : http://www.gurubee.net/lecture/3117
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.