press x to close
 |
 |
-- 테이블 생성
create table t (
x NUMBER not null
, y NUMBER not null ) ;
-- 데이터 insert(랜덤으로)
insert into t
select *
from (
select rownum x, rownum y
from dual
connect by level <= 5000000
)
order by dbms_random.value
;
alter table t add
constraint t_pk primary key (x);
alter system flush buffer_cache;
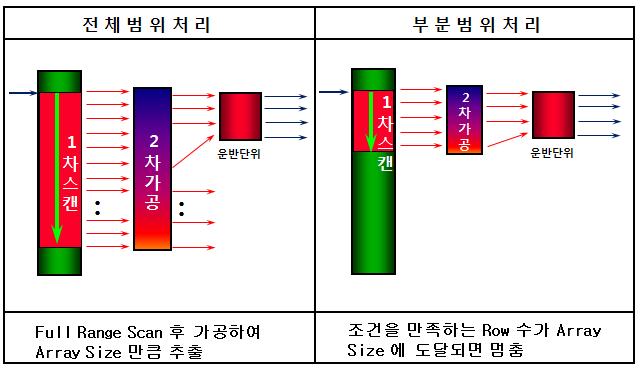
-- 6건 검색
select /*+ index(t t_pk) */ x, y
from t
where x > 0
and y <= 6 ;
-- 1건 검색
select /*+ index(t t_pk) */ x, y
from t
where x > 0
and y <= 1 ;
SQL> create table test as select * from all_objects;
테이블이 생성되었습니다.
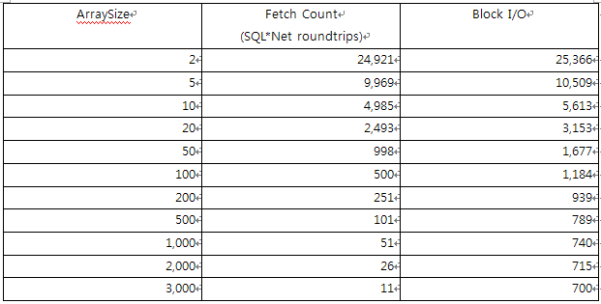
SQL> set autotrace traceonly statistics;
SQL> set arraysize 2;
SQL> select * from test;
47094 rows selected.
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
23871 consistent gets
530 physical reads
0 redo size
6247169 bytes sent via SQL*Net to client
259498 bytes received via SQL*Net from client
23548 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
47094 rows processed
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.02 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 23548 0.27 1.54 0 23871 0 47094
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 23550 0.27 1.58 0 23871 0 47094
| db block gets | current |
| consistent gets | query |
| physical reads | disk |
| SQL*Net roundtrips to/from client | Fetch count |
| rows processed | Fetch rows |
 |
declare
l_object_name big_table.object_name%type;
begin
for item in ( select object_name from big_table where rownum <= 1000 )
loop
l_object_name := item.object_name;
dbms_output.put_line(l_object_name);
end loop;
end;
/
declare
l_object_name big_table.object_name%type;
cursor c is select object_name from big_table where rownum <= 1000;
begin
for item in c
loop
l_object_name := item.object_name;
dbms_output.put_line(l_object_name);
end loop;
end;
/
-- sql트레이스는 동일하다.
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 11 0.00 0.00 0 24 0 1000
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 13 0.00 0.00 0 24 0 1000
declare
cursor c is
select object_name
from test where rownum <= 1000;
l_object_name test.object_name%type;
begin
open c;
loop
fetch c into l_object_name;
exit when c%notfound;
dbms_output.put_line(l_object_name);
end loop;
close c;
end;
-- sql 트레이스 결과
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 1001 0.00 0.00 0 1003 0 1000
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 1003 0.00 0.00 0 1003 0 1000
위의 결과 Cursor FOR Loop를 사용하지 않으면 Array단위 Fetch가 작동하지 않음을 알 수 있다.
String sql = "select id,pw from customer";
PreparedStatment stmt = conn.prepareStatment(sql);
Stmt.setFetchSize(100); //여기!!!
ResultSet rs = stmt.executeQuery();
// rs.setFetchSize(100); -- ResultSet에서 조정할 수도 있다.
while(rs.next()){
......
}
rs.close();
stmt.close();
- 강좌 URL : http://www.gurubee.net/lecture/3112
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.