press x to close
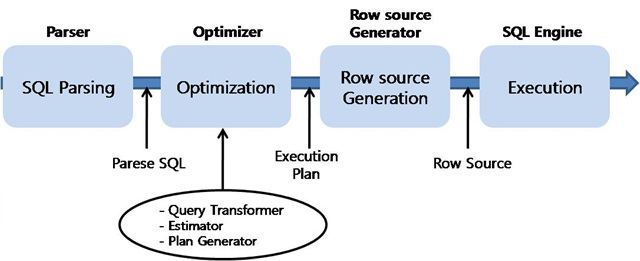 |
SQL> alter session set events '10046 trace name context forever, level 12';
SQL> exit
[TEST10]clt585av13:/lim/admin/TEST10/udump> tkprof test10_ora_18030.trc
output = lc_test
TKPROF: Release 10.2.0.4.0 - Production on Sat May 12 02:28:52 2012
Copyright (c) 1982, 2007, Oracle. All rights reserved.
[TEST10]clt585av13:/lim/admin/TEST10/udump> vi lc_test
********************************************************************************
SQL> select * from TAX_TAB where rownum <3;
select *
from
TAX_TAB where rownum <3
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 1 0.00 0.00 1 3 0 0
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 3 0.00 0.00 1 3 0 0
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 124
Elapsed times include waiting on following events:
Event waited on Times Max. Wait Total Waited
---------------------------------------- Waited ---------- ------------
SQL*Net message to client 1 0.00 0.00
SQL*Net more data to client 1 0.00 0.00
db file sequential read 1 0.00 0.00
********************************************************************************
h6 적응적 탐색 전략(Adaptive Search Stratigy) 사용
- 강좌 URL : http://www.gurubee.net/lecture/3097
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.