리버스 키(Reverse Key) 인덱스는 B*TREE 인덱스와 거의 같다. 단지 인덱스 키 값을 반대로 구성해 비트리 인덱스를 생성할 뿐이다. 그로 인한 몇 가지 제약 조건이 있을 뿐이다. 지금부터는 이에 대해 자세히 살펴보자.
B*TREE의 인덱스의 특징을 엿볼 수 있는 <그림 1>을 먼저 살펴보자. 여기서 사업번호 컬럼의 값이 순차적으로 증가할 경우 가장 우측의 리프 블록에 있는 인덱스 엔트리는 계속 순차적으로 추가(Insert)가 발생하게 된다.
따라서 최근 데이터가 저장돼 있는 리프 블록에 대해 경합이 증가된다. 이러한 경합을 제거하기 위해 리버스 키 인덱스가 고안됐다. 리버스 키 인덱스는 오라클 데이터베이스 8버전부터 지원한다.
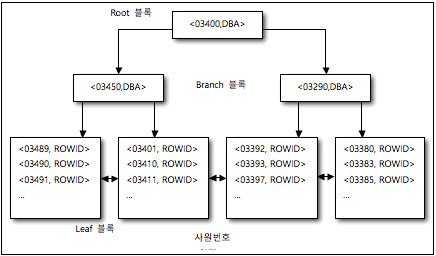
리버스 키 인덱스의 구조
앞서 언급했듯 리버스 키 인덱스는 B*TREE 인덱스와 구조가 같다. 단지 저장되는 데이터만 역으로 리프 블록에 저장한다. 리버스 키 인덱스의 구조는 아래과 같다.
Reverse Key 인덱스의 개념
- - B*TREE 인덱스 구조와 동일
- - 인덱스 키 값에 대해 역으로 구성
- - 인덱스 범위 스캔(RANGE SCAN) 불가
- - 우측 리프블록 경합 방지 가능
Reverse Key 인덱스의 구조
- - 루트 블록(Root Block) : 분기 값 저장
- - 브랜치 블록(Branch Block) : 분기 값 저장
- - 리프 블록(Leaf Block) : 인덱스 키 값 + ROWID 저장
- - 인덱스 키 값 : 기존 데이터의 값을 역으로 하여 인덱스 키 값으로 이용
지금부터는 리버스 키 인덱스의 생성 원리를 살펴보자
먼저 기존 테이블에 대한 인덱스 키 컬럼의 값을 반대로 변경해 B*TREE 인덱스를 생성한다. 테이블의 데이터 <03550, 이가혜>는 인덱스 키 컬럼인 사원번호 컬럼은 반대로 만들어지므로 데이터 값이 <05530, 이가혜>로 변경된다.
해당 데이터는 리버스 키 인덱스에서 인덱스 키 컬럼의 값이 05530으로 변경돼 사원번호 인덱스에 저장된다.
이처럼 리버스 키 인덱스는 B*TREE 인덱스와 구조가 같다. 단지 인덱스 키 값만을 반대로 변경해 B*TREE 인덱스를 생성한 것에 불과한 것이다.
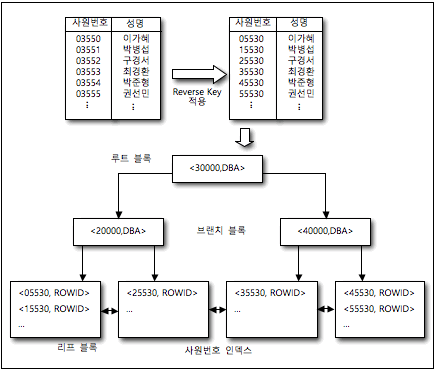
리버스 키 인덱스의 생성과 사용
사원번호 값이 순차적으로 증가할 경우 일반적인 B*TREE 인덱스는 우측 리프 블록으로 모든 데이터가 저장된다.
그렇기 때문에 우측 리프 블록에 경합이 발생한다. 반면 리버스 키 인덱스는 사업번호 값이 순차적으로 증가하더라도 사원번호 인덱스의 우측 리프 블록에만 추가(Insert)가 발생하지 않고 모든 인덱스 블록으로 추가되게 된다.
이는 인덱스를 구성하는 과정에서 순차적으로 값을 역으로 변경해 B*TREE 인덱스를 생성하기 때문이다.
Reverse Key 인덱스의 사용
순차적으로 증가하는 데이터의 인덱스에 대해 리프블록 경합 제거 가능
Reverse Key 인덱스 생성
리버스 키 인덱스라고해서 다른 인덱스와 생성 방법이 다른 것은 아니다. 인덱스를 생성할 때 옵션을 설정하는 것 하나만 다를 뿐이다.
CREATE INDEX empno_idx ON emp(empno) REVERSE ;
B*TREE 인덱스에서 Reverse Key 인덱스로의 변경
리버스 키 인덱스는 B*TREE 인덱스와 구조가 같으므로 언제든지 리버스 키 인덱스로 변경할 수 있다. 물론 리버스 키 인덱스를 B*TREE 인덱스로 언제든지 변경할 수도 있다.
이처럼 인덱스를 변경할 경우 실제 인덱스를 재구성하므로 데이터 양에 따라 많은 시간이 소요될 수 있다.ALTER INDEX index_name REBUILD REVERSE; ALTER INDEX index_name REBUILD NOREVERSE;
앞선 예제에서 사원번호가 03550과 03551인 인덱스 엔트리는 같은 리프 블록에 존재하지만 그 다음 사원번호인 03552는 다른 인덱스 리프 블록에 추가된다.
이런 원리에 의해 순차적으로 증가하는 데이터의 인덱스 엔트리들은 인덱스의 모든 리프 블록에 분산 저장된다.
즉 B*TREE 인덱스의 단점인 순차적으로 증가하는 인덱스 키 컬럼의 경우 최근 데이터가 우측 리프 블록에 집중되는 경합을 리버스 키 인덱스로 해결할 수 있다.






- 강좌 URL : http://www.gurubee.net/lecture/2959
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.