press x to close
오라클이 제공하는 인덱스의 종류는 다양하다. 데이터베이스도 다양한 종류의 인덱스를 제공하는 만큼 이러한 인덱스 종류를 정확히 이해하는 것은 매우 중요하다.
오라클이 제공하는 인덱스 종류는 총 네 가지다. 테이블을 생성한 다음 이 네 가지 인덱스 중 하나를 선택해 사용할 수 있다.
그렇다면 생성한 테이블에 어떤 인덱스를 적용할 것인가? 이는 결코 쉬운선택이 아니다. 수많은 기업들의 DB를 봐도 대부분 B*TREE 인덱스를 쓰는 정도가 고작이다.
다만 시대가 변하고 업무가 복잡해짐에 따라 함수 기반 인덱스를 사용하는 경우도 간혹 있다. 그럼에도 대부분의 인덱스는 여전히 B+TREE이다.
이처럼 B*TREE가 광범위하게 사용되는 이유는 무엇일까? 그것은 아마도 다음의 두 가지 이유 때문일 것이다.
① 인덱스에는 네 가지 종류가 있음에도 이를 잘 모르는 경우가 많다. 그렇기 때문에 기본 인덱스인 B*TREE를 생성하는 경우가 많다.
② 대부분의 업무에 B*TREE 인덱스가 최적인 경우가 많다. 인덱스의 특징은 차후 살펴볼 특성에 의해 좌우된다. 인덱스의 특성상 대부분의 업무에는 비트맵 인덱스, 함수 기반 인덱스, REVERSE KEY 인덱스보다는 B*TREE 인덱스가 더 유리하다.
이러한 두 가지 이유로 인해 대부분의 웹사이트에는 B*TREE 인덱스가 쓰이고 있다. 그렇더라도 네 가지 인덱스의 특성을 알아야 적재적소에 최적의 인덱스를 적용할 수 있을 것이다.
오라클에서 가장 흔히 쓰이는 B*TREE 인덱스는 아래와 같은 특징을 가지고 있다. 동일한 인덱스를 스캔해 한건의 데이터를 액세스하는 경우 동일한 개수의 블록을 스캔하므로 어느 데이터를 액세스하더라도 성능이 일정하다.
이러한 특징으로 인해 B*TREE 인덱스는 조회, 삭제(DELETE), 추가(INSERT) 등의 작업에 효율적이다.
테이블의 어느 데이터를 액세스하더라도 동일한 성능이 보장되서다. 만약 TAB1 테이블의 COL1 컬럼에 A와 B라는 데이터가 각각 한 건씩 있다고 가정해 보자.
만약 SQL을 이용해 COL1 컬럼의 값이 A인 데이터와 B 데이터를 추출하는 속도가 서로 상이하다면 이는 굉장히 큰 문제가 될 것이다.
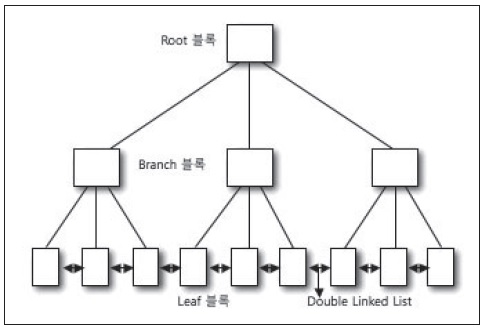
[그림1]는 B*TREE 인덱스의 구조다. 각각의 블록과 구조상의 특징은 다음과 같다.
루트 블록은 인덱스의 다음 단계의 브랜치 블록을 가리키는 항목들을 포함하고 있다.
브랜치 블록은 < Separator Key, DBA>로 구성돼 있으며, 브랜치 블록 밑의 리프 블록을 가리킨다.
리프 블록은 실제 < 인덱스 Key 값, ROWID>로 구성된다. 이는 해당 데이터를 액세스하는 Key가 된다.
리프 블록간의 양 방향 통신을 의미한다. 더블 링크드 리스트는 리프 블록의 한 인덱스 값에서 범위(RANGE) 스캔을 빠르게 할 수 있게 해준다. 이 부분은 B*TREE 인덱스의 액세스에서 자세히 살펴본다.
이러한 구성의 B*TREE 인덱스는 어떻게 액세스를 하는 것일까? 지금부터 B*TREE 인덱스의 액세스 과정을 살펴보자.
1 2 3 | SELECT ENAME, ADDRESS FROM EMP WHERE EMPNO = '03489'; |
<리스트 1>은 EMP 테이블의 EMPNO 인덱스를 스캔해 EMPNO가 03489인 사원의 이름(ENAME)과 주소(ADDRESS)를 조회한다.
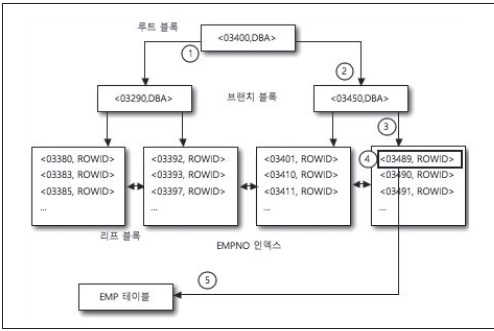
B*TREE 인덱스 방식은 EMPNO 인덱스를 다음과 같은 방식으로 액세스한다.
① EMPNO 인덱스의 루트 블록을 확인한다. 루트 블록의 Separator Key를 확인해 EMPNO의 값이 03400을 기준으로 더 큰 값이면 우측으로, 더 작은 값이면 좌측으로 분기한다.
② 루트 블록의 Separator Key를 통해 03489는 03400보다 크기 때문에 우측 브랜치 블록으로 이동하게 된다.
③ 브랜치 블록을 스캔해 브랜치 블록 Separator Key를 확인한 결과, <03450,DBA>이다. 그렇기 때문에 03450보다 값이 크면 좌측으로, 작으면 우측으로 이동해 리프 블록을 액세스하게 된다. 03489는 03450보다 크므로 우측 아래로 이동하게 된다.
④ 브랜치 블록에서 리프 블록으로 이동하게 되면 해당 블록을 스캔해 <03489,ROWID>라는 인덱스 값을 확인할 수 있다.
⑤ 해당 인덱스 값의 ROWID를 통해 실제 테이블을 액세스하게 된다.
이러한 방식으로 데이터를 액세스하기 때문에 어떤 EMPNO를 조회하더라도 루트 블록, 브랜치 블록, 리프 블록을 하나씩만 액세스하게 된다.






- 강좌 URL : http://www.gurubee.net/lecture/2935
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.