인덱스의 핵심 중 하나는 ROWID다. ROWID는 데이터베이스 내 데이터 공유의 주소로, 이를 통해 데이터에 접근할 수 있어 DBA라면 반드시 이해해야 할 개념이다.
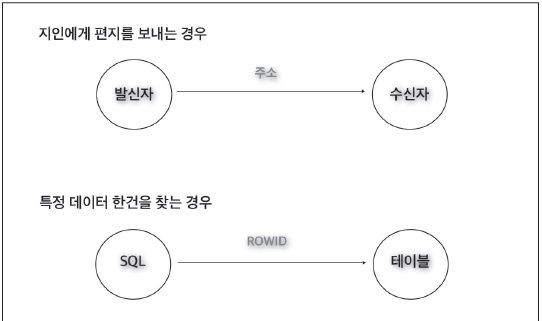
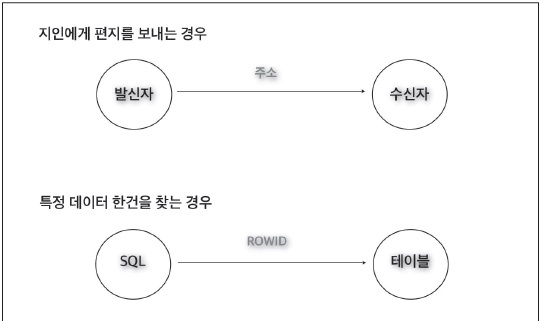
지인에게 편지를 보내야 하는 경우를 가정해 보자(<그림 1> 참조). 지인의 집 주소를 안다면 편지를 보내는 데 별다른 문제가 없을 것이다. 이처럼 SQL에서도 원하는 데이터를 액세스하기 위해서는 ‘주소’를 알아야 한다.
데이터베이스에서 데이터마다의 주소를 의미하는 개념이 바로 ROWID다. ROWID는 각가의 데이터를 구분할 수 있는 유일한 ID이기도 하다. 데이터마다 유일하기 때문에 오라클 내부에서는 데이터를 가르키기 위한 주소로 쓰인다.
- [그림1] 지인에게 편지를 보내는 가상 시나리오
예컨대 이메일 주소는 사람마다 고유하다. 그렇게 때문에 특정 이메일을 보내면 해당 이메일 소유권자가 해당 메일을 받게 된다. 이처럼 하나의 ROWID를 안다는 것은 해당 데이터 한 건을 액세스할 수 있음을 의미한다.
- [그림2] ROWID 구조
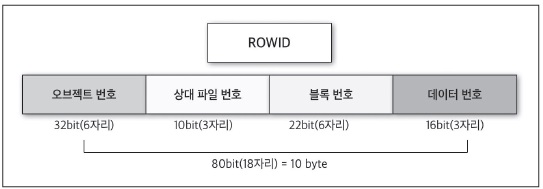
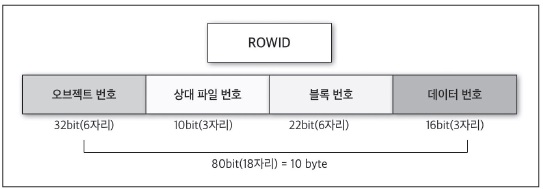
<그림 2>는 ROWID 아키텍처로, 크게 다음과 같은 4개의 영역으로 구성돼 있다.
오브젝트 번호
해당 데이터가 속하는 오브젝트 번호다. 오브젝트별로 유일한 값을 가지고 있다.
상대 파일 번호
오라클의 테이블스페이스는 여러 개의 DATAFILE를 생성할 수 있다. 오라클 8i부터는 파일 번호가 10비트이기 때문에 테이블스페이스당 1023개의 DATAFILE을 추가할 수 있다. 여기서 DATAFILE은 해당 테이블스페이스의 상대 파일 번호를 의미하며, 각 데이터별로 유일한 값을 가진다.
블록 번호
파일 안에 어느 블록인지를 의미한다.
데이터 번호
블록의 HEADER에서 해당 데이터의 위치값을 저장하고 있는 DATA DIRECTORY SLOT을 가르킨다. 오브젝트 번호, 파일번호, 블록 번호가 같으면 데이터 번호는 블록별로 데이터가 저장돼 있는 순서를 뜻한다. 이처럼 ROWID는 해당 데이터의 저장 위치를 가리키는 요소라고 할 수 있다.
- [리스트 1] EMP 테이블
-
SQL> DESC EMP EMPNO NOT NULL NUMBER(4) ENAME VARCHAR2(10) JOB VARCHAR2(9) MGR NUMBER(4) HIREDATE DATE SAL NUMBER(7,2) COMM NUMBER(7,2) DEPTNO NUMBER(2) SQL> SELECT ENAME, SAL, ROWID FROM EMP; ENAME SAL ROWID SMITH 2000 AAAMfPAAEAAAAAgAAA ALLEN 1600 AAAMfPAAEAAAAAgAAB WARD 1250 AAAMfPAAEAAAAAgAAC JONES 2975 AAAMfPAAEAAAAAgAAD MARTIN 1250 AAAMfPAAEAAAAAgAAE
<리스트 1>에서 EMP 테이블은 ROWID라는 컬럼이 없음에도 ROWID라는 컬럼이 존재하는 것처럼 보인다. 모든 테이블의 모든 데이터는 내부적으로 ROWID를 저장하고 있으므로 해당 ROWID는 언제든 추출 가능하다. 지금부터는 앞서 추출된 ROWID를 분석해 보자.
ROWID의 처음 6자리
AAAMfP는 오브젝트 번호다. 이는 오브젝트별로 유일한 값이므로 EMP 테이블의 모든 데이터의 ROWID는 AAAMfP로 시작한다.
7~9자리까지
EMP 테이블이 저장돼 있는 테이블스페이스 상대 파일 번호다. EMP 테이블의 데이터일지라도 테이블의 익스텐트(EXTENT)가 다른 데이터 파일에 할당될 수 있다. 이 경우 해당 값은 서로 다르게 할당된다.
10~15자리까지
블록 번호로 해당 데이터가 저장돼 있는 블록을 뜻한다. <리스트 1>의 데이터블은 AAAAAg로 같은 블록에 저장돼 있는 것을 알 수 있다. 이 부분은 클러스터 팩터(Cluster Factor)와 많은 관계를 가지고 있다.
액세스하고자 하는 데이터들이 같은 블록안에 저장돼 있으면 성능이 많이 향상된다. 이 부분은 클러스터 팩터 최적화 단원에서 좀 더 깊이 다뤄보도록 하겠다.
16~18자리까지
오브젝트 번호, 파일 번호, 블록 번호가 같다면 해당 데이터 번호는 해당 데이터의 저장 순서를 의미한다.
<리스트 1>에서 SMITH는 AAAAAg 블록의 첫 번째 데이터로, 데이터 번호는 AAA다. ALLEN은 동일 블록에서 데이터 블록에 AAB를 가지므로 이를 통해 추후에 저장됐다는 것을 알 수 있다.
동일한 오브젝트 번호, 파일 번호 및 블록 번호를 가진다면 데이터 번호는 해당 데이터의 저장 순서를 의미한다.
위의 예제에서 ‘SMITH’은 AAAAAg 블록에 첫 번째 저장된 데이터로 데이터 번호가 AAA 값을 가지며 ‘ALLEN’는 동일한 AAAAAg 블록에, 테이블 번호가 AAB이므로 SMITH이 저장된 이후에 저장된 값이다.
이처럼 ROWID를 통해 데이터의 많은 정보들을 알 수 있다. ROWID가 사용되는 부분과 해당 ROWID를 튜닝하는 방법 등은 다음 시간에 살펴보도록 하겠다.






- 강좌 URL : http://www.gurubee.net/lecture/2927
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.
정말 잘 보고 있습니다. 감사합니다!
좋은 정보 공유해주셔서 감사합니다!