식별자(Identifier)는 관계와 마찬가지로 데이터의 속성을 좌우하는 매우 중요한 요소다. 데이터 정합성 유지와 데이터 모델링의 정확도는 식별자 선정이 좌우한다고 해도 과언은 아니다.
이 글에서는 식별자 중에서도 보조 식별자와 상속 식별자 선정 기준을 다양한 각도로 알아본다. 또한 이와 같은 식별자에 대한 인덱스 선정에 대해서도 다룬다.
보조 식별자로는 유니크 식별자(Unique Identifier) 이외의 것 중에서 해당 엔티티의 성격을 결정하는 속성을 선정하면 된다.
보조 식별자 선정 기준
한 가지 예를 함께 살펴보자(<그림 1> 참조). 직원 엔티티에는 유니크한 데이터가 저장되는 속성으로 주민번호와 사원번호가 있다.
만약 사원번호 속성을 유니크 식별자로 선정한 경우 주민번호 속성이 해당 엔티티의 성격을 좌우할 수 있고 업무에서 많이 사용된다면 보조 식별자로 선정한다.
- [그림 1] 보조 Identifier를 선정하는 기준

상속 식별자 선정 기준
상속 식별자는 단어 그대로 외부 엔티티로부터 식별자 전체를 상속받거나 일부를 상속받는 특별한 식별자다. 상속 식별자는 크게 세 가지로 구분된다.
① 상속 식별자만이 유니크 식별자가 되는 경우
다른 엔티티로부터 상속받은 속성만이 해당 엔티티의 유니크 식별자가 되는 경우다.
사원 엔티티의 사원번호 속성이 계약직 엔티티로 상속된 경우를 가정해 보자. 계약직 엔티티에서의 유니크 식별자로는 상속 식별자만이 가능하다. 이러한 경우는 1:1 관계에서 자주 발생한다.
② 상속 식별자와 다른 속성에 의해 유니크 식별자가 되는 경우
다른 엔티티로부터 상속받은 속성들로만 유니크 식별자를 선정하기 어려운 경우가 있다. 이 때에는 해당 엔티티의 다른 속성을 합해 유니크 식별자를 선정해야 한다.
예를 들어 사원이동 엔티티는 사원 엔티티로부터 상속받은 사원번호 속성과 해당 엔티티가 가지고 있는 이동일자 속성을 합해 두 속성 모두를 유니크 식별자로 선정한다. 이와 같은 현상은 1:M 과계에서 자주 발생한다.
③ 상속 식별자로 유니크 식별자를 선정하지 않는 경우
부모 엔티티로부터 상속받은 모든 속성이 자식 엔티티의 유니크 식별자로 선정되는 것은 아니다. 경우에 따라 부모로부터 상속받은 속성을 유니크 식별자로 선정하지 않고 일반 속성으로 선정하기도 한다.
이런 경우 부모로부터 상속받은 속성은 외부키(Foreign Key)로 설정된다. 이는 물리 모델에서 외부키로 설정돼야 한다. 하지만 실제 물리 모델링에서는 외부키를 설정하지 않는 경우가 대부분이다. 결국 논리 모델에서만 이렇게 표현하는 경우가 많다.
- [그림 2] 상속 Identifier를 선정하는 기준
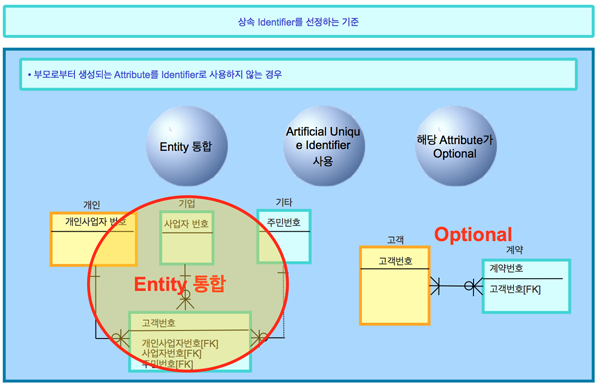
상속 식별자는 이처럼 세 가지 유형으로 나뉜다. 상속 식별자의 선정 기준은 <그림 2>와 같다. 참고로 부모 엔티티로부터 상속받은 속성이 무조건 식별자로 사용되는 것은 아니다. 부모로부터 상속받은 속성을 사용하지 않는 경우가 있는데 이를 확인해보자.
인조 유니크 식별자 사용
자식 엔티티에서 인조 유니크 식별자(Artificial Unique Identifier)를 사용할 때에는 부모로부터 상속받은 식별자는 유니크 식별자로 사용하지 않는다.
특히 부모로부터 상속받은 속성의 개수가 많은 경우 이처럼 부모로부터 상속받은 식별자 대신 인조 유니크 식별자를 정의해 사용한다.
엔티티 통합
여러 개의 유사한 엔티티가 통합될 경우 대표성을 가지는 다른 속성을 이용해 유니크 식별자를 선정할 수 있다.
해당 속성의 선택
부모로부터 상속받은 식별자가 선택적이라면 해당 속성을 자식 엔티티에서 유니크 식별자로 설정하지 못한다. 이 때에는 다른 속성을 유니크 식별자로 선정해야 한다.
식별자 속성의 위치 선정
식별자를 구성하는 속성의 순서에 따라 우리는 많은 부분을 간과하게 되지만, 이는 매우 중요하다. 데이터 모델링의 일부분인 성능을 최대한 보장하기 위해서는 인덱스 선정이 매우 중요하다. 특히 유니크 식별자는 이 성능에 많은 영향을 끼친다.
유니크 식별자 외에도 모든 식별자가 인덱스로 구현될 수 있으므로 속성의 순서도 매우 중요하다. 여기서는 연산자에 의한 순서만을 확인할 예정이다.
성능 최적화를 고려한 순서는 물리 모델링(Physical Modeling)이나 튜닝(Tuning) 과정에서 확인해보도록 하자.
유니크 식별자의 속성을 선정할 때에는 물리 모델링까지 고려해 유니크 식별자 속성의 위치를 선정해야 한다. 이는 어떻게 유니크 식별자의 속성 위치를 선정하는가에 따라 유니크 식별자를 이용하는 SQL의 처리 범위가 변할 수 있기 때문이다.
중요한 것은 점 조건으로 조회되는 속성을 가장 앞에 위치시켜야 한다는 점이다. 그 이유는 다음과 같다.
- - 점 조건 +점 조건 - 두 조건에 의해 처리 범위 감소
- - 점 조건 +선분 조건 - 두 조건에 의해 처리 범위 감소
- - 선분 조건 +선분 조건 - 앞의 선분 조건에 의해 처리 범위 감소
- - 선분 조건 +점 조건 - 앞의 선분 조건에 의해 처리 범위 감소
- [그림 3] 점 조건으로 사용된 Attribute

여기서 점 조건은 ‘=’ 또는 ‘IN’을 사용해 Where 조건절에 사용되는 속성을 의미한다.
선분 조건은 = 또는 IN을 제외한 다른 연산자를 사용하는 경우다.
그러므로 성능을 보장하기 위해서는 선분 조건+점 조건의 형태로 인덱스가 선정되서는 안 된다.
유니크 식별자를 선정하는 과정에서 이러한 사항을 모두 고려해야 한다. 물론 다른 인덱스를 선정하는 과정에서도 이러한 것들을 모두 고려해야 한다. 이러한 것들이 성능을 좌우하기 때문이다.






- 강좌 URL : http://www.gurubee.net/lecture/2870
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.