press x to close
이번 퀴즈로 배워보는 SQL 시간에는 기간 분할 검색 문제를 풀어본다. 지면 특성상 문제와 정답 그리고 해설이 같이 있다.
진정으로 자신의 SQL 실력을 키우고 싶다면 스스로 문제를 해결한 다음 정답과 해설을 참조하길 바란다. 공부를 잘하는 학생의 문제집은 항상 문제지면의 밑바닥은 까맣지만 정답과 해설지면은 하얗다는 사실을 기억하자.
[리스트 1]과 [표 1]은 시작일과 종료일 기간에 따른 금액 정보를 나타낸 리스트와 테이블입니다. 보는 것처럼 식별키(ID)와 시작일(SDT) 그리고 종료일(EDT)에 따른 금액(AMT)과 수량(CNT) 항목이 있음을 알 수 있습니다.
1 2 3 4 5 6 7 | CREATE TABLE t AS SELECT 1 id, '20120901' sdt, '20130531' edt, 6250 amt, 25 cnt FROM dual UNION ALL SELECT 2, '20130401', '20130831', 5500, 20 FROM dual UNION ALL SELECT 3, '20130501', '20140430', 5000, 15 FROM dual UNION ALL SELECT 4, '20150101', '20151231', 1000, 10 FROM dual;SELECT * FROM t; |
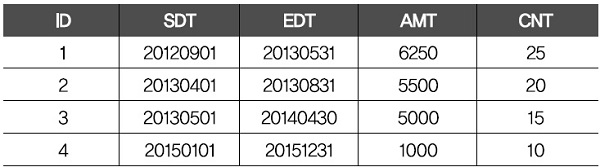
[표 1]에 있는 각 ID별 시작일과 종료일 기간의 금액과 수량 항목의 값을 이용해 기간이 서로 겹치는 구간들을 분리해 내고 또 분리된 각 구간별 금액과 수량의 합계를 [표 2]와 같은 형태의 결과 테이블로 도출하는 결과 쿼리를 작성하세요.
1 2 3 4 5 6 7 8 | SDT EDT AMT CNT---------------- ---------------- ---------- ----------20120901 20130331 6250 2520130401 20130430 11750 4520130501 20130531 16750 6020130601 20130831 10500 3520130901 20140430 5000 1520150101 20151231 1000 10 |
이번 문제에서는 기간이 서로 겹치는 구간을 따로 분리해 내고, 분리된 각 구간의 금액 및 수량을 합산해 보여주는 문제입니다.
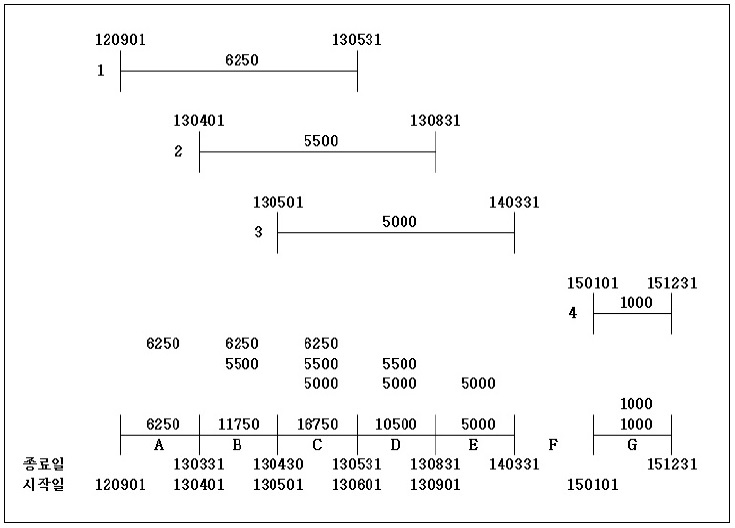
문제를 쉽게 이해할 수 있도록 도식화한 [그림 1]을 살펴보겠습니다. [그림 1]의 기간 분할 자료를 보면 위에서부터 1번 ID부터 4번 ID까지 기간정보가 시작일부터 종료일까지 선분으로 표시됩니다.
이때 4개의 기간들은 서로 겹치는 구간이 존재하게 되는데요. 이렇게 서로 겹치는 구간들을 각각 독립된 기간으로 분리합니다. 이렇게 분리된 기간을 맨 아래쪽에 있는 A부터 G까지 7개의 구간으로 표현했습니다. 각 구간별 세부 내용을 살펴보죠.
A 구간은 1번 구간의 시작일과 2번 구간의 시작일이 만나서 형성된 구간입니다. 1번 구간의 시작일인 20120901이 시작일이 되며 2번 구간의 시작일인 20130401의 하루 전일인 20130331이 종료일이 됩니다.
이 구간은 1번 구간에만 존재하므로 금액은 1번 구간의 금액인 6,250원이 됩니다. 그 다음 B 구간은 1번 구간과 2번 구간이 공존하며 이 구간의 금액은 1번 구간의 금액인 6,250원과 2번 구간의 금액인 5,500원을 더한 1만1,750원이 됩니다.
그리고 C 구간은 1번, 2번, 3번이 함께 있는 구간이 됩니다. 그 다음 D 구간은 2번과 3번이, E 구간은 3번이, F 구간은 아무것도 없는 구간이, G 구간은 4번이 됩니다.
이번 문제는 [그림 1]과 같이 서로 겹치는 구간을 분할해 [표 2]처럼 표시하는 문제입니다.
문제를 스스로 해결해 보셨나요? 이제 정답을 알아보겠습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | SELECT TO_CHAR(sdt, 'yyyymmdd') sdt , TO_CHAR(edt, 'yyyymmdd') edt , amt , cnt FROM (SELECT sdt , LEAD(sdt - 1) OVER(ORDER BY sdt) edt , SUM(SUM(amt)) OVER(ORDER BY sdt) amt , SUM(SUM(cnt)) OVER(ORDER BY sdt) cnt FROM (SELECT DECODE(lv, 1 , TO_DATE(sdt, 'yyyymmdd') , TO_DATE(edt, 'yyyymmdd') + 1 ) sdt , DECODE(lv, 1, amt, -amt) amt , DECODE(lv, 1, cnt, -cnt) cnt FROM t , (SELECT LEVEL lv FROM dual CONNECT BY LEVEL <= 2) ) GROUP BY sdt ) WHERE amt != 0; |
어떤가요? 여러분이 만들어본 리스트와 같은가요? 틀렸다고 좌절할 필요는 없답니다. 첫 술에 배부를 순 없는 것이니까요. 해설을 꼼꼼히 보고 자신이 잘못한 점을 비교해 보는 것이 더 중요합니다.
차근차근 정답에 접근해 볼까요? 우선 [리스트 2]의 정답 쿼리 중 가장 안쪽에 있는 인라인 뷰만 따로 실행해 보겠습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 | SELECT id , lv , DECODE(lv, 1 , TO_DATE(sdt, 'yyyymmdd') , TO_DATE(edt, 'yyyymmdd') + 1 ) sdt , DECODE(lv, 1, amt, -amt) amt , DECODE(lv, 1, cnt, -cnt) cnt FROM t , (SELECT LEVEL lv FROM dual CONNECT BY LEVEL <= 2) ORDER BY sdt; |
[리스트 3]의 쿼리를 이용해 [표 3]과 같은 결과를 얻었습니다.
1 2 3 4 5 6 7 8 9 10 | ID LV SDT AMT CNT-------- ---------- ------------ ---------- ---------- 1 1 01-SEP-12 6250 25 2 1 01-APR-13 5500 20 3 1 01-MAY-13 5000 15 1 2 01-JUN-13 -6250 -25 2 2 01-SEP-13 -5500 -20 3 2 01-MAY-14 -5000 -15 4 1 01-JAN-15 1000 10 4 2 01-JAN-16 -1000 -10 |
결과가 다소 생소하죠? 지금부터 왜 이런 결과를 도출해 냈는지 살펴보겠습니다.
1 | (SELECT LEVEL lv FROM dual CONNECT BY LEVEL <= 2) |
이 구문은 DUMMY 테이블을 두 건 만들어 내는 구문입니다. 이 두 건의 더미 집합을 이용해 원본 집합을 두 배로 늘릴 수 있게 됩니다.
[표 3]을 보면 ID 1번인 자료가 LV 1과 2 이렇게 두 건이 된 걸 확인할 수 있습니다. 이 때 LV 값에 따라 보여주는 자료가 다른 것을 확인 할 수 있습니다.
LV값이 1인 경우 시작일과 금액 그리고 수량을 가져오며 2인 경우엔 종료일에 1을 더한 값과 마이너스 금액 그리고 마이너스 수량을 가져옵니다. 왜 이렇게 하는지 전혀 감이 안 오신다구요?
[그림 1]을 다시 한 번 살펴보면서 설명 드리겠습니다. [그림 1]을 보면 최종결과 구간의 시작일과 종료일은 각각 원본 구간의 시작일과 종료일로 이뤄진다는 걸 알 수 있습니다.
따라서 이 시작일과 종료일 두 개 값을 두 개의 행으로 분리해 하나의 시작일자를 나타내는 항목으로 변환한 것이죠. 그리고 종료일까지는 원본 값이 유효하고 종료일 다음날부터 원본 값이 빠져나간다는 의미를 나타내고자 종료일 다음날 마이너스 금액을 표시한 것입니다.
지금까지의 내용은 통장의 입출금 내역과 비교하시면 이해하기 쉬울 듯합니다. 예를 들어 2012년 9월 1일에 6,250원이 입금됐다가 2013년 6월 1일 6,250원이 출금된 형태입니다. 이때 잔고를 보면 2012년 9월 1일부터 2013년 5월 31일까지 6,250원이었다가 6월 1일에 6,250원이 빠져나가는 형태가 되는 셈입니다.
이렇게 ‘선분 형태’의 기간 정보를 가진 원본 집합을 ‘점 형태’의 입출금 내역으로 바꾼 것입니다. 따라서 은행의 입출금 내역은 점 형태의 자료죠. 그렇다면 잔액은 어떻게 계산될까요? 입출금 금액을 일자 순서대로 누적해 합산하면 되겠지요.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | SELECT sdt , LEAD(sdt - 1) OVER(ORDER BY sdt) edt , SUM(amt) amt0 , SUM(SUM(amt)) OVER(ORDER BY sdt) amt , SUM(SUM(cnt)) OVER(ORDER BY sdt) cnt FROM (SELECT DECODE(lv, 1 , TO_DATE(sdt, 'yyyymmdd') , TO_DATE(edt, 'yyyymmdd') + 1 ) sdt , DECODE(lv, 1, amt, -amt) amt , DECODE(lv, 1, cnt, -cnt) cnt FROM t , (SELECT LEVEL lv FROM dual CONNECT BY LEVEL <= 2) ) GROUP BY sdt; |
[리스트 4]의 쿼리를 이용해 [표 4]라는 결과를 얻었습니다.
1 2 3 4 5 6 7 8 9 10 | SDT EDT AMT0 AMT CNT------------ ------------ ---------- ---------- ----------01-SEP-12 31-MAR-13 6250 6250 2501-APR-13 30-APR-13 5500 11750 4501-MAY-13 31-MAY-13 5000 16750 6001-JUN-13 31-AUG-13 -6250 10500 3501-SEP-13 30-APR-14 -5500 5000 1501-MAY-14 31-DEC-14 -5000 0 001-JAN-15 31-DEC-15 1000 1000 1001-JAN-16 -1000 0 0 |
이런 경우 하루에도 여러 번 입출금이 가능하겠지요? 하지만 우리가 원하는 최종결과는 일자 구간으로 중복된 일자는 한 번만 보여줘야 하므로 GROUP BY를 이용해 중복일자를 제거하면서 SUM 함수를 이용해 금액을 합산하면 해결될 것 같습니다. [표 4]의 SDT와 AMT0이 이에 해당합니다.
작일의 종료일은 어떻게 구할까요?
1 | , LEAD(sdt - 1) OVER(ORDER BY sdt) edt |
다음 시작일의 하루 전날이 바로 종료 일자가 되는 것이죠. 분석함수인 LEAD 함수를 이용해 다음 행의 정보를 가져올 수 있습니다. [표 4]의 일자별 합계인 AMT0 값을 일자별로 누적해 합산한 AMT 값은 어떻게 될까요?
1 | , SUM(SUM(amt)) OVER(ORDER BY sdt) amt |
분석함수 SUM() OVER()를 통해 구할 수 있습니다. 좀더 자세히 설명하면, 분석함수인 SUM 안에 집계함수인 SUM이 들어간 형태입니다. 이렇게 시작일과 종료일 금액 및 수량 값을 구했습니다.
우리가 원하는 정답에 가까워졌네요. 그리고 [리스트 4]의 쿼리를 한 번 더 인라인 뷰로 감싸 금액이 0인 행만 제거한다면 정답이 완성됩니다.
1 2 3 4 | SELECT * FROM ( [리스트 4] ) WHERE amt != 0; |
이번 퀴즈로 배우는 SQL 시간에는 기간 분할 검색 문제를 풀어보았는데요. 이번 문제를 풀기 위한 여러 가지 팁들이 있었습니다. 정리해 보겠습니다.
우선 하나의 행에 있던 두 개의 일자를 두 개 행의 하나의 일자로 변경했습니다. 이 때 더미 테이블을 이용해 행을 복제해 DECODE문과 함께 사용했고요. 종료일에 1을 더한다거나 시작일에 1을 빼는 등 중간 과정에서 날짜 계산이 빈번하게 사용됐습니다. 이렇게 날짜 계산을 위해 TO_DATE 함수를 이용했고요.
그리고 GROUP BY SUM과 함께 분석함수인 SUM() OVER()를 중첩해 사용해 보았습니다. 이는 GROUP BY SUM 따로 구해 인라인 뷰로 감싸고 밖에서 다시 분석함수를 사용하는 복잡한 수고를 덜어주는 방법이지요.
이런 여러 가지 유용한 방법들을 하나로 접목시켜 문제를 해결했습니다만 이 방법들은 그저 문제를 풀기 위한 수단에 불과하구요. 이 문제의 핵심은 ‘문제를 어떻게 논리적으로 풀어내야 하는가?’ 입니다.
이번 문제 풀이의 핵심은 바로 선분 형태의 기간에 따른 금액 정보를 점 형태의 일자별 입출금내역 정보로 변환한 뒤, 분석함수를 이용해 다시 선분 형태의 기간 정보로 표현하는 것입니다.
- 강좌 URL : http://www.gurubee.net/lecture/2848
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.