press x to close
이번 퀴즈로 배워보는 SQL 시간에는 윈도우의 기본 게임인 지뢰찾기 게임의 모양을 만들어내는 SQL을 작성하는 문제를 풀어본다. 지면 특성상 문제와 정답 그리고 해설이 같이 있다.
진정으로 자신의 SQL 실력을 키우고 싶다면 스스로 문제를 해결한 다음 정답과 해설을 참조하길 바란다. 공부를 잘하는 학생의 문제집은 항상 문제지면의 밑바닥은 까맣지만 정답과 해설지면은 하얗다는 사실을 기억하자.
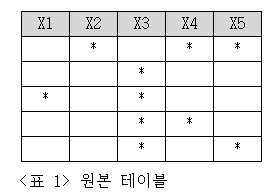
원본 테이블인 [표 1]에는 5×5 크기의 테이블에 * 모양의 지뢰가 총 10개 배치돼 있습니다.
문제 1 : [표 1]과 같이 10개의 지뢰를 무작위로 배치하는 SQL을 작성하세요.
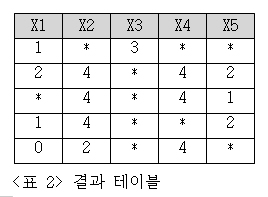
문제 2 : [표 1]의 결과를 이용해 [표 2]의 결과를 얻을 수 있는 SQL을 작성하세요.
이번 문제는 윈도우 게임의 지뢰찾기처럼 지뢰를 임의로 배치하고, 지뢰가 없는 칸에는 해당 칸 주변에 배치된 지뢰 수를 표시해 주는 문제입니다. 이 문제에는 두 가지 조건이 있습니다.
조건 1 : 5행 5열의 테이블 총 25칸 중 10 칸에 지뢰를 임의로 채우세요. 단, SQL을 실행 할 때마다 지뢰 배치가 변경돼야만 합니다.
조건 2 : 지뢰가 배치되지 않은 칸에는 해당 칸 주변에 있는 지뢰 수를 표시해야 합니다.
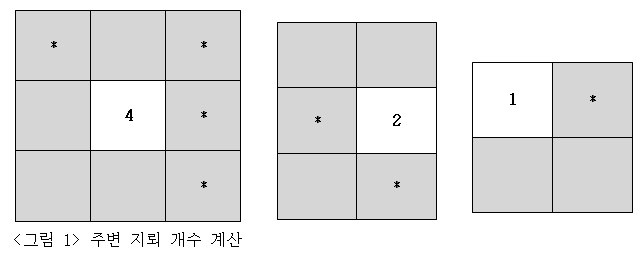
[그림1]은 빈칸에 표시할 지뢰의 수를 세는 방법을 설명하고 있습니다. 첫 번째 빈칸은 주위에 8칸이 있습니다. 이 8칸에 들어있는 지뢰의 총 개수는 4개 입니다. 두 번째 빈칸을 볼까요? 테이블 중앙이 아닌 우측면 중앙에 위치한 빈칸은 5개의 칸으로 둘러싸여 있으며 이 중 두 곳에 지뢰가 존재합니다.
세 번째 빈칸은 테이블 모서리 좌측 상단에 위치해 있으며, 지뢰 개수는 다행히 한 개네요. 만일 지뢰가 한 개도 없을 경우에는 0이라고, 주변이 모두 지뢰로 둘러 쌓여 있을 경우에는 8로 표시가 된다는 걸 알 수 있습니다.
문제를 스스로 해결해 보셨나요? 이제 정답을 알아보겠습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | WITH mine AS(SELECT MIN(DECODE(x, 1, z)) x1 , MIN(DECODE(x, 2, z)) x2 , MIN(DECODE(x, 3, z)) x3 , MIN(DECODE(x, 4, z)) x4 , MIN(DECODE(x, 5, z)) x5 FROM (SELECT CEIL(LEVEL / 5) x , MOD(LEVEL-1, 5) + 1 y , CASE WHEN ROW_NUMBER() OVER( ORDER BY dbms_random.value) < = 10 THEN '*' END z FROM dual CONNECT BY LEVEL < = 25 ) GROUP BY y)SELECT NVL(x1, SUM(NVL(LENGTH( x1||x2), 0)) OVER(ORDER BY 1 ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING)) x1 , NVL(x2, SUM(NVL(LENGTH(x1||x2||x3), 0)) OVER(ORDER BY 1 ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING)) x2 , NVL(x3, SUM(NVL(LENGTH(x2||x3||x4), 0)) OVER(ORDER BY 1 ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING)) x3 , NVL(x4, SUM(NVL(LENGTH(x3||x4||x5), 0)) OVER(ORDER BY 1 ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING)) x4 , NVL(x5, SUM(NVL(LENGTH(x4||x5 ), 0)) OVER(ORDER BY 1 ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING)) x5 FROM mine; |
어떤가요? 여러분이 만들어본 리스트와 같은가요? 틀렸다고 좌절할 필요는 없답니다. 첫 술에 배부를 순 없는 것이니까요. 해설을 꼼꼼히 보고 자신이 잘못한 점을 비교해 보는 것이 더 중요합니다.
5행 5열의 테이블 25칸 중 10곳에 지뢰를 임의로 채우는 방법부터 살펴보겠습니다. 이를 위해서는 먼저 1부터 25까지 데이터를 생성하고 이를 5×5 행렬로 변환하는 방법을 알아야 합니다.
1 2 3 4 5 | SELECT CEIL(LEVEL / 5) x , MOD(LEVEL-1, 5) + 1 y FROM dual CONNECT BY LEVEL < = 25; |
1 2 3 4 5 6 7 8 9 10 11 12 | X Y------- ---------- 1 1 1 2 1 3 1 4 1 5 2 1 2 2 2 3 2 4.... |
[리스트 2]를 보면 dual 테이블에 ‘CONNECT BY LEVEL < n’라는 조건을 주고 LEVEL을 조회하면 1부터 n까지 숫자가 생성됩니다.
이렇게 생성된 LEVEL에 CEIL과 MOD 함수로 가공하면 <표 3>과 같은 X, Y 좌표를 얻을 수 있습니다. 여기서 X를 열 번호로, Y를 행 번호라고 각각 생각하면 5행 5열의 좌표가 됩니다. 물론 X 와 Y를 서로 바꿔도 문제 해결에는 전혀 지장이 없습니다.
이렇게 5행 5열로 구성된 25개 좌표가 완성됐습니다. 이번에는 이중 임의로 선정된 10개의 좌표에 지뢰를 직접 심어보죠.
1 2 3 4 5 6 7 8 9 | SELECT CEIL(LEVEL / 5) x , MOD(LEVEL-1, 5) + 1 y , CASE WHEN ROW_NUMBER() OVER( ORDER BY dbms_random.value) < = 10 THEN '*' END z FROM dual CONNECT BY LEVEL < = 25; |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | X Y Z-------- ---------- -- 4 1 * 1 5 * 4 2 * 2 5 * 1 2 * 5 2 * 4 5 * 1 1 * 2 4 * 5 5 * 3 2.... |
[표 4]의 결과를 보면 10개의 지뢰가 확인됩니다.
1 | CASE WHEN ROW_NUMBER() OVER(ORDER BY dbms_random. value) < = 10 THEN ‘*’ END z |
그리고 구문에 분석함수인 ROW_NUMBER 함수로 순위를 부여하고, 이 순위가 10보다 작은 경우에는 지뢰를 표시하도록 했습니다. 이 과정에서 순위를 구하기 위한 정렬 기준으로 dbms_random.value 함수가 사용됐음을 확인할 수 있습니다.
특히 이 함수는 랜덤 값을 반환하는 함수이므로, 이번 퀴즈의 조건인 무작위로 지뢰를 표시하는 걸 가능하게 해주는 함수입니다. 자, 이제 X, Y 좌표와 지뢰 설치 여부인 Z까지 쿼리를 이용해 구했습니다. 이렇게 구한 X, Y, Z 값을 이용해 행렬 전환 쿼리를 만들어 보도록 하겠습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | SELECT MIN(DECODE(x, 1, z)) x1 , MIN(DECODE(x, 2, z)) x2 , MIN(DECODE(x, 3, z)) x3 , MIN(DECODE(x, 4, z)) x4 , MIN(DECODE(x, 5, z)) x5 FROM (SELECT CEIL(LEVEL / 5) x , MOD(LEVEL-1, 5) + 1 y , CASE WHEN ROW_NUMBER() OVER( ORDER BY dbms_random.value) < = 10 THEN '*' END z FROM dual CONNECT BY LEVEL < = 25 ) GROUP BY y; |
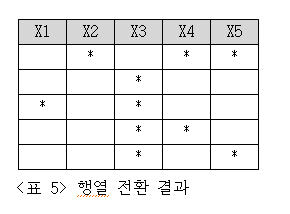
Y 좌표로 GROUP BY를 하고, DECODE 함수로 X 좌표 값에 따라 1부터 5까지 5개의 컬럼으로 나눠 Z 값을 표시한 다음 집계함수 MIN을 활용해 하나의 행으로 합쳤습니다.
이렇게 첫 번째 문제인 지뢰 표시하기를 해결하였습니다. 짝.짝.짝. 이번에는 결과 집합인 [표 5]로부터 주변 지뢰를 세는 방법을 알아보겠습니다. 두 가지 접근방법을 시도해 보겠습니다.
첫 번째는 기준이 되는 칸의 좌측과 우측 칸에 지뢰가 있는지 확인하는 방법입니다. X3 항목을 기준으로 봤을 때 좌와 우는 각각 X2와 X4입니다. 그렇다면 지뢰의 개수는 어떻게 구할까요?
1 | DECODE(x2, ‘*’, 1, 0) + DECODE(x3, ‘*’, 1, 0) + DECODE(x4, ‘*’, 1, 0) |
DECODE 문을 이용해 지뢰이면 1, 아니면 0을 반환해 해당 값을 더해서 구하는 방식입니다. 다른 방법은 없을까요? 개수를 세는 것을 꼭 덧셈으로 해야 하는 법은 없습니다.
그렇다면 어떻게 해야 할까요? 필자는 생각의 폭을 넓혀 지뢰를 나타내는 *이 그 길이가 1인 문자 데이터임을 이용해 문자열을 합한 후 길이를 측정하는 방법을 생각해 봤습니다.
1 | NVL(LENGTH(x2||x3||x4), 0) |
LENGTH 함수는 NULL에 대한 길이를 구할 때 0이 아닌 NULL을 반환하므로, 이를 보정하기 위해 NVL 함수를 사용했습니다. 훨씬 더 깔끔하게 정리가 됐네요.
두 번째는 기준이 되는 칸의 상하 칸에 지뢰가 있는지를 확인하는 방법입니다. 3번째 행의 X3을 기준으로 보면 위와 아래 행은 각각 2행의 X3과 4행의 X3이 됩니다. 분석함수를 이용해 바로 위아래 행 값을 구해 볼까요?
1 2 | , LAG(x3) OVER(ORDER BY 1) x3_prev, LEAD(x3) OVER(ORDER BY 1) x3_next |
분석함수 중 전행 값과 후행 값을 구하는 함수가 바로 LAG/LEAD입니다. 여기서 한 가지 팁을 알려드리면, 원본 집합의 결과를 그대로 이용하기 위해서는 상수 값인 1을 준 다음 정렬해야 합니다. 왜냐하면 ORDER BY 구문은 LAG/LEAD 구문에서는 필수 구문이기에 생략할 수 없습니다.
따라서 무의미한 상수 값을 부여함으로써 원본 집합의 정렬결과를 그대로 이용할 수 있게 됩니다. 이렇게 구한 값을 앞에서처럼 문자열을 붙여 길이를 구하는 방식으로 구해볼까요?
1 | NVL(LENGTH(LAG(x3) OVER(ORDER BY 1) || x3 || LEAD(x3) OVER(ORDER BY 1)), 0) x3 |
상당히 복잡하네요. 다른 방법을 생각해 봤습니다.
1 | , COUNT(x3) OVER(ORDER BY 1 ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) x3 |
분석함수 구문에서 범위를 한정하는 ROWS BETWEEN 구문을 적용한 것입니다. 기준 행으로부터 1행 전과 1행 후까지의 X3 값을 COUNT하는 구문이네요. 만일 X3이 NULL이라면 자연스럽게 세는 것에서 제외됩니다. 이렇게 상하와 좌우 셈을 따로 구했는데, 이를 하나로 접목시키는 방법은 없을까요?
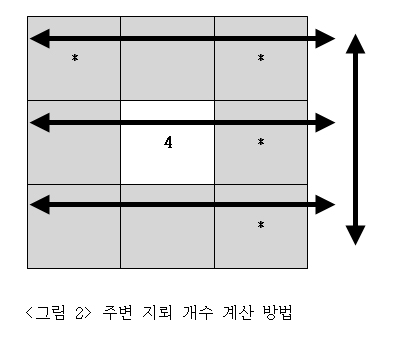
[그림2]는 앞서 구한 두 가지 방법을 하나로 접목시키는 방법을 도식화한 것입니다. 우선 가로측 화살표 방향으로 문자열을 합쳐 길이를 구합니다. 그리고 가운데 행을 기준으로 위와 아래 행도 마찬가지 방법으로 구합니다. 이렇게 구한 3개 행의 값을 세로 화살표 방향으로 합산합니다. 이를 수식으로 표현하면 다음과 같습니다.
1 2 3 4 | , NVL(x3, SUM(NVL(LENGTH(x2||x3||x4), 0))OVER(ORDER BY 1ROWS BETWEEN 1 PRECEDINGAND 1 FOLLOWING)) x3 |
X3의 좌우 컬럼인 X2와 X4를 문자열로 붙여서 길이를 구하고, 이렇게 구한 값을 ROWS BETWEEN 구문을 이용해 합산했습니다. 마지막에는 NULL 값 보정을 위해 NVL 함수를 사용합니다. X3와 마찬가지로 X1, X2, X4, X5도 함께 구해보면 정답 쿼리인 [리스트 2]가 완성됩니다.
이번 시간에는 하나의 문제 안에 여러 가지 응용문제가 녹아 들어있는 퀴즈를 풀어봤습니다. 각각 나눠 설명해보면,
그리고 마지막으로 이를 통합해 전체 문제를 해결하는 과정을 살펴봤습니다. 이번 퀴즈를 통해 배우는 SQL 시간이 복잡한 문제에 대한 해결능력을 키우는 계기가 됐으면 하는 바람입니다.
- 강좌 URL : http://www.gurubee.net/lecture/2836
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.
ㅠ_ ㅠ 답을 먼저 봤네요... OTL
다음에는 답을 숨기고, 풀이 이벤트로 해서 가장 가까이 풀이를 한 사람 채택해주시면 안될까영.. = ㅁ =)/
적극 참여하겠습니다!! 와 지뢰찾기 알고리즘을 SQL로.. = ㅅ = 프로그래머 입장에서는 굉장히 재미난 해석인 것 같습니다. 좋은 강좌 감사합니다!!!
부족한게 많지만 이렇게, 저렇게 해보았습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | select LEVEL LV, case when dbms_random.value > dbms_random.value and dbms_random.value < dbms_random.value then '*' else null end X1, case when dbms_random.value > dbms_random.value and dbms_random.value < dbms_random.value then '*' else null end X2, case when dbms_random.value > dbms_random.value and dbms_random.value < dbms_random.value then '*' else null end X3, case when dbms_random.value > dbms_random.value and dbms_random.value < dbms_random.value then '*' else null end X4, case when dbms_random.value > dbms_random.value and dbms_random.value < dbms_random.value then '*' else null end X5from dualconnect by LEVEL <= 5 |
[문제 1]을 위 처럼 작성을 했습니다. - 10개를 만드는 방법을 모르겠습니다. -
[문제 2]을 풀기 위해서 행의 LEVEL 값이 열에도 필요하다는걸 생각이 들었고,
셀프조인, 크로스조인을 해가면서 한땀한땀 패턴을 찾아 해매다가.
크로스조인에서 정렬을 하던중 배열구조가 생각이 니서 [5 x 5] 의 구조를 나열 할 생각을 했습니다.
---------
그래서
1 2 3 4 5 6 7 8 9 10 11 | create table t asselect LEVEL LV , decode(mod(LEVEL, 5), 0, 5, mod(LEVEL, 5)) X , ceil(LEVEL / 5) Y ,case when dbms_random.value > dbms_random.value and dbms_random.value < dbms_random.value then '*' else null end RVfrom dualconnect by LEVEL <= 25 |
그리고
1 2 3 4 5 6 7 8 9 | select A.LV, A.X, A.Y, count(*)from t A, t Bwhere A.RV is NULLand ((A.Y = (B.Y -1)) or (A.Y = (B.Y)) or (A.Y = (B.Y + 1)))and ((A.X = (B.X -1)) or (A.X = (B.X)) or (A.X = (B.X + 1)))and B.RV is not NULLgroup by A.LV, A.X, A.Yorder by A.Y, A.X |
각 NULL 범위 안에 '*'을 구할 수 있는 쿼리를 작성을 했고요
그리고
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | create table j asselect A.LV, A.X, A.Y, nvl(decode(A.RV, NULL, to_char(B.CNT), A.RV), 0) TMP0from T A, (select A.LV, A.X, A.Y, count(*) CNTfrom t A, t Bwhere A.RV is NULLand ((A.Y = (B.Y -1)) or (A.Y = (B.Y)) or (A.Y = (B.Y + 1)))and ((A.X = (B.X -1)) or (A.X = (B.X)) or (A.X = (B.X + 1)))and B.RV is not NULLgroup by A.LV, A.X, A.Y) Bwhere A.LV = B.LV(+)order by A.X, A.Y |
만들고 마무리로
1 2 3 4 5 6 7 8 9 10 11 | select max(decode(A.y, 1, A.TMP0)) X1 ,max(decode(A.y, 2, A.TMP0)) X2 ,max(decode(A.y, 3, A.TMP0)) X3 ,max(decode(A.y, 4, A.TMP0)) X4 ,max(decode(A.y, 5, A.TMP0)) X5from j Agroup by A.Xorder by A.X; |
여기서는 행과 열이 많이 헷갈였어요.
몇몇 조건을 완료 하지 못했습니다. - * 10개를 채우는거.. 등등 -
정답 보면서 부족한 부분 배우겠습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | SELECT CASE WHEN X1 != '*' THEN TO_CHAR(DECODE(X2,'*',1,0) + DECODE(LAG(X1) OVER(ORDER BY LV),'*',1,0) + DECODE(LAG(X2) OVER(ORDER BY LV),'*',1,0) + DECODE(LEAD(X1) OVER(ORDER BY LV),'*',1,0) + DECODE(LEAD(X2) OVER(ORDER BY LV),'*',1,0)) ELSE X1 END X1, CASE WHEN X2 != '*' THEN TO_CHAR(DECODE(LAG(X1) OVER(ORDER BY LV),'*',1,0) + DECODE(LAG(X2) OVER(ORDER BY LV),'*',1,0) + DECODE(LAG(X3) OVER(ORDER BY LV),'*',1,0) + DECODE(X1,'*',1,0) + DECODE(X3,'*',1,0) + DECODE(LEAD(X1) OVER(ORDER BY LV),'*',1,0) + DECODE(LEAD(X2) OVER(ORDER BY LV),'*',1,0) + DECODE(LEAD(X3) OVER(ORDER BY LV),'*',1,0)) ELSE X2 END X2, CASE WHEN X3 != '*' THEN TO_CHAR(DECODE(LAG(X2) OVER(ORDER BY LV),'*',1,0) + DECODE(LAG(X3) OVER(ORDER BY LV),'*',1,0) + DECODE(LAG(X4) OVER(ORDER BY LV),'*',1,0) + DECODE(X2,'*',1,0) + DECODE(X4,'*',1,0) + DECODE(LEAD(X2) OVER(ORDER BY LV),'*',1,0) + DECODE(LEAD(X3) OVER(ORDER BY LV),'*',1,0) + DECODE(LEAD(X4) OVER(ORDER BY LV),'*',1,0)) ELSE X3 END X3, CASE WHEN X4 != '*' THEN TO_CHAR(DECODE(LAG(X3) OVER(ORDER BY LV),'*',1,0) + DECODE(LAG(X4) OVER(ORDER BY LV),'*',1,0) + DECODE(LAG(X5) OVER(ORDER BY LV),'*',1,0) + DECODE(X3,'*',1,0) + DECODE(X5,'*',1,0) + DECODE(LEAD(X3) OVER(ORDER BY LV),'*',1,0) + DECODE(LEAD(X4) OVER(ORDER BY LV),'*',1,0) + DECODE(LEAD(X5) OVER(ORDER BY LV),'*',1,0)) ELSE X4 END X4, CASE WHEN X5 != '*' THEN TO_CHAR(DECODE(LAG(X4) OVER(ORDER BY LV),'*',1,0) + DECODE(LAG(X5) OVER(ORDER BY LV),'*',1,0) + DECODE(X4,'*',1,0) + DECODE(LEAD(X4) OVER(ORDER BY LV),'*',1,0) + DECODE(LEAD(X5) OVER(ORDER BY LV),'*',1,0)) ELSE X5 END X5 FROM(SELECT CASE WHEN REGEXP_INSTR(RAN,','||TO_CHAR( (LEVEL-1)*5 + 1)||',' ) <> 0 THEN '*' ELSE ' ' END AS X1, CASE WHEN REGEXP_INSTR(RAN,','||TO_CHAR( (LEVEL-1)*5 + 2)||',' ) <> 0 THEN '*' ELSE ' ' END AS X2, CASE WHEN REGEXP_INSTR(RAN,','||TO_CHAR( (LEVEL-1)*5 + 3)||',' ) <> 0 THEN '*' ELSE ' ' END AS X3, CASE WHEN REGEXP_INSTR(RAN,','||TO_CHAR( (LEVEL-1)*5 + 4)||',' ) <> 0 THEN '*' ELSE ' ' END AS X4, CASE WHEN REGEXP_INSTR(RAN,','||TO_CHAR( (LEVEL-1)*5 + 5)||',' ) <> 0 THEN '*' ELSE ' ' END AS X5, LEVEL LVFROM(SELECT ','||LISTAGG(LV, ',') WITHIN GROUP(ORDER BY LV) ||',' RANFROM(SELECT LEVEL LV FROM DUALCONNECT BY LEVEL <= 25ORDER BY DBMS_RANDOM.VALUE)WHERE ROWNUM <= 10)CONNECT BY LEVEL <= 5) |
이건 제가 짠 쿼리입니다. 풀이는 간단 명료하네요. 많이 배워갑니다.