by axiom HWM Reorg dbms_space HWM Bump up Bump up [2015.03.06]
최근 배치 모듈에서 다수의 삭제(Delete) 작업을 수행하고, 데이터 유무를 체크하는 간단한 쿼리를 수행했는데, 5분이 넘게 결과값이 나오지 않는다는 전화 문의를 받았다. 그 개발자는 결국 7~8분을 기다리고서야 0건이라는 결과값을 확인할 수 있었다고 한다. 조회 결과가 0건임에도 왜 이렇게 수행 시간이 오래 걸린 것일까?
데이터베이스 업무를 담당하는 DBA라면 이 질문에 대한 답을 이미 알고 있을 것이다. 오라클의 세그먼트 관리에는 고수위 또는 High Water Mark(이하 HWM)이라고 불리는 메커니즘이 있다. 테이블에 데이터가 추가(Insert)될 때 세그먼트에는 할당된 블록의 집합인 익스텐트에 데이터를 적재하도록 오라클 데이터 블록 포맷을 수행한다. HWM은 이 포맷된 위치를 표시하는 역할을 하는데, 다음과 같은 특징을 가지고 있다.
- - 전체 테이블을 스캔할 때 테이블의 첫 블록에서부터 HWM까지 스캔
- - HWM은 테이블 익스텐트의 뒤로만 이동 가능(HWM Bump up)
- - Truncate, Drop을 수행할 경우 인의적으로 HWM을 앞으로 이동 가능
HWM 위치까지 데이터가 추가되면 HWM은 5의 배수로 뒤로 이동하는데, 이를 HWM Bump up이라고 한다. HWM Bump up은 많은 리소스를 사용하기 때문에 오라클은 데이터가 삭제돼도 이미 할당됐던 익스텐트를 반환하지 않고 재사용 가능한 공간으로 비워둔다. 간단한 예제를 통해 이러한 상황을 재현해보자([리스트 1] 참조).
- [리스트 1] HWM Bump up 재현 예제
-
<리스트 1> HWM Bump up 재현 예제 CREATE TABLE TAB1 ( COL1 number NOT NULL, COL2 CHAR(1000), COL3 CHAR(1000) ); INSERT /*+ APPEND */ INTO TAB1 SELECT LEVEL, TO_CHAR(LEVEL), 'COMMENT:' || TO_CHAR(LEVEL) FROM DUAL CONNECT BY LEVEL < = 200000; COMMIT; DELETE TAB1; COMMIT; ALTER SESSION SET TRACEFILE_IDENTIFIER=10046; ALTER SESSION SET EVENTS '10046 TRACE NAME CONTEXT FOREVER, LEVEL 4'; SELECT COUNT(*) FROM TAB1; COUNT(*) ---------- 0 ALTER SESSION SET EVENTS '10046 TRACE NAME CONTEXT OFF'; -- Trace 내용 call count cpu elapsed disk query current rows ------ ----- ------ ------- ------ -------- -------- -------- Parse 1 0.06 0.41 127 68 0 0 Execute 1 0.00 0.00 0 0 0 0 Fetch 2 0.79 9.95 59132 66683 0 1 ------ ------ ------ ------- ------ -------- -------- -------- total 4 0.85 10.36 59259 66751 0 1 Rows Row Source Operation ------- --------------------------------------------------- 1 SORT AGGREGATE (cr=66683 pr=59132 pw=0 time=9956923 us) 0 TABLE ACCESS FULL TAB1 (cr=66683 pr=59132 pw=0 time=9956907 us)
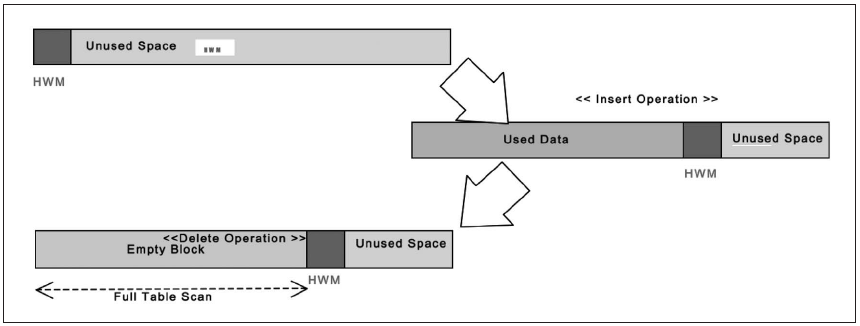
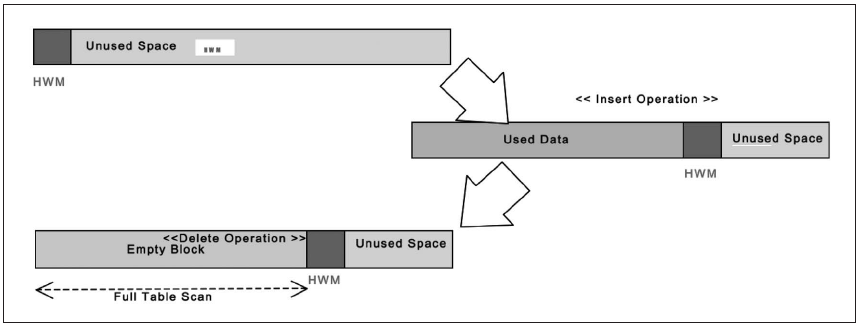
[리스트 1]의 실행결과에 주목하자. 전체 데이터가 삭제된 후 데이터 카운터를 수행하는데, 0건의 데이터 결과를 얻기까지 10초가 걸렸다. Trace를 통해 총 66751 블록은 읽었음을 확인할 수 있다([그림 1] 참조). 삭제(Delete)가 수행됐음에도 HWM의 이동이 없어 빈 블록들을 전체 스캔함에 따라 10초의 시간이 걸린 것이다.
이처럼 사용하지 않는 공간이 많으면 조회 성능이 떨어질 뿐 아니라 그 만큼 스토리지 용량도 낭비된다. 이런 비효율적인 부분들을 제거하기 위해서는 정기적으로 테이블이나 인덱스를 재구성해야 한다.
- [그림1] HWM Bump up의 동작과정
Reorg 대상은 어떻게 추출해야 할까?
수많은 오라클 서적들은 빈번하게 DML이 발생하는 테이블이나 Row Chainning/Migration이 많은 테이블이 Reorg 대상이라고 설명한다. DBA라면 담당하는 데이터베이스의 어떤 테이블에서 DML이 자주 수행되는지를 알고 있을 것이다.
그러나 해당 테이블을 Reorg 작업 대상인지 아닌지 정확히 판단할 필요가 있다. Reorg 대상을 추출하는 방법에는 다음과 같은 세 가지 방법이 있다.
- - 통계정보 데이터 이용
- - vsize 함수를 이용해 사이즈 산정
- - dbms_space 패키지 이용
통계정보 데이터를 사용해 Reorg 대상을 추출하는 것이 가장 일반적인 방법이다. 그러나 통계정보 이용은 쿼리 작성이 쉬운 이점이 있지만 최신 통계정보 데이터가 없을 경우에는 정확도가 낮은 단점이 있다.
이 대신 vsize 함수를 이용할 수도 있는데, 이 경우 합계를 구하는 쿼리 작성이 다소 복잡하다. 또한 테이블 전체를 스캔할 때 부하가 많고 테이블 전체를 스캔하는 데 많은 시간이 소요된다.
이때 유용한 기능이 바로 오라클 내장패키지 DBMS_SPACE다. 이 패키지는 오라클 10g 버전에서 제공하는데, 이를 통해 DBMS_SPACE 패키지의 VERIFY_SHRINK_CANDIDATE 프로시저를 이용해 Segment Shrink 기능에서 해당 세그먼트를 축소 가능한지 여부를 알 수 있다.
이렇듯 Reorg 대상을 추출하는 방법은 총 세 가지다. 시스템 운영 환경에 따라 적합한 방법을 선택해 사용하는 것이 바람직하다. 또한 Cluster Factor 값을 고려해 Reorg가 수행될 때 정렬을 추가해도 Reorg가 가능하다.
이를 통해 Reorg 작업을 통해 스토리지 용량을 절감하면서 SQL의 응답속도까지 향상시킬 수 있다. 이제부터는 DB 성능 향상과 스토리지 용량 절감 이 두 마리 토끼를 모두 잡는 DBA가 되도록 하자.






- 강좌 URL : http://www.gurubee.net/lecture/2816
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.