press x to close
오라클 데이터베이스를 운영하다 보면 SQL은 데이터베이스에서 관리하기 힘들다고 느낀다. 그래서 애플리케이션에서 관리해야 한다고 많이 생각하게 된다.
하지만 SQL은 오라클 인스턴스 메모리(SGA 내의 Shared pool)나 보조 테이블스페이스(SYSAUX)에 저장되고 있으며, 딕셔너리뷰를 조회해 SQL들에 대한 통계나 성능을 어렵지 않게 추출할 수 있다. 그렇다면 오라클은 이 SQL들을 어떻게 저장하는지 알아보자.
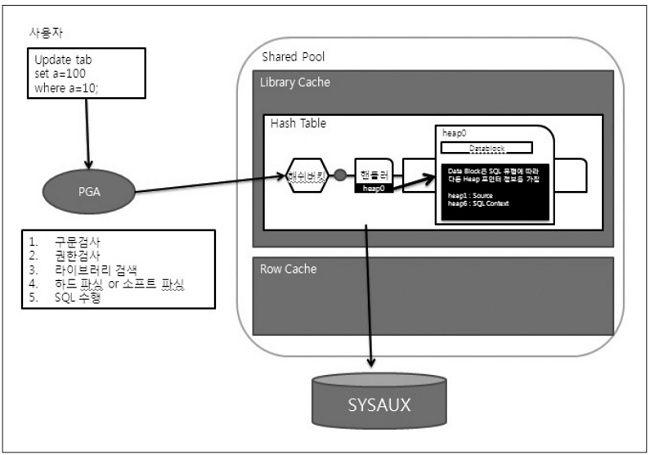
위의 일련의 과정을 통해 SQL은 오라클 데이터베이스에 저장되며, 활용할 수 있게 된다. 앞서 설명했듯이 SQL 커서정보는 메모리와 테이블스페이스에 저장되는데 테이블스페이스에 저장된 SQL 커서정보들은 데이터베이스가 종료돼도 유지된다.
하지만 메모리에 있는 커서정보는 장시간 재호출이 없거나 데이터베이스가 재기동될 때 사라진다. SQL의 저장은 메모리에 있는 온라인 정보와 테이블스페이스에 저장되는 오프라인 정보로 나누어지게 되는데, 온라인 정보는 V$SQL 등의 딕셔너리뷰를 조회해 정보를 추출할 수 있으며, 오프라인 정보는 DBA_HIST_* 뷰를 활용해 정보추출이 가능하다
앞으로 보여줄 예제들은 딕셔너리뷰, 즉 메모리 내의 정보를 이용하는 SQL을 예제로 한다. 첫 번째로 알아볼 내용은 현재 데이터베이스에서 SQL 수행속도의 분포가 어떻게 되는지 알아보는 SQL이다. [리스트 1]의 예제는 1초 미만, 3초 미만, 10초 미만 그리고 나머지 등으로 분류해 수량을 체크하는 구문이다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | SELECT CASE WHEN ELAPSED_TIME/DECODE(EXECUTIONS,0,1, EXECUTIONS) BETWEEN 0 AND 1000000 THEN 1 WHEN ELAPSED_TIME/DECODE(EXECUTIONS,0,1, EXECUTIONS) BETWEEN 1000001 AND 3000000 THEN 3 WHEN ELAPSED_TIME/DECODE(EXECUTIONS,0,1, EXECUTIONS) BETWEEN 3000001 AND 10000000 THEN 10 ELSE 99 END EXEC_TIME , ROUND(AVG(ELAPSED_TIME/DECODE(EXECUTIONS,0,1, EXECUTIONS))/1000/1000,3) AVGTIME ,COUNT(*) FROM V$SQL WHERE PARSING_SCHEMA_NAME NOT IN ('SYS','SYSTEM') GROUP BY CASE WHEN ELAPSED_TIME/DECODE(EXECUTIONS,0,1, EXECUTIONS) BETWEEN 0 AND 1000000 THEN 1 WHEN ELAPSED_TIME/DECODE(EXECUTIONS,0,1, EXECUTIONS) BETWEEN 1000001 AND 3000000 THEN 3 WHEN ELAPSED_TIME/DECODE(EXECUTIONS,0,1, EXECUTIONS) BETWEEN 3000001 AND 10000000 THEN 10 ELSE 99 END |
V$SQL은 메모리를 액세스할 수 있는 딕셔너리뷰로서, SQL에 관련된 정보를 추출할 수 있는 뷰이다. 해당 SQL은 파싱 유저 중 SYS와 SYSTEM을 제외한 SQL들을 수행속도로 분류해 결과를 표시한다.
여기서 ELAPSED_TIME이 수행속도이다. 수행속도는 CPU가 수행되는 시간과 대기시간이 더해져 만들어지는 실제 수행속도를 의미한다.
테이블을 읽기 위해 10만 블록을 읽는데, 총 10초가 걸렸다. 여기서 디스크의 I/O 속도가 느려서 메모리로 올리는 시간이 8초라면, 실제 CPU가 수행된 시간은 2초밖에 되지 않는 것이다.
두 번째로 시스템에 성능 이슈가 발생하면 보편적으로 ‘Full Scan’이라는 용어를 많이 쓰게 된다. Full Scan은 오라클 실행계획에서 세그먼트(테이블 또는 인덱스)를 읽는 방법 중 하나를 지칭하는 용어이다.
이 Full Scan은 세그먼트를 처음부터 끝까지 전부 읽는 방식으로 OLTP 환경에서 적절히 사용하지 못할 경우 시스템에 일정 부분 악영향을 주게 된다.
[리스트 2]의 구문을 이용해 실행된 SQL 중 Full Scan을 수행한 SQL에 대해 정보를 추출해 보자.
1 2 3 4 5 6 7 8 9 10 11 12 13 | SELECT /*+ ORDERED USE_NL(A SQ)*/SQL_FULLTEXT, SQ.SQL_ID , PLAN_HASH_VALUE, S.MODULE, TRUNC(CPU_TIME/DECODE(EXECUTIONS,0,1, EXECUTIONS)/1000/1000,2) AS "CPU_ONE", TRUNC(ELAPSED_TIME/DECODE(EXECUTIONS,0,1, EXECUTIONS)/1000/1000,2) AS "EPLAP", TRUNC(BUFFER_GETS/DECODE(EXECUTIONS,0,1, EXECUTIONS)/1000/1000,2) AS "BUFFER_GET" FROM (SELECT DISTINCT SQL_ID FROM V$SQL_PLAN WHERE OBJECT_OWNER NOT ('SYS','SYSTEM') AND OPTIONS LIKE '%FULL%')A ,V$SQLAREA S WHERE S.SQL_ID=A.SQL_ID; |
SQL이 처음 수행되면 옵티마이저는 최적의 경로를 찾기 위해 파싱(Parsing)을 수행하게 된다. 파싱 과정이 이뤄진 후에는 실행계획이 생성되고, 실행계획에서 SQL이 어떻게 수행돼야 하는지에 대한 정보가 들어가게 된다. 실행계획은 메모리에 저장되며, 실행계획을 추출하기 위해서 V$SQL_PLAN 딕셔너리뷰를 조회하면 된다.
V$SQL_PLAN 뷰에서 OPTIONS 컬럼은 객체를 읽는 방식을 기록한다. 이 컬럼을 이용해 LIKE 수식어로 ‘Full Scan’을 사용한 SQL_ID를 추출하고, V$SQL로 조인하게 된다.
위 구문으로 추출되는 정보는 SQL 구문, 실행계획 고유 값, 모듈명, CPU 사용시간, 수행시간, 메모리에서 발생한 I/O 블록수 등이다. 추출된 SQL은 적절한 튜닝(인덱스 생성, SQL 변경, 힌트 수정 등)으로 성능을 향상시킬 수 있다.
마지막으로 리터럴 SQL을 추출하는 방법이다. 리터럴 SQL은 바인드 변수 없이 사용된 SQL로 1회성 SQL이라 보면 된다. 리터럴 SQL은 한 번 사용된 후 재사용되지 않아 메모리 공간을 낭비하며 빈번한 하드파싱으로 성능지연의 원인이 되기도 한다.
1 2 3 4 5 6 7 8 9 | SELECT Z.* , (SELECT SQL_FULLTEXT FROM V$SQL WHERE SQL_ID=Z.SQL_ID) SQL_TEXT FROM (SELECT MAX(SQL_ID) SQL_ID, COUNT(*) CNT FROM V$SQL A WHERE FORCE_MATCHING_SIGNATURE>0 AND FORCE_MATCHING_SIGNATURE EXACT_MATCHING_SIGNATURE GROUP BY FORCE_MATCHING_SIGNATURE HAVING COUNT(*) > 20 -- SQL이 20개 이상 존재 ORDER BY 2) Z; |
비슷한 유형의 SQL이 20개 이상인 SQL을 추출하는 구문이다. 이렇게 추출된 SQL은 애플리케이션에서 바인드 변수 처리만으로 데이터베이스의 CPU 사용량을 줄이고 성능을 향상시킬 수 있다.
앞서 보듯이 손쉽게 오라클의 딕셔너리뷰를 활용해 데이터베이스에서 이뤄지는 SQL의 통계 및 성능분석이 가능해진다.






- 강좌 URL : http://www.gurubee.net/lecture/2796
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.