press x to close
by axiom FULL SCAN HWM High Water Mark Block Cleanout Direct Path Read 10949 이벤트 [2014.06.25]
온라인 서비스 기업의 DB 담당자들은 어떻게 하면 적은 비용으로 빠른 시간 안에 원하는 데이터를 추출할 수 있을지를 고민한다. 이와 같은 동기로 출발해 튜닝에 대한 관심이 높아지면서 인덱스를 활용한 최적의 성능 구현이 가능해졌다. 그러면서 기존에 CPU와 디스크의 사용률을 불필요하게 높였던 테이블 FULL SCAN은 퇴출대상 1호가 되기도 한다.
하지만 온라인 서비스 시스템도 야간 배치작업을 하는 경우가 많고 DW 용도로 사용하는 DB의 경우에는 여전히 TABLE FULL SCAN 방식은 필수적인 조회 방식이다. 이 글에서는 TABLE FULL SCAN 방식의 기본 동작원리를 이해하고 원하는 응답속도를 얻기 위해 필요한 오라클의 기능들을 알아본다.
FULL SCAN 방식은 알다시피 다중 블록단위 I/O를 수행한다. ‘db_file_multiblock_read_count’ 파라미터에 설정된 값만큼 EXTENT의 블록들을 한번의 I/O Call에 읽어 들임으로써 인덱스를 활용한 단일 블록단위 I/O보다 적은 I/O Call을 발생시킨다.
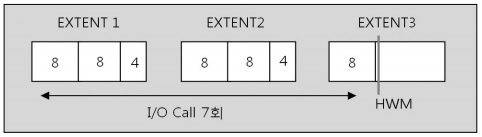
그래서 대량의 블록을 읽어야 할 경우에는 단연 FULL SCAN 방식이 유리하다. 예를 들어 살펴보면 TABLE FULL SCAN 방식은 첫 번째 EXTENT를 시작으로 HWM(High Water Mark) 표기된 지점까지 읽기를 수행하는데, [그림 1]과 같이 EXTENT가 20 Block이고 ‘db_file_multiblock_read _count’ 파라미터가 8로 설정되어 있다면 총 7번의 I/O Call 이 발생하게 된다.
여기서 특이사항은 해당 파라미터값이 아무리 높게 설정되어 있어도 EXTENT의 단위를 넘어서도록 읽을 수는 없다는 것이다.
추가로 오라클 데이터 버퍼캐시는 디스크 I/O를 줄이기 위해 최근에 사용했던 블록에 우선순위를 두는 LRU(Least Recently Used) 알고리즘을 사용한다. 하지만 본래 LRU 알고리즘의 사상대로라면 FULL SCAN 방식으로 읽힌 대량의 블록들은 LRU 리스트를 점령해 기존에 관리되던 블록들을 밀어내게 된다.
이럴 경우 데이터 버퍼캐시의 적중률이 현저하게 낮아지는데 이것을 막기 위해 오라클은 TABLE FULL SCAN의 경우에는 LRU 리스트의 우선순위가 낮은 쪽의 블록들을 할당해주고 반복 재활용하게 함으로써 TABLE FULL SCAN으로 인한 악영향을 최소화한다.
대용량 테이블의 경우에 단일 프로세스에 의한 TABLE FULL SCAN 방식은 원하는 응답속도를 얻기 힘들다. 그래서 오라클은 병렬 스캔 방식을 지원하고 있으며 데이터베이스, 오브젝트, SQL 레벨별로 병렬도를 지정하고 원하는 만큼의 자원을 배정해 병렬 스캔을 수행할 수 있다.
[리스트 1]의 예제와 같이 PARALLEL 힌트를 병렬도 4로 사용할 경우 해당 테이블을 ROWID 기준으로 작업량을 나누어 4개의 프로세스가 병렬 읽기 작업을 수행한다. 전체 테이블 세그먼트를 1/4로 나누는 것은 아니며 본인의 작업량을 모두 마치면 새로이 작업량을 할당 받아서 처리하는 방식으로 진행된다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | 세션1> SELECT /*+ PARALLEL(B 4) */ * FROM SOURCE B;세션2> SELECT SID, SERIAL#, OPNAME, TARGET, START_TIME, SOFAR, TOTALWORK, SOFAR/TOTALWORK*100 RATIO FROM V$SESSION_LONGOPS;SID SERIAL# OPNAME TARGET START_TIME SOFAR TOTALWORK RATIO----- ------ ----------------- ------ --------------- ----- --------- -----4522 63785 Rowid Range Scan SOURCE 2012-07-24 9:40 10242 10242 1005492 31501 Rowid Range Scan SOURCE 2012-07-24 9:41 10242 10242 1002685 27487 Rowid Range Scan SOURCE 2012-07-24 9:42 10242 10242 1007836 25723 Rowid Range Scan SOURCE 2012-07-24 9:43 5958 10243 58.164522 63785 Rowid Range Scan SOURCE 2012-07-24 9:43 5932 10242 57.915492 31501 Rowid Range Scan SOURCE 2012-07-24 9:43 6251 11197 55.82 |
SELECT SQL을 수행할 때 ‘latch: row cache objects’ 이벤트가 다량으로 발생하면서 조회 속도가 매우 느려지는 상황이 발생할 수 있다. 이것은 오라클이 Delayed Block Cleanout 방식을 사용하기 때문에 발생하는 현상이다.
오라클은 DML 수행 후에 commit되면 관련된 블록의 락 해제 및 ITL 정보를 갱신하는 작업을 진행한다. 이 작업을 Block Cleanout이라고 한다.
하지만 대량의 DML 작업 후에 이 작업을 수행할 경우 엄청난 부하가 발생할 수 있기 때문에 오라클은 Commit 시에 블록에 대한 변경 작업을 미루고 차후에 해당 블록을 디스크에서 버퍼캐시로 적재하는 시점에 변경하는 방식(Delayed Block Cleanout)을 사용하고 있다.
이 작업을 수행하기 위해 dc_ rollback_segments 영역을 빈번하게 참조하게 되는데, 이때 발생하는 이벤트가 ‘latch: row cache objects’이다.
이러한 원리 때문에 온라인 서비스 시스템에서 간혹 업무시간 동안 발생한 DML에 대한 블록 클린아웃이 새벽 배치작업 시간에 수행되어 배치작업이 제시간에 끝나지 않는 상황이 발생한다.
이 문제를 해결하기 위해서는 다음 예제와 같이 관련 테이블에 대해 TABLE FULL SCAN을 수행해 미리 블록 클린아웃을 수행하는 것이 좋다.
1 | SELECT /*+ FULL(A) */ * FROM TARGET_TABLE A; |
11g부터는 이와 같은 Serial TABLE FULL SCAN도 특정 기준에 부합하면 버퍼캐시를 통하지 않는 Direct Path Read 방식을 자동으로 사용한다. 만약 이 기능이 자동으로 작동된다면 위의 SQL은 해결방법이 될 수 없다.
블록 클린아웃을 수행하기 위해서는 버퍼캐시를 통한 Conventional Path Read 방식을 반드시 사용해야 하기 때문이다. 오라클 11g부터는 다음의 우선순위로 Serial Direct Path Read 여부를 결정한다.
1) Table의 크기에 따라 SMALL, MEDIUM, LARGE, VERY LARGE Table로 구분해 각 조건별로 수행
2) Event 10949 설정 여부
결론적으로 Serial Direct Path Read 기능을 활용하면서 원하는 대로 컨트롤하려면 '_serial_direct_path_read= AUTO'로 설정하고 세션별로 기능을 사용하고 싶지 않은 경우에는 '_small_table_threshold' 값을 크게 설정하고 10949 이벤트를 사용한다.






- 강좌 URL : http://www.gurubee.net/lecture/2778
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.