press x to close
by axiom Redo Log Buffer Oracle Internals Direct Insert NOLOGGING APPEND PARALLEL [2014.02.22]
데이터베이스 인터널은 매우 깊은 내용을 의미한다. 시대가 흐르면서 데이터가 크게 증가해 지금은 대용량 데이터베이스가 속출하는 시대가 되었다. 이와 같이 데이터가 증가하면 우리가 분석하기 힘든 많은 현상들이 발생하게 된다.
이와 같은 현상을 정확히 이해하고 분석하기 위해서는 데이터베이스의 내부를 이해해야 하며 그렇기 때문에 데이터베이스 인터널이 필요하게 되는 것이다.
데이터베이스를 운영하다 보면 많은 양의 로그가 발생하는 것을 확인할 수 있다. 이는 아마도 많은 DML이 수행되기 때문이다.
DML이 발생하게 되면 오라클은 로그 Ahead에 의해 반드시 로그를 생성해야 한다. 이런 부분에서 데이터베이스 성능은 저하될 수 있다. 이 글에서는 이와 같이 발생하는 로그를 어떻게 감소시킬 수 있는지에 대해 확인해 보자.
Redo를 적게 사용하는 방법을 이해하기 위해서는 데이터베이스가 Redo를 왜 적게 사용해야 하는지를 이해해야 한다.
이를 이해해야만 우리는 데이터베이스 Redo를 적게 사용하기 위해 노력하게 될 것이다. 그렇게 된다면 해당 데이터베이스는 매우 안정적으로 유지될 수 있다.
Redo를 적게 사용해야 하는 것은 바로 성능 때문이다. Redo를 기록한다는 것은 I/O를 의미하며 이와같은 I/O가 증가하면 성능 저하가 발생하게 된다. 그렇기 때문에 동일한 작업을 수행하면서도 Redo를 적게 사용한다면 보다 향상된 성능을 기대할 수 있다.
또한 Redo Log Buffer의 내부 구조를 지금까지 확인해 봤듯이 로그를 많이 생성하게 되면 Redo Log Buffer의 모든 항목들은 경합이 발생할 수 있게 되고 로그를 적게 생성한다면 Redo Log Buffer의 알고리즘에는 어떠한 문제도 발생하지 않게 된다.
그렇기 때문에 Redo Log Buffer를 효과적으로 사용하기 위해서는 생성하는 Redo의 양을 감소시키는 것이 매우 중요하다. 이와 같이 I/O를 발생시키는 Redo를 적게 사용하는 방법은 다음과 같다.
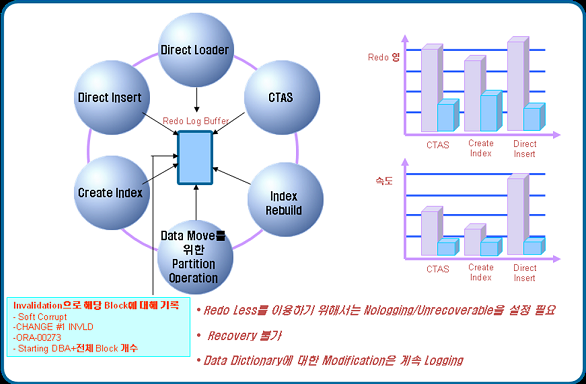
Redo를 적게 사용하는 여러 방법 중 Direct Insert에 대해 확인해 보자.
Direct Insert는 데이터를 Insert하는 경우 APPEND 또는 PARALLEL 힌트를 이용하는 것을 의미하며 다음과 같이 수행 한다면 Direct Insert가 아닌 Conventional Insert로 수행되어 많은 로그가 발생할 수 있다.
1 2 | INSERT INTO DEPT_TESTSELECT * FROM DEPT; |
위와 같이 수행되는 Convention Insert를 다음과 같이 로그를 이용하지 않는 Direct Insert로 변경할 수 있다.
1 2 3 4 5 6 | -- 테이블을 NOLOGGING 으로 변경ALTER TABLE DEPT_TEST NOLOGGING;-- APPEND 힌트를 사용하여 INSERTINSERT /*+ APPEND */ INTO DEPT_TESTSELECT * FROM DEPT; |
위와 같이 수행해 Insert를 Direct Insert로 변경할 수 있으며 테이블을 Nologging으로 변경했기 때문에 Redo는 매우 적은 양이 생성된다. 위의 Direct Insert는 다음과 같이 변경할 수도 있다.
1 2 3 4 5 6 | ALTER SESSION ENABLE PARALLEL DML;ALTER TABLE DEPT_TEST NOLOGGING;INSERT /*+ PARALLEL(A 4) */ INTO DEPT_TEST ASELECT * FROM DEPT; |
위와 같이 수행해도 해당 SQL은 Direct Insert가 수행된다. 하지만 위의 SQL은 Direct Insert를 수행하면서 Parallel Processing을 이용하게 된다.
Direct Insert를 수행하며 Redo를 최소로 생성하기 위해서는 다음 사항에 주의해야 한다.
아무리 Direct Insert를 수행해도 테이블이 Nologging으로 변경되지 않았다면 Insert에 대한 Redo를 생성하게 된다.
하지만 기존 Conventional Insert와는 다르게 수행된다. 테이블을 Nologging으로 변경 없이 Insert를 수행하게 되면 블록 단위 덤프 형식으로 로그를 기록하게 된다.
Nologging 없이 Direct Insert를 수행하게 되면 HWM 위의 블록들에만 데이터가 저장되고 HWM 위에 기록된 블록들은 모두 Insert가 수행된 블록이 된다.
이와 같이 블록에 대해 새로 Insert된 데이터가 구분되기 때문에 일반 로그보다는 성능이 향상된 블록 단위 덤프를 수행하게 된다.
블록 단위 덤프는 Nologging보다는 많은 로그를 작성하지만 일반 Conventional Insert보다는 빠르게 로그를 기록하게 된다. 이와 같은 Direct Insert는 추가적인 혜택이 있게 된다.
이는 UNDO의 기록이다. 테이블이 Nologging이던 Nologging이 아니던 Direct Insert는 UNDO를 한 블록만 기록하게 되고 해당 UNDO 블록에는 HWM의 정보만을 저장하게 된다.
따라서 Nologging과 Direct Insert를 사용하게 되면 적은 Redo 생성과 한 블록의 UNDO 블록을 사용하게 되어 최적의 성능을 보장할 수 있게 된다.
그러므로 Direct Insert를 사용할 수 있는 업무에서는 반드시 Direct Insert를 이용하는 것이 유리하다.






- 강좌 URL : http://www.gurubee.net/lecture/2692
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.
감사합니다