press x to close
01 > ROWID 로 1 로우 액세스
02 > 클러스터 조인에 의한 1 로우 액세스
03 > Unique HASH Cluster 에 의한 1 로우 액세스
04 > Unique Index 에 의한 1 로우 엑세스
05 > Cluster 조인
06 > Non Unique Hash cluster key
07 > Non Unique cluster key
08 > Non Unique 결합 인덱스
09 > Non unique 한 컬럼 인덱스
10 > index 에 의한 범위처리
11 > index 에 의한 전체범위처리
12 > Sort Merge 조인
13 > 인덱스 컬럼의 Min, MAX 처리
14 > 인덱스 컬럼의 order by
15 > 전체테이블 스켄
SQL> create index emp_a on emp(deptno);
Index created.
SQL> create index emp_b on emp(deptno, empno);
Index created.
SQL> select /*+rule */* from emp where deptno =10 and empno between 7888 and 8888;
---------------------------------------------
| Id | Operation | Name |
---------------------------------------------
| 0 | SELECT STATEMENT | |
|* 1 | TABLE ACCESS BY INDEX ROWID| EMP |
|* 2 | INDEX RANGE SCAN | EMP_A |
---------------------------------------------
09 > Non unique 한 컬럼 인덱스 EMP_A index
10 > index 에 의한 범위처리 EMP_B index
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("EMPNO"<=8888 AND "EMPNO">=7888)
2 - access("DEPTNO"=10)
위 경우 이상적인 index를 타는 경우는 EMP_B index를 타는 것이다.
access("DEPTNO"=10 AND "EMPNO">=7888 AND "EMPNO"<=8888)
[USER|ALL|DBA]_TABLES
num_rows, blocks, avg_row_len, sample_size, last_analyzed
[USER|ALL|DBA]_INDEXES
BLEVEL ,LEAF_BLOCKS ,DISTINCT_KEYS ,AVG_LEAF_BLOCKS_PER_KEY, AVG_DATA_BLOCKS_PER_KEY, CLUSTERING_FACTOR,NUM_ROWS,SAMPLE_SIZE ,LAST_ANALYZED
[USER|ALL|DBA]_TAB_COLUMN
NUM_DISTINCT,LOW_VALUE ,HIGH_VALUE,DENSITY , NUM_NULLS ,NUM_BUCKETS , LAST_ANALYZED ,SAMPLE_SIZE ,AVG_COL_LEN
[USER|ALL|DBA]_TAB_HISTOGRAMS
OWNER , TABLE_NAME, COLUMN_NAME, ENDPOINT_NUMBER , ENDPOINT_VALUE , ENDPOINT_ACTUAL_VALUE
통계정보 중 가장 중요한 정보는 분포도 라고 할 수 있으며, 여기서 분포도가 좋다라는 것은 컬럼값의 종류가 많다는 것이며
이것은 곧 조건을 만족하는 처리 범위가 좁다는 의미하므로 일의 양을 결정하는 중요한 요소 이다.
여기서 문제는 분포도 라는 정보가 결합인덱스 또는 다양한 연산자를 사용하는 경우 불완전한 분포드 정보가 나올 가능성이 높다는 점이다.
모든 컬럼 값에 대해 분포도를 가지기에는 어려움이 있으므로 값을 저장하는 방식에는 두가지 있다.
넓이 균형 히스토그램(Width_balanced Histogram) : 값(Value)의 Distinct Count와 Bucket 수가 일치하는 경우 정확한 컬럼 개수 값을 가지고 있다.
높이 균형 히스토그램(Height_balanced Histogram) : 값(Value)의 Distinct Count가 Bucket 수보다 많은 경우 값마다 Bucket을 하나씩 할당
할 수 없으므로 값들을 적당한 Bucket으로 분배
-- 참조 : 2011년 상반기 대용량데이터베이스 스터디 Frequency vs. Height-Balanced (작성자 : 노준기)
통계정보를 관리 함으로서 테이블을 모니터링 할 수가 있다. Insert, update, delete 에 대한 발생 정보를 개략적으로 모니터링 가능.
통계정보관리는 제공된 프로시져를 이용하여 관리하는 것이 좋다.
시스템의 CPU, I/O 성능, 메모리성능, 등 성능에 따른 변수가 있을 수 있으므로 시스템 통계를 측정하여 좀 더 정확한
정보를 옵티마이져에게 제공함으로써 좀 더 정확한 통계정보를 가질 수 있다.
시스템 통계정보는 지정한 기간동안 시스템을 모니터링 함으로써 측정하는 부분이다.
(일반적으로 업무시간을 위주로 어느정도 시간의 Delta 값을 측정하는지..)
SYSTEM 통계 정보_info
select * from aux_stats$;
수집
SQL> exec dbms_stats.gather_system_stats(gathering_mode => 'START');
~~~~ 이 시기 동한 발생된 워크로드를 분석해서 aux_stats$ 반영
SQL> exec dbms_stats.gather_system_stats(gathering_mode => 'STOP');
삭제
SQL> exec dbms_stats.delete_system_stats();
- 통계 정보 수집하는 경우 주의점은 Sample Data 의 양이다.
일반적으로 5% 이하 선정하는데 바람직하다고 한다. 하지만 데이터 양의 따라 제약조건이 있으므로 검토가 필요.
Analyze & DBMS_STAT 차이점
Analyze | Serial statistics gathering 기능
전체 클러스터 테이블에 대한 통계정보 수집 가능
각 테이블 파티션, 인덱스에 대해서 수집하고 , Global statistics 는 파티션 정보를 가지고 계산( 비정확 )
Analyze 에서만 가능한 기능.
Structural integrity check ( analyze (index/table/cluster) (schema.)(index/table/cluster) validate structure (cascade)(into schema table)
Chained rows 수집 ( analyze table order_hist list chained rows into <user_tabs> )
DBMS_STAT | Parallel statistics gathering 기능
Partition , sub partition 이 있는 경우에는 DBMS_STAT 이용
전체 클러스터 테이블에 대한 통계정보 수집 불가
DBMS_STAT 는 CBO 관련 통계만 수집. (즉 EMPTY_BLOCKS ,AVG_SPACE, CHAIN_CNT 수집 않함)
통계정보를 저장가능, 각 컬럼, 테이블, 인덱스, 스키마 반영가능
DBMS_STAT import /export 가능
Oracle 10.2.0.4 통계정보에 DBMS_STATS Package 으로 제공.
* 통계정보를 비교시 일반적으로 현재,과거 를 비교하므로 과거의 통계정보의 백업(export)가 필요하며
자동적으로 백업되는 부분은 DBA_TAB_STATS_HISTORY View 조회된다 (10g 부터)
dbms_stats.diff_table_stats_in_stattab(user,'table1','table1_old');
exec dbms_stats.export_table_stats(user,'t1',null,'t1_stat');
exec dbms_stats.import_table_stats(user,'t1',null,'t1_stat');
SQL> exec dbms_stats.gather_table_stats('JIN','EMP');
PL/SQL procedure successfully completed.
SQL> select table_name, stats_update_time from dba_tab_stats_history where table_name = 'EMP'
TABLE_NAME STATS_UPDATE_TIME
------------------------------ ---------------------------------------------------------------------------
EMP 28-JUL-11 10.00.17.072692 PM +09:00
EMP 25-AUG-11 11.35.21.381488 AM +09:00
SQL> select OWNER,TABLE_NAME,LAST_ANALYZED from dba_tables where OWNER='JIN' and TABLE_NAME='EMP';
OWNER TABLE_NAME LAST_ANALYZE
------------------------------ ------------------------------ ------------
JIN EMP 25-AUG-11
SQL> exec dbms_stats.restore_table_stats('JIN','EMP','28-JUL-11 10.00.17.072692 PM +09:00');
PL/SQL procedure successfully completed.
SQL> select OWNER,TABLE_NAME,LAST_ANALYZED from dba_tables where OWNER='JIN' and TABLE_NAME='EMP';
OWNER TABLE_NAME LAST_ANALYZE
------------------------------ ------------------------------ ------------
JIN EMP 28-JUL-11
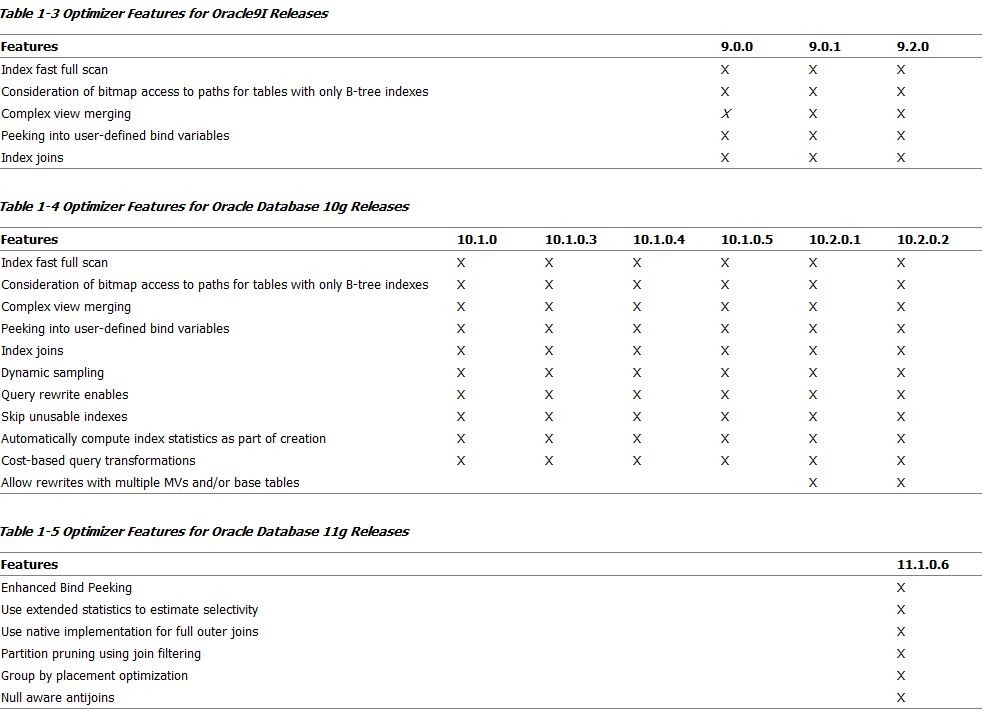
Partitioned tables
Index-organized tables
Reverse key indexes
Function-based indexes
SAMPLE clauses in a SELECT statement
Parallel execution and parallel DML
Star transformations
Star joins
Extensible optimizer
Query rewrite (materialized views)
Progress meter
Hash joins
Bitmap indexes
Partition views (release 7.3)
Hint
Parallel DEGREE & INSTANCES - 'DEFAULT'도 해당
PARAMETERS TO CHANGE 11.2.0.1 TO 11.1.0.7 [ID 1096377.1]
These are the parameters that are changed when setting optimizer_features_enable=11.1.0.7 in 11.2.0.1 database.
These values represent OFE=11.1.0.7
alter session set "_optimizer_coalesce_subqueries" = false ;
alter session set "_optimizer_distinct_placement" = false ;
alter session set "_optimizer_unnest_disjunctive_subq" = false ;
alter session set "_optimizer_unnest_corr_set_subq" = false;
alter session set "_optimizer_distinct_agg_transform" = false;
alter session set "_optimizer_fast_pred_transitivity" = false ;
alter session set "_optimizer_fast_access_pred_analysis" = false;
alter session set "_aggregation_optimization_settings" = 32 ;
alter session set "_optimizer_eliminate_filtering_join" = false;
alter session set "_optimizer_join_factorization" = false ;
alter session set "_optimizer_use_cbqt_star_transformation" = false ;
alter session set "_optimizer_connect_by_elim_dups" = false ;
alter session set "_connect_by_use_union_all" = old_plan_mode;
alter session set "_optimizer_table_expansion" = false;
alter session set "_and_pruning_enabled" = false ;
alter session set "_optimizer_use_feedback" = false ;
alter session set "_optimizer_try_st_before_jppd" = false ;
alter session set "_optimizer_undo_cost_change' = '11.1.0.7' ;
 |
- 강좌 URL : http://www.gurubee.net/lecture/2608
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.