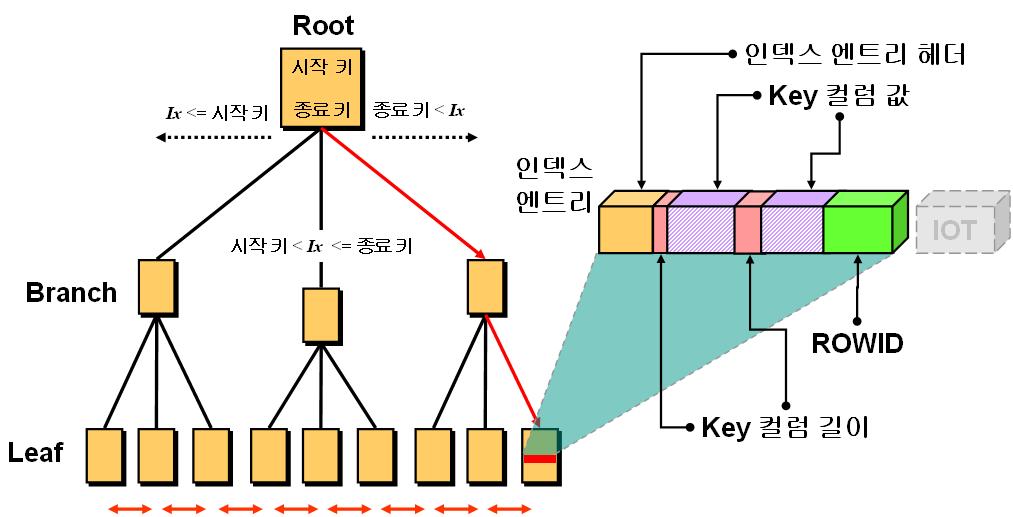
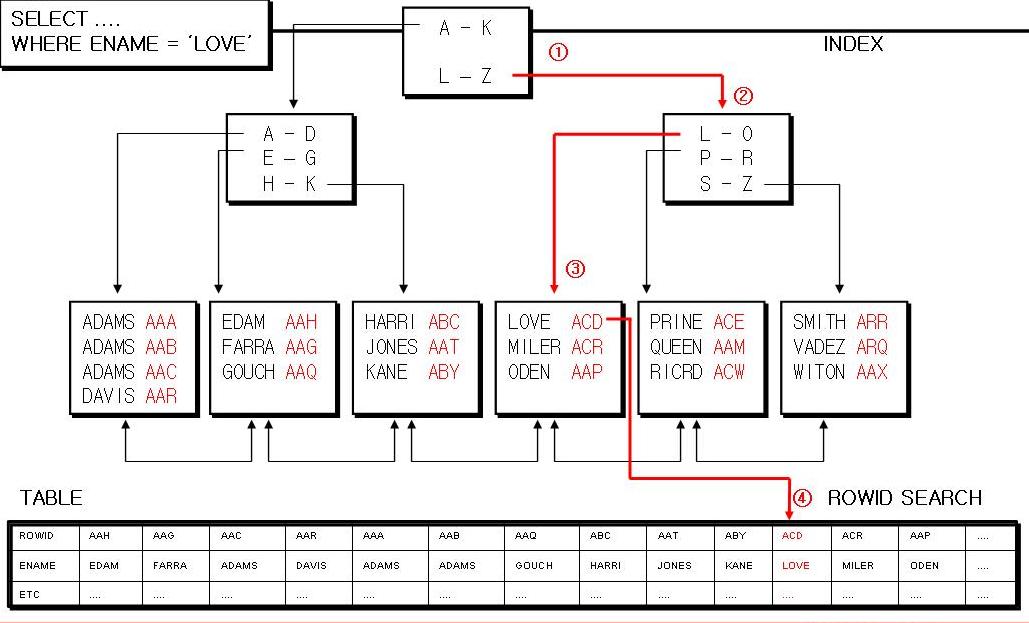
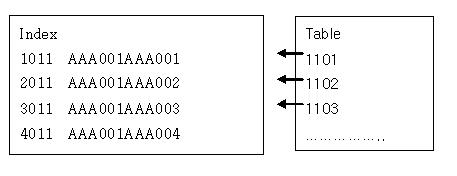
by 구루비스터디 B-Tree B-Tree 인덱스 [2013.09.11]
- 강좌 URL : http://www.gurubee.net/lecture/2604
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.