- 3. 중복된 IN조건의 활용
- 3.1 중복 사용된 상수값 IN 조건의 실행계획
- 3.2 서브쿼리를 포함한 중복 IN 조건의 실행계획
- 3.3 결합처리 실행계획이 불가능한 형태의 해결
- 3.4 IN 활용 시의 주의사항
3. 중복된 IN조건의 활용
- 중복사용된 IN조건이 결합처리 실행계획에 참여할 수 있는 기준과 약간의 보조장치를 곁들이면 우리의 의도대로 유도할 수 있는 방법, 그리고 도저히 방법이 없는 경우에도 이를 해결할 수 있는 몇가지 방법들을 설명할 것이다. 이러한 활용원리를 이해하면 엑세스 효율 향상을 위해 IN을 활용하는 방법은 에플리케이션을 개발하는데 있어서 하나의 확실한 무기가 될 것이다.
3.1 중복 사용된 상수값 IN 조건의 실행계획
- 처리주관 인덱스에 속한 컬럼 중에서 중복 사용된 IN조건이 있다고 해서 모든 IN이 항상 결합처리 실행계획으로 분리되는 것이 아니다.
- 인덱스를 구성하고 있는 컬럼의 개수와 주어진 값이 상수값이냐, 서브쿼리냐에 따라 차이가 있다.
- 중복 사용된 IN조건이 실행계획에 미치는 영향을 알아보기 위해서 상수값으로 부여된 IN조건의 몇가지 형태를 살펴보기로 하자
- ( 단, 여기서 말하는 상수값이란 변수인 경우도 포함)
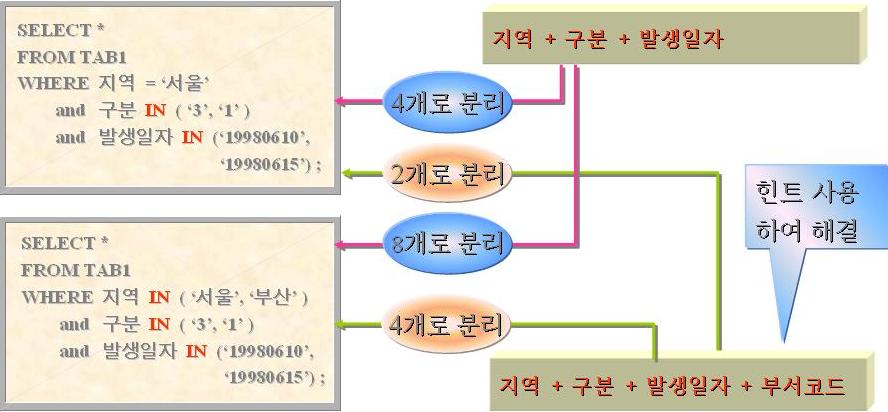
- 만약 TAB1의 인덱스가 '지역 + 구분 + 발생일자' 로 되어 있다면 SQL1은 4개, SQL2는 8개의 분리된 실행계획이 나타난다.
- 만약 인덱스가 '지역 + 구분 + 발생일자 + 부서코드' 와 같이 4개 컬럼으로 구성되어 있다면, SQL1은 '구분'까지만 분리되어 2개로 분리된 실행계획이, SQL2는 '지역', '구분'까지만 분리되어 4개의 분리된 실행계획이 나타난다.
- 규칙1 : 인덱스 컬림이 3개 이하인 경우에 상수값(변수 포함)으로 된 IN조건은 정상적인 결합처리 실행계획을 수행한다.
- 규칙2 : 4개 이상의 컬럼으로 구성된 결합인덱스가 상수값으로 부여된 IN조건을 가진 경우에는 두번째 컬럼까지는 정상적으로 분리되지만 세번째 컬럼부터는 분리 실행계획을 수립하지 않는다.
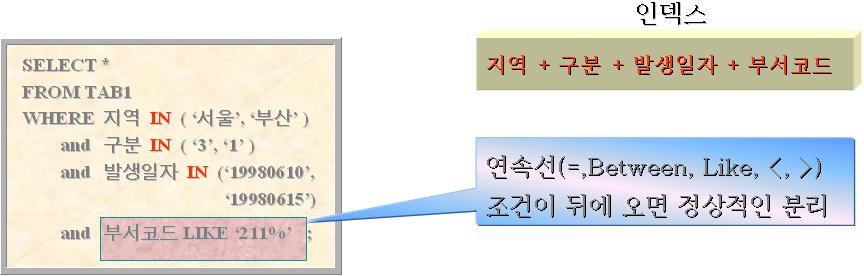
- 이 SQL은 정상적인 4개의 분리된 결합처리 실행계획이 나타난다.
- 여기있는 LIKE대신에 BETWEEN이나 =,<,>,<=,>=을 사용해도 결과는 동일하다.
- 규칙3 : 4개 이상의 컬럼으로 구성된 결합인덱스가 상수값(변수포함)으로 부여된 IN 조건을 가진 경우에 중복된 IN조건 뒤에 '연속선'에 해당하는 조건이 오면 정상적으로 분리된 실행계획을 수립한다.
- 규칙4 : 상수값으로 부여된 IN 조건을 가진 경우에 정상적으로 분리되지 않는 실행계획이 수립된다면 'USE_CONCAT' 힌트를 사용하여 정상적으로 분리시킬 수 있다.
3.2 서브쿼리를 포함한 중복 IN 조건의 실행계획
- 중복 사용된 IN조건에 서브쿼리가 포함되어 있으면 상수값들만 있을 때와는 큰 차이가 있다.
- 특히 서브쿼리의 IN 조건과 상수값의 IN 조건의 순서에 따라 실행계획은 크게 달라진다.
- 서브쿼리가 있는 중복 사용된 IN 조건이 실행계획에 미치는 영향을 알아보기 위해서 몇가지 형태를 살펴보기로 하자.
SELECT ..................
FROM TAB2
WHERE 제품 = 'KH2200'
AND 부서코드 IN ( SELECT 부서코드
FROM 부서
WHERE 부서코드 LIKE '21%' )
and 매출구분 IN ( '1', '5', '7' ) ;
- 규칙5 : 서브쿼리 뒤에 오는(인덱스 컬럼 순서에서, "제품 + 부서코드 + 매출구분 + 매출일자" 또는 "제품 + 부서코드 + 매출구분 + 매출일자" ) 컬럼이 IN조건을 가지면 실행계획의 분리에 도움을 주지 못한다. 이러한 경우는 IN을 사용하지 말고 LIKE나 BETWEEN 등을 사용하는 것이 좋다.
- 이렇게 하기 곤란한 경우는 다음 장에서 제시하는 방법을 사용해야 한다.
- 실행계획을 보면, 인덱스의 첫번째 걸럼인 '제품'의 IN 조건에 의해 크게 2개로 실행계획이 분리되었고, 서브쿼리는 각각의 실행계획마다 수행하여 '='을 공급했다.
- 그결과 세번째 컬럼인 '매출구분'이 연속선에 해당하므로 이 조건이 '주류'역활을 할 수 있게 되었다.
- 규칙6 : 서브쿼리 앞에 위치한 (인덱스 컬럼 순서에서) 컬럼이 IN 조건을 가지면서 실행계획 분리에 참여한다면 서브쿼리는 각각의 분리된 실행계획마다 중복해서 수행한다.
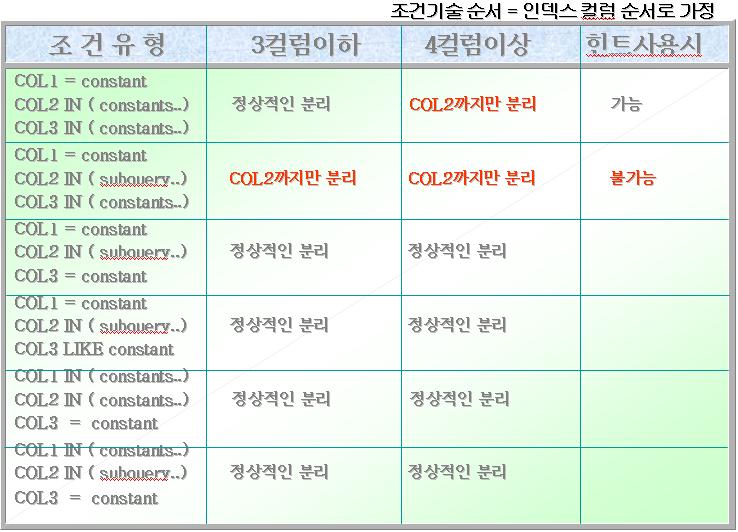
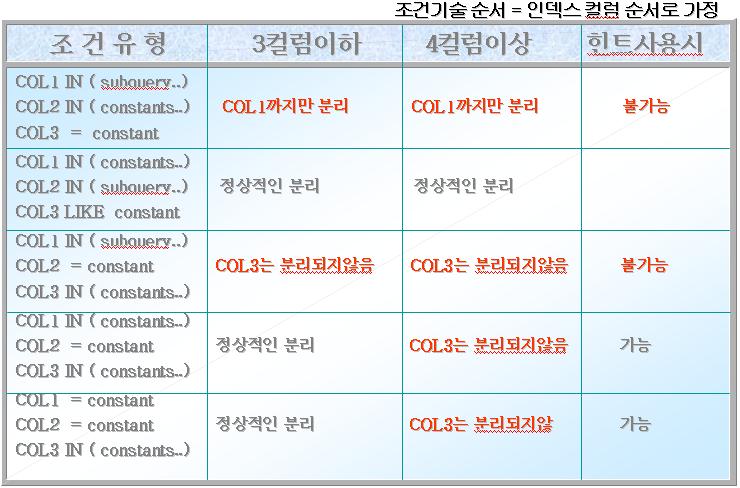
- 지금까지 설명한 중복된 IN의 실행계획의 수립상태를 다음 도표를 통해 정리합니다.
- (가정 : 여기서 사용된 인덱스는 COL1, COL2, COL3, COL4 순으로 구성)
3.3 결합처리 실행계획이 불가능한 형태의 해결
- '모든 점을 서브쿼리에서 생성하여 메인쿼리에 공급해 주는 방법' 으로 옵티마이저 대신에 우리가 '점 집합' 을 만드는 서브쿼리를 이용하여 메인쿼리에게 제공자 역활을 하도록 한다면 분리된 실행계획과 다를 것이 없다.
- '점 집합' 이란 모두가 ' = ' 인 조건을 의미하므로, 메인쿼리는 항상 '=' 조건에 따라 수행하므로 불필요한 액세스가 발생하지 않는다. 이러한 '점 집합' 을 만드는 방법은 앞서 우리가 원하는 임의의 집합을 만들었던 다양한 방법들이 동원된다. 가령 데이터를 복제하거나 인라인뷰, 사용자 지정 저장형 함수 등을 활용한 것이다.
- 그러면 지금부터 사례를 통해 다양한 활용 방법들을 알아보기로 한다.
SELECT ..................
FROM TAB2
WHERE 제품 = 'KH2200'
and 부서코드 LIKE :DEPT||'%'
and 매출구분 IN ( '1', '5' )
and 매출일자 BETWEEN :S_DATE and :E_DATE ;
- 여기서 사용될 TAB2의 인덱스는 '제품 + 부서코드 + 매출구분 + 매출일자' 라고 정하자.
- 이 테이블에 지난 몇 년간의 데이터가 들어있다고 한다면 마지막에 위치한 '매출일자'의 조건은 전체 처리범위를 줄이는데 큰 영향을 미친다.
- 그러나 이 컬럼이 '주류' 역활을 하기 위해서는 선행 컬럼들인 '부서코드', '매출구분' 조건이 범위조건이 되어서는 안된다.
- 이미 '매출구분'은 IN조건으로 사용되었으며, '부서코드'는 어떤 값을 부여받을지 모르기 때문에 서브쿼리를 사용할 수 밖에 없다.
- 그러나, 이미 설명했듯이 서브쿼리 다음에 다시 '연속선'이 아닌 IN조건이 오면, 설사 힌트를 사용했다 하더라도 분리된 실행계획을 얻을 수 없다.
- 이러한 문제를 해결할 수 있는 다음 방법을 살펴보자.
SELECT ..................
FROM TAB2
WHERE ( 제품, 부서코드, 매출구분, 매출일자 ) IN
( SELECT 'KH2200',
부서코드,
substr(NO,2,1),
YMD
FROM 부서 x, COPY_T y, YMD_DUAL z
WHERE 부서코드 LIKE :DEPT||'%'
and y.NO IN ( '1', '5' )
and YMD BETWEEN :S_DATE and :E_DATE )
- 이 SQL은 모든 '점 집합'을 만들어 메인쿼리에 공급하고 있는 모양이다.
- 서브쿼리에서 '점 집합'을 만들기 위해 '부서' 테이블과 데이터 복제용 모조 테이블인 'COPY_T', 그리고 매출일자를 위해 'YMD_DUAL' 테이블을 조인하였다.
- 서브쿼리내의 조인 조건(WHERE절 이하)들은 서로 연결고리를 가지고 있지 않으므로, 카테시안 곱만큼의 로우를 추출한다.
- 이로서 메인쿼리는 반드시 액세스 해야 할 대상만 '=' 조건으로 수행하므로, 불필요한 엑세스는 전혀 발생하지 않는다.
- 주의해야 할 사항은 이 서브쿼리가 제대로 제공자 역활을 했는지 확인하는 것이다.
3.4 IN 활용 시의 주의사항
- 실무에서 자주 발생하는 주의 사항들을 유형별로 소개한다.
3.4.1 IN 서브쿼리로 인한 메인쿼리의 중복 처리
- IN 서브쿼리가 우리가 원하는 공급자 역활을 했음에도 불구하고, 메인쿼리가 이 결과값을 제대로 사용할 수 없게 인덱스가 구성되어 있는 경우, 오히려 부하를 크게 증가시킨다.
- 좀더 쉽게 설명하면, 서브쿼리가 제공한 결과값이 '주류' 역활을 하지 못하고, '비주류' 역활을 하게 됨으로써, 제공받은 각각의 값들마다 메인쿼리가 중복해서 수행하게 된다는 것이다.
- 좀 더 자세한 내용을 알아보기 위해 다음과 같은 사례를 살펴보기로 하자.
SELECT *
FROM ORD_ITEM_T
WHERE 주문일자 BETWEEN '19980501' AND '19980510'
and 제품 코드 IN (SELECT 제품코드
FROM PRODUCT
WHERE 제품명 LIKE 'SM%')
and 금액 > 1000000 ;
- ORD_ITEM_T 테이블에는 'ORD_ITEM_IDX'라는 인덱스가 '주문일자 + 제품코드' 로 구성되어 있으며, PRODUCT 테이블에는 'PRODUCT_NAME_IDX' 라는 유일 인덱스가 '제품명' 컬럼으로 구성되어 있다.
- 여기에서 '제품코드'를 찾는 서브쿼리는 엑세스 효율화를 위해 추가한 것이 아니라, 사용자가 입력한 '제품명'으로 '제품코드'를 찾기 위해 삽입한 것이다.
Rows Execution Plan
------- ---------------------------------------------------
530 NESTED LOOPS
530 TABLE ACCESS (BY ROWID) OF 'PRODUCT'
531 INDEX (RANGE SCAN) OF 'PRODUCT_NAME_IDX(NON-UNIQUE)'
260 TABLE ACCESS (BY ROWID) OF 'ORD_ITEM_T'
56800 INDEX (RANGE SCAN) OF 'ORD_ITEM_IDX(NON-UNIQUE)'
- 이 실행계획을 살펴보면 서브쿼리가 먼저 수행하여 메인쿼리에 결과를 제공했음을 알 수 있다.
- 그러나, 메인쿼리의 처리주관 인덱스가 엄청나게 불필요한 엑세스가 발생한 것을 발견할 수 있다.
- 이 문제의 발생 원인은 서브쿼리가 수행되어 공급자 역활을 했지만, 메인쿼리의 'ORD_ITEM_IDX' 인덱스의 선행컬럼인 '주문일자'가 '='이 아니므로, 서브쿼리가 공급한 530개의 각 로우마다 " 주문일자 BETWEEN '19980501' AND '19980510' " 범위를 중복해서 스캔했기 때문이다.
- 이러한 문제를 해결하기 위해 다음과 같은 방법을 사용해 보자.
SELECT *
FROM ORD_ITEM_T
WHERE ( 주문일자, 제품코드 ) IN
( SELECT YMD, 제품코드
FROM YMD_DUAL x, PRODUCT y
WHERE 주문일자 BETWEEN '19980501' AND '19980510'
AND 제품명 LIKE 'SM%' )
AND 금액 > 1000000 ;
- '주문일자'를 별도의 서브쿼리로 바꾸면 중복된 IN이 발생하여 분리된 실행계획을 얻을 수 없으므로, 서브쿼리에서 모든 점을 만들어 공급하는 방법을 사용한다.
3.4.2 공급자 역활을 못하는 서브쿼리의 해결
- 공급자 역활을 위해 추가된 서브쿼리가 확인자로 사용되면 심각한 문제를 유발시킨다는 것을 언급했다. 이러한 문제가 발생하지 않도록 몇가지 방법을 소개한다.
- 다음의 SQL은 공급자 역활을 위한 서브쿼리가 확인자 역활을 하게 된 경우다.
SELECT 종목코드, count(*), sum(계약금액)/1000
FROM 계약내역
WHERE 종목코드 IN ( SELECT 종목코드
FROM 종목 )
AND 계약일 = to_char(sysdate,'yyyymmdd')
- 이 SQL에 사용된 인덱스는 '종목코드 + 계약일 + 계약순서' 라고 가정한다.
(1) 서브쿼리의 조건에 확실한 선처리 조건을 부여하는 방법
SELECT 종목코드, count(*), sum(계약금액)/1000
FROM 계약내역
WHERE 종목코드 IN ( SELECT 종목코드
FROM 종목코드테이블
WHERE 종목코드 > ' ' )
and 계약일 = to_char(sysdate,'yyyymmdd')
(2) 서브쿼리에 있는 SELECT-LIST 컬럼을 가공시키는 방법
- 이 방법은 IN의 서브쿼리에 사용된 SELECT-LIST인 '종목코드'를 강제로 가공시켜, 서브쿼리가 나중에 수행될 때 사용할 연결고리를 못쓰게 함으로써 옵티마이져가 서브쿼리를 먼저 수행하게 한다. (데이터베이스 버전에 따라 차이 있을 수 있음)
SELECT 종목코드, count(*), sum(계약금액)/1000
FROM 계약내역
WHERE 종목코드 IN ( SELECT 종목코드 || ''
FROM 종목코드테이블 )
AND 계약일 = to_char(sysdate,'yyyymmdd')
(3) 서브쿼리를 GROUP BY 시키는 방법
- 서브쿼리에 메인쿼리의 컬럼을 가지지 않고 그룹함수를 사용했다면 서브쿼리가 먼저 수행할 가능성이 매우 높다. 이와같이 옵티마이져 특성을 이용하여 서브쿼리가 먼저 실행되도록 유도한다.
SELECT 종목코드, count(*), sum(계약금액)/1000
FROM 계약내역
WHERE 종목코드 IN ( SELECT 종목코드
FROM 종목코드테이블
GROUP BY 종목코드 )
AND 계약일 = to_char(sysdate,'yyyymmdd')
(4) 힌트(PUSH_SUBQ)를 사용하는 방법
- 서브쿼리를 먼저 수행시켜 달라는 'PUSH_SUBQ' 힌트를 사용하여 서브쿼리가 먼저 수행되도록 할 수 있다.
SELECT /*+ PUSH_SUBQ */
종목코드, count(*), sum(계약금액)/1000
FROM 계약내역
WHERE 종목코드 IN ( SELECT 종목코드
FROM 종목코드테이블 )
AND 계약일 = to_char(sysdate, 'yyyymmdd')
3.4.3 논리합 연산자에서 'STOP KEY'의 비효율
- 조건을 만족하는 첫번째 로우를 찾으면 더 이상 처리하지 않고, 멈추도록 하기 위해서 EXISTS나 ROWNUM을 사용한다. 만약 처리주관 범위가 IN이나 OR일 때, 즉 결합처리 실행계획이 수립된 경우 ROWNUM을 사용하면 처리를 멈추기 못하고 전체 범위를 모두 처리한다.
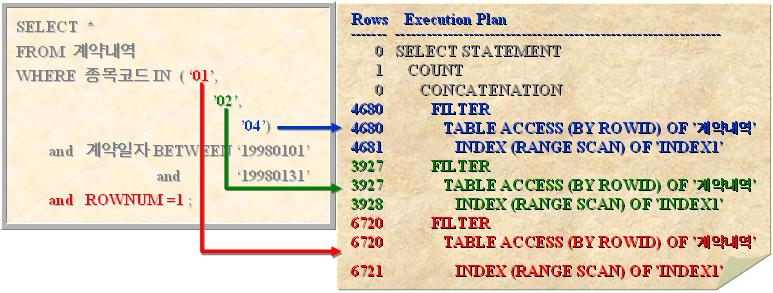
- 이해를 돕기 위해 다음의 SQL을 보자. 1998년 1월에 발생한 계약 중에서 종목코드가 '01' 이거나 '02' 또는 '04' 인 데이터를 한건만 추출하고자 한다. (인덱스가 '종목코드 + 계약일자' 로 구성)
- 실행계획을 살표보면 정상적으로 분리되어 결합처리 실행계획이 수행되었다.
- 그러나 분리된 각각의 엑세스는 필터(FILTER)처리가 들어있다.
- 또 하나 특이한 것은 두번째 줄에 있는 'COUNT' 에 'STOPKEY'가 빠져 있다.
- 우측에 실행된 ROWs(로우 수)를 보면 분리된 실행계획 마다 모두 전체범위 처리를 했다.
- 조건에서 ' ROWNUM = 1 ' 만 처리하라고 했으므로 분리된 엑세스 중에서 어느 하나가 조건을 만족하면 처리를 멈춰야 한다.
- 그런데, 왜 각 엑세스에 분리되어 있는 필터처리는 첫번째 로우를 만났지만 멈추지 않았을까?
- 필터처리는 단순히 처리하고 있는 로우의 ROWNUM을 체크하여 1이면 취하고 아니면 버리는 일을 끝까지 계속한다. ROWNUM이 1인 로우는 하나뿐이므로 ROWNUM이 1인 로우가 지나간 다음에는 영원히 1은 올 수 없다. 그래서 분리된 다른 엑세스에서는 분명히 ROWNUM=1 이 없을 것이지만 체크작업은 끝까지 계속되었던 것이다.
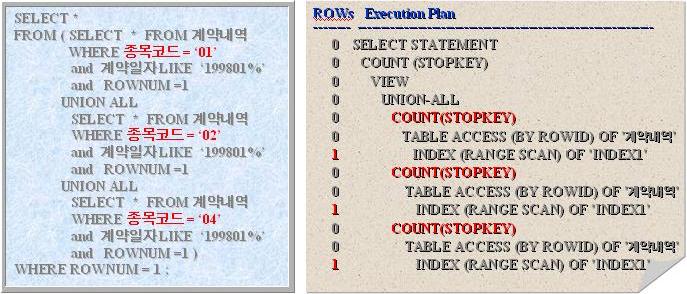
- 이러한 문제를 피할갈 수 있는 방법은 다음 SQL의 결합처리 실행계획을 수립하지 않도록 IN조건을 BETWEEN 으로 대치시킨 것이다.
- 이 SQL 의 길이가 늘어난 것이 흠이지만 실행한 일의 양은 현저하게 감소했다.
- 실행계획을 살펴보면 'COUNT(STOPKEY)'가 각 실행단계마다 들어 있다.