대용량 데이터베이스솔루션 2 (2007년)
4.1 개념 및 특징
- 조인 : 집합간 동일한 수준의 관계
- 서브쿼리 : 집합간 주종관계
4.1.1 먼자 수행하는 서브쿼리의 조인과의 차이
SELECT x.자재코드,x.자재명,x.규격,x.안전재고,y.재고수량
FROM 자재 x, 자재일일재고 y
WHERE y.자재코드 = x.자재코드
AND y.년월일 = to_char(sysdate, 'yyyymmdd')
AND x.자재코드 IN (SELECT 자재코드
FROM 구매의뢰
WHERE 진행상태 = '발주중'
AND 출고희망일자 between to_char(sysdate,'yyyymmdd')
And to_char(sysdate+6,'yyyymmdd'));
NESTED LOOPS
VIEW
SORT(UNIQUE)* --유일한 값을 만들기 위한 정렬 작업이 내부적으로 일어난다
TABLE ACCESS (BY ROWID) OF '구매의뢰'
INDEX (RANGE SCAN) OF '인덱수1'
TABLE ACCESS (BY ROWID) OF '자재'
INDEX (UNIQUE SCAN) OF '자재_PK'
조인과 서브쿼리의 차이점
- 메인쿼리의 기본키에 상관없이 서브쿼리는 언제나 1쪽 집합이 된다.
SELECT 사번,성명,주소,생년월일,입사일...
FROM 사원 x,부서 y
WHERE x.부서코드 = y.부서코드
AND x.입사일 >= '19970101'
AND y.지역 = '경기도';
SELECT 사번,성명,주소,생년월일,입사일...
FROM 사원
WHERE 입사일 >= '19970101'
AND 부서코드 IN (SELECT 부서코드
FROM 부서
WHERE 지역 = '경기도)
- 위 두 쿼리의 실행 계획은 같다.
SELECT STATEMENT
NESTED LOOPS
TABLE ACCESS (BY ROWID) OF '사원'
INDEX (RANGE SCAN) OF '입사일_INDEX' (NON UNIQUE)
TABLE ACCESS (BY ROWID) OF '부서'
INDEX (UNIQUE SCAN) OF '부서_PK' (UNIQUE)
- 허나. 조인문에서 X,Y집합은 동등한 조건으로 조인이 되었으므로, X의 컬럼,Y의 컬럼 사용이 가능하지만,
- 서브쿼리문에선 Y집합은 X집합에 종속되어 Y 집합의 부서코드만 제공할 뿐 다른 컬럼은 사용 할수 없다.
SELECT 부서코드,부서명,관리자,설립일,지역,...
FROM 부서
WHERE 지역 = '경기도'
AND 부서코드 IN (SELECT 부서코드
FROM 사원
WHERE 입사일 >= '19970101');
SELECT *distinct* y.부서코드,부서명,관리자,설립일,지역,...
FROM 사원 x,부서 y
WHERE x.부서코드 = y.부서코드
AND 입사일 >= '19970101'
AND 지역 = ' 경기도'
- 위 두 쿼리는 동일한 결과를 얻게 되지만 두번째 쿼리는 유일한 레코드를 찾기 위해 불필요한 정렬처리가 추가되었다.
4.1.2 나중 수행하는 서브쿼리의 조인과의 차이
SELECT 자재코드, 자재명, 규격, 안전재고, .................
FROM 자재 x
WHERE 자재구분 = '배관자재'
and 안전재고 >= (SELECT 재고수량
FROM 자재일일재고
WHERE y.자재코드 = x.자재코드
and y.년월일 = to_char(sysdate, 'yyyymmdd'));
Execution Plan
\-------------------------------------------------------\-
SELECT STATEMENT
{color:#cc0000}{*}FILTER{*}{color}\\
TABLE ACCESS (BY ROWID) OF '자재'
INDEX (RANGE SCAN) OF '자재구분_INDEX' (NON-UNIQUE)
TABLE ACCESS (BY ROWID) OF '자재일일재고'
INDEX (RANGE SCAN) OF '년월일_INDEX' (NON-UNIQUE)
- FILTER 가 나타난 이유는 서브쿼리가 M쪽이므로 그대로 연결하면 원래의 메인쿼리의 집합이 늘어나기 때문이다.
- 메인쿼리의 해당 건마다 서브쿼리에 대응되는 로우가 하나라도 있는 것이 확인되면 해당 건에 대한 처리를 종료함으로 써 메인쿼리의 집합은 변하지 않는다.
- 서브쿼리의 집합은 언제나 1이 되어야 하믄로 먼저 수행될 때에는 유일한 집합을 만들어 메인쿼리에 결과를 공급하고, 나중에 수행되면 존재 유무만 판단하는 방식으로 처리한다.
4.2 서브쿼리의 실행계획
- 서브쿼리도 조인과 마찬가지로 처리방식과 순서의 차이로 인해 발생하는 하는 차이는 크다.
| 확인자 역할을 하는 서브쿼리: 수행시간 1600초 | 제공자 역할을 하는 서브쿼리: 수행시간 0.1초 |
|---|---|
| UPDATE 청구 x SET 입금액 = nvl(입금액,0) + :in_amt WHERE 청구년월 = '199803' and 고객번호 IN (SELECT 고객번호 FROM 고객 y WHERE 납입자 = :in_cust and y.고객번호 = x.고객번호 ); | UPDATE 청구 x SET 입금액 = nvl(입금액,0) + :in_amt WHERE 청구년월 = '199803' and 고객번호 IN (SELECT 고객번호 FROM 고객 y WHERE 납입자 = :in_cust and y.고객번호 = x.고객번호 ); |
4.2.1 서브쿼리의 실행순서
제공자역할을 하기 위한 서브쿼리의 조건
- 1)서브쿼리 내에 메인쿼리의 항목이 존재하지 않아야 한다.
- 2)서브쿼리가 제공한 결과를 받는 메인쿼리의 컬럼이 반드시 처리주관 컬럼이 되어야 한다.
- (서브쿼리에게 받은 결과값이 직접 처리범위를 줄여주기 위해 사용되지 못하면 다시 확인자 역할로 떨어지게 된다.)
SELECT *
FROM TAB1
WHERE DEPTNO = '1100'
and SALDATE IN (SELECT YMD \|\| '' <= 서브쿼리가 확인자 역할을 한다면, 컬럼에 \|\|'' 로 가공하여 제공자역할을 수행하도록한다.
FROM YMD_DUAL
WHERE YMD between '19980301' and '19980312' )
and ITEM LIKE 'ABC%' ;
- 컬럼가공으로 마치 조인에서 연결고리의 어느 한쪽을 못 쓰게 하는 것과 동일한 효과가 나타난다.
4.2.2 SORT MERGE 형태의 수행
- 서브쿼리가 M의 집합일 때는 SORT(UNIQUE)를 수행하여 1의 집합을 만든 후 머지한다
4.2.3 필터형식으로 처리되는 경우
SELECT *
FROM ORDER x
WHERE ORDDATE LIKE '9706%'
AND EXISTS (SELECT 'X'
FROM DEPT y
WHERE y.DEPTNO = x.SALDEPT
AND y.TYPE1='1')
ROWS Execution Plan
\--\-- --\--\------------------------------------------------\-
3200 FILTER
3200 TABLE ACCESS (BY ROWID) OF 'ORDER'
3201 INDEX (RANGE SCAN) OF 'ORDDATE_INDEX' (NON_UNIQUE)
10 TABLE ACCESS (BY ROWID) OF 'DEPT'
10 INDEX (UNIQUE SCAN) OF 'DEPT_PK' (UIQUE)
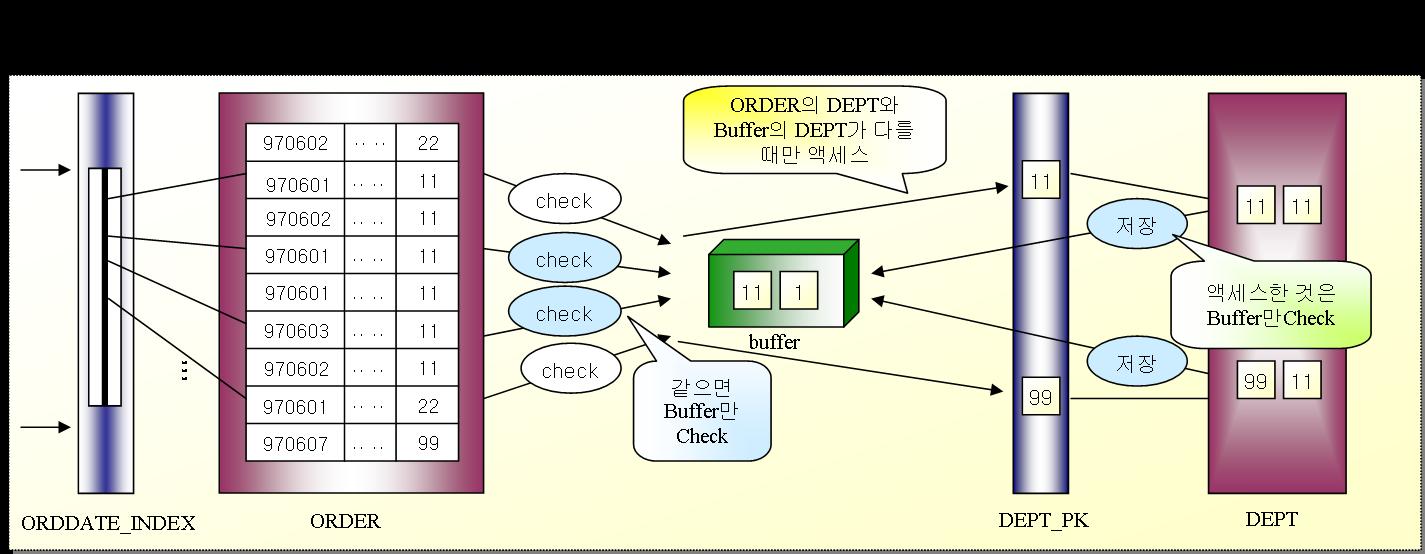 |
① 먼저 ORDDATE_INDEX에서 '9706%'를 만족하는 첫번째 로우를 읽고 그 ROWID로 ORDER 테이블의 해당 로우를 액세스한다.
② 그 로우가 가지고 있는 SALDEPT와 버퍼에 있는 DEPT와 비교한 결과가 같지 않으므로 DEPT 테이블의 기본키를 이용해 액세스한 후 체크한다. 체크결과 조건을 만족하면 운반단위에 태우고 아니면 버린다
③ 액세스한 DEPT 네이블의 비교컬럼값들을 버퍼에 저장한다.
④ ORDDATE_IDEX의 두번째 로우에 대한 ORDER 테이블 로우를 액세스한 후 버퍼와 체크한다. 이때 ORDER 테이블의 SALDEPT와 버퍼의 DEPT가 동일하면 버ㅓ와의 비교만 수행하며, DEPT 테이블은 액세스하지 않는다. 버퍼의 DEPT와 일치하지 않을 때만 DEPT테이블을 액세스하여 비교하고 그 값을 다시 버퍼에 저장한다. 버퍼는 하나의 값만 저장할 수 있으므로 앞서 저장된 값은 갱신된다.
⑤ 이와 같은 방법으로 ORDDATE_INDEX 의 처리범위가 완료될 때까지 수행한다
4.3 유형별 활용
4.3.1 M:M관계의 비교
| 구분 | 인라인 뷰 조인 | UNION,GROUP | 사용자지정 저장형 함수 | 서브쿼리 |
|---|---|---|---|---|
| M:M관계의 데이터 연결 | ○ | ○ | ○ | ○ |
| 결과의 추출을 원할 때 | ○ | ○ | ○ | X |
| 다양한 추출컬럼이 필요할 때 | ○ | ○ | △ | X |
| 양측 OUTER 조인 | X | ○ | X | X |
| 독자적으로 범위를 줄일 수 있을 때 | ○ | ○ | ○ | ○ |
| 다른 쪽에서 결과를 받는 것이 유리 | X | X | ○ | ○ |
| 배타적 관계의 연결 | X | ○ | ○ | △ |
| 연결할 집합이 유사하지 않을 때 | ○ | △ | ○ | ○ |
| 부분범위처리 | △ | X | ○ | △ |
| 기본키와 외부키가 아닌 경우의 연결 | ○ | ○ | ○ | ○ |
| 단순히 조건 체크만 원할 때 | △ | X | △ | ○ |
| 단순히 조건의 상수값만 제공할 때 | △ | X | △ | ○ |
4.3.2 부정형 조인
필터형식_부정형 조인의 장점
- 선행집합의 상수값을 제공받아 처리
- 부분범위처리 가능 \*필터형식_부정형 조인의 단점
- 랜덤 액세스의 증가
4.3.3 부분범위처리로의 유도
부분범위처리 유도 방법
- 1)제공자 역할을 할때 부분범위처리 유도
- 2)확인자 역할을 할때 부분범위처리 유도
- 그러나.. 제공자 역할을 하는 서브쿼리는 부분범위처리가 곤란하다.(항상 1의 집합이 되야 하기 때문에.)
- 그래서.상수값을 제공하는 서브쿼리는 부분범위처리를 안하고, 메인쿼리를 부분범이처리가 되도록 유도하자.
SELECT x.COL1, x.COL2, min(x.COL4), min(x.COL5)
FROM TAB1 x, TAB2 y
WHERE x.COL1 = y.FLD1
and x.COL2 = y.FLD2
and x.COL3 between '1110' and '3999'
and y.FLD3 like '199803%'
GROUP BY COL1, COL2
HAVING sum(FLD4) > 0 ;
SELECT COL1, COL2, COL4, COL5
FROM TAB1
WHERE COL3 between '1110' and '3999'
and EXISTS (SELECT ' '
FROM TAB2
WHERE FLD1 = COL1
and FLD2 = COL2
and FLD3 like '199803%'
GROUP BY FLD1, FLD2
HAVING sum(FLD4) > 0);
- 메인쿼리가 먼저 수행하면서 각 추출된 로우마다 한번씩 서브쿼리가 수행한다.
- 서브쿼리는 확인자 역할. 메인쿼리는 부분범위처리가 가능해졌다.
4.3.4 ANY,ALL 을 활용한 서브쿼리
<<ALL>>
SELECT *
FROM TAB1
WHERE COL1 >= ALL ( SELECT FLD1
FROM TAB2
WHERE FLD2 like 'ABC%' );
SELECT *
FROM TAB1
WHERE COL1 >= ( SELECT MAX(FLD1)
FROM TAB2
WHERE FLD2 like 'ABC%' );
- ALL 은 필터처리 방법으로 실행계획이 수립되면 대부분 확인자역할을 한다.
- 그러나 ALL은 모든 집합을 만족해야 하믄로 필터처리가 유리하지 않다.
- ALL사용은 권장사항이 아니다.
<<ANY>>
SELECT *
FROM TAB1
WHERER COL1 >= ANY (SELECT FLD1
FROM TAB2
WHERE FLD2 like 'ABC%' );
SELECT *
FROM TAB1
WHERE COL1 >= ( SELECT MIN(FLD1)
FROM TAB2
WHERE FLD2 like 'ABC%' );
- 위 두 쿼리의 수행결과는 동일하나, 실행계획적 측면에선 큰 차이가 있다.
- ANY는 확인자역할, MIN은 제공자 역할.
- ANY대신 SOME 사용가능
- ANY와 ALL은 =,<>,>,<,>=,<= 연산자와 같이 사용
4.4 서브쿼리 활용시 주의 사항
4.4.1 조인문에서 서브쿼리의 실행순서
- 힌트사용
- 먼저 수행시킬 집합을 인라인뷰로 묶고 나중에 조인할 집합을 연결하여 필요시 힌트를 사용하여 실행계획 유도.
- 사용자지정 저장형 함수를 활용
4.4.2 MIN,MAX 값을 가진 로우 엑세스
SELECT 종목, 고객번호, 변경회차, 변경일자, 금액
FROM 변경내역 x
WHERE 변경회차 = ( SELECT MAX(y.변경회차)
FROM 변경내역 y
WHERE y.고객번호 = x.고객번호
and y.변경일자 between '19980101' and '19980131' )
and 종목 = '15'
and 변경일자 between '19980101' and '19980131' ;
SELECT '15' 종목,
고객번호,
substr(추출값,1,3) 변경회차,
substr(추출값,1,3) 변경일자,
substr(추출값,1,3) 금액
FROM (SELECT 고객번호,
MAX(RPAD(변경회차,3)\|\|변경일자\|\|금액) 추출값
FROM 변경내역
WHERE 종목 = '15'
and 변경일자 between '19980101' and '19980131'
GROUP BY 고객번호);
"구루비 데이터베이스 스터디모임" 에서 2007년에 "대용량 데이터베이스 솔루션 2" 도서를 스터디하면서 정리한 내용 입니다.
- 강좌 URL : http://www.gurubee.net/lecture/2485
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.