press x to close
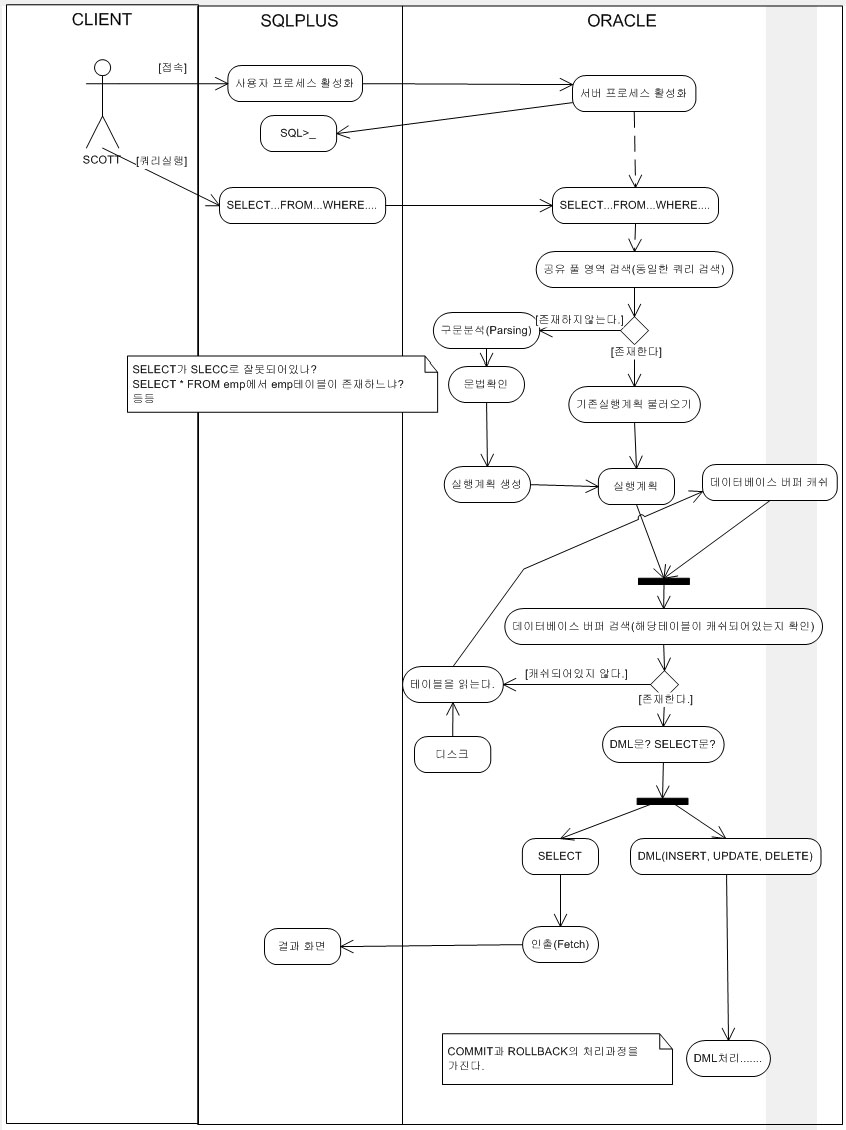 |
| 그림1. DBMS Call |
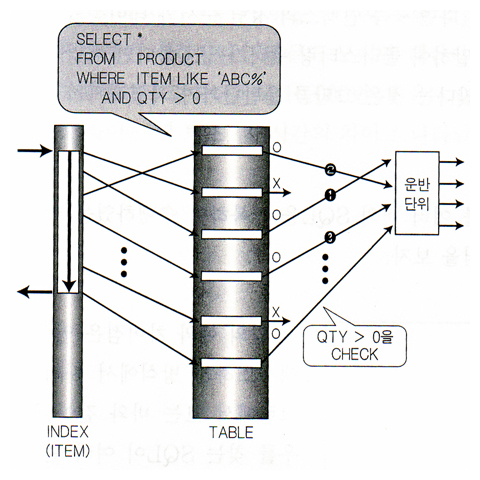 그림2-1. 대용량데이터베이스 솔루션2 1-41 | 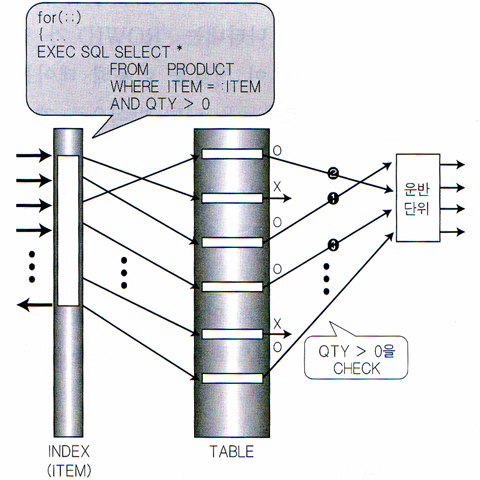 그림2-2. 대용량데이터베이스 솔루션2 1-42 |
| 이유? 운반단위를 빨리채운다 -> 체감속도가 빠르다. | 이유? 운반단위를 늦게채운다 -> 체감속도가 느리다. |
| 왜? ITEM LIKE 'ABC%'는 처음과 마지막에만 검사한다. | 왜? 인덱스의 매 로우마다 ITEM LIKE 'ABC%'를 검사한다. |
| 서버프로세스 : "인덱스야 너 ITEM이 "ABC"로 시작하는곳이 어디야?" 인덱스 : "4번" 서버프로세스 : "그럼 끝나는곳은 어디야?" 인덱스 : "135번" 서버프로세스 : "그럼 내가 말안해도 4번부터 135번까지 하나씩 차례대로 줘.." 인덱스 : "응" | <없음> |
| (N번 반복 - 시작) 1. 인덱스 : "여?어" 2. 서버프로세스 : "이 로우의 QTY가 0보다 크냐?" 3. 인덱스 : "응" 4. 서버프로세스 : "그럼 운반단위에 넣어" 5. 인덱스 : "응" 6. 서버프로세스 : "운반단위가 가득 찼어?" 7. 인덱스 : "아니" / "응" ( - 끝) | (N번 반복 - 시작) 1. 서버프로세스 : "인덱스야 너 ITEM이 "ABC"로 시작해?" 2. 불량인덱스 : "응" 3. 서버프로세스 : "그럼 그거줘바.." 4. 불량인덱스 : "여?다!" 5. 서버프로세스 : "이 로우의 QTY가 0보다 크냐?" 6. 불량인덱스 : "그래." 7. 서버프로세스 : "그럼 운반단위에 넣어" 8. 불량인덱스 : "알았어" 9. 서버프로세스 : "운반단위가 가득찼어?" 10. 불량인덱스 : "아니" / "응" ( - 끝) |
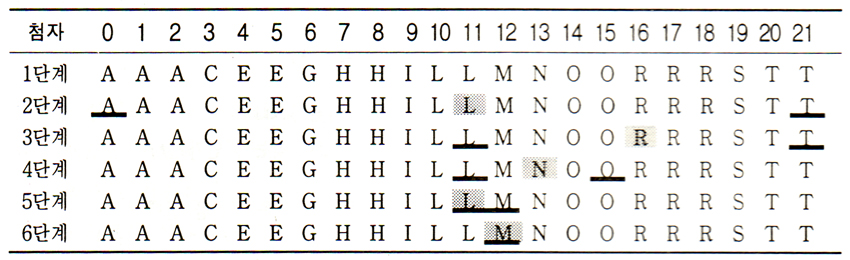 |
| 그림3-1. Binary Search(Binary Tree Search) |
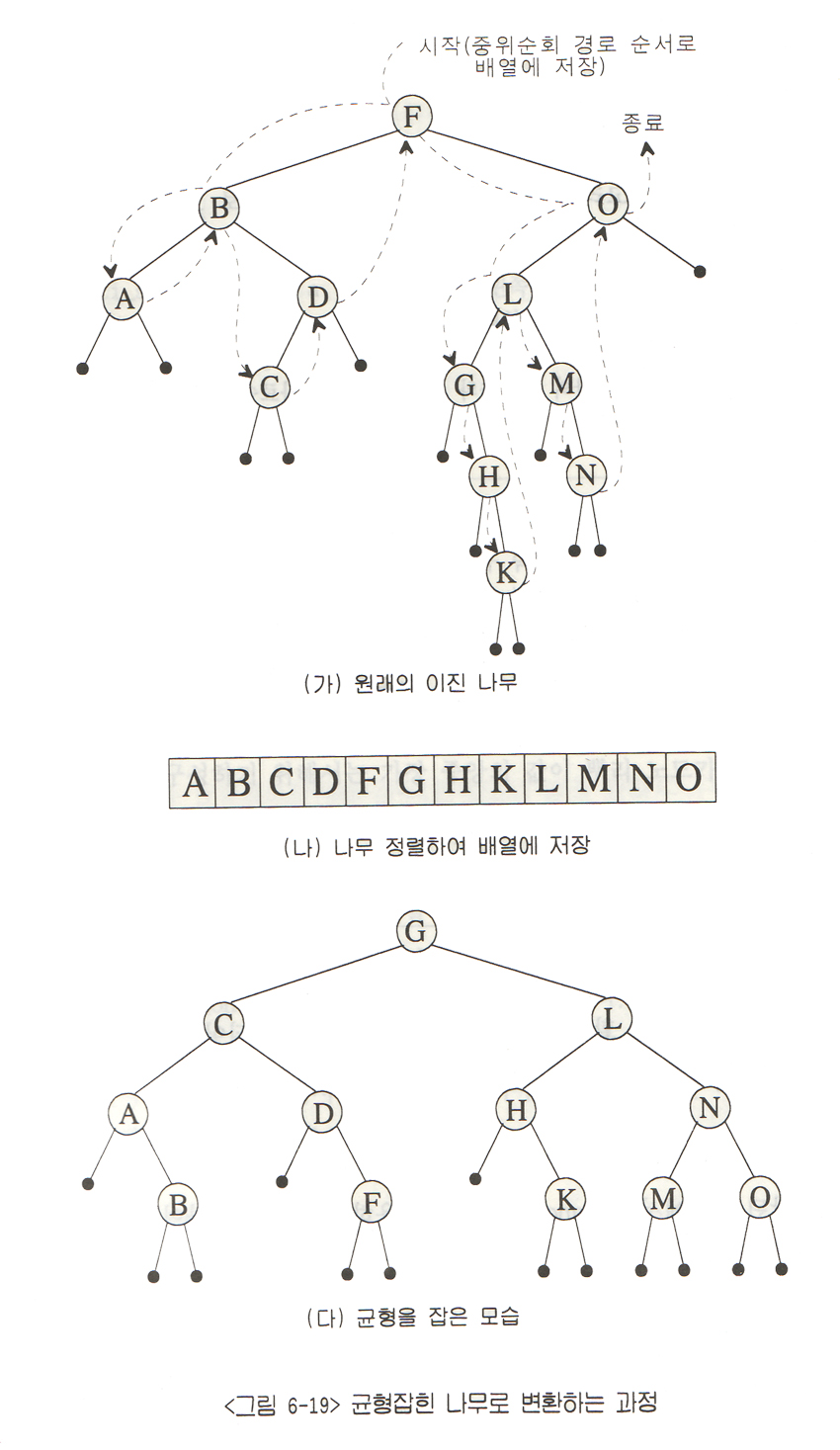 |
| 그림3-2. B-Tree(Binary Tree Search) & B-Tree(Balanced Search Tree) |
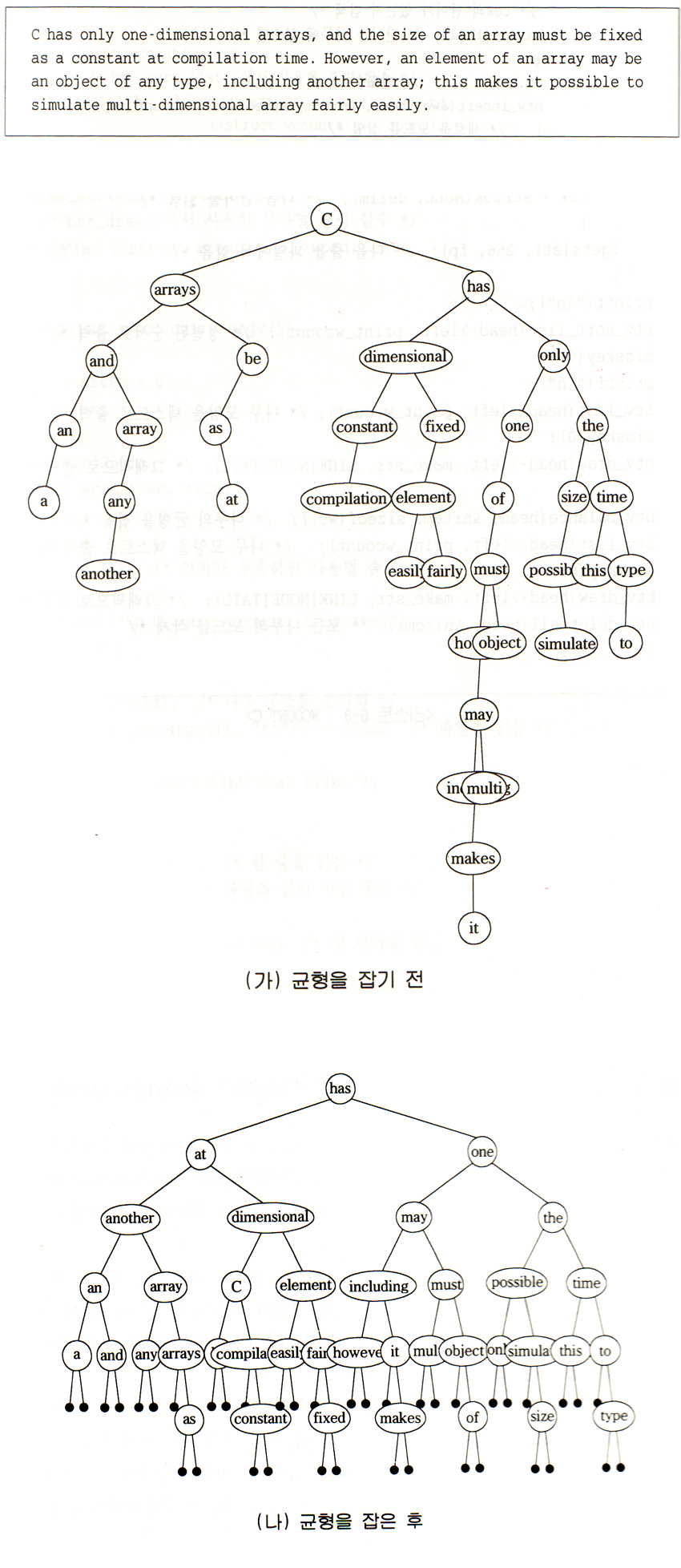 |
| 그림3-3. B-Tree Sample |
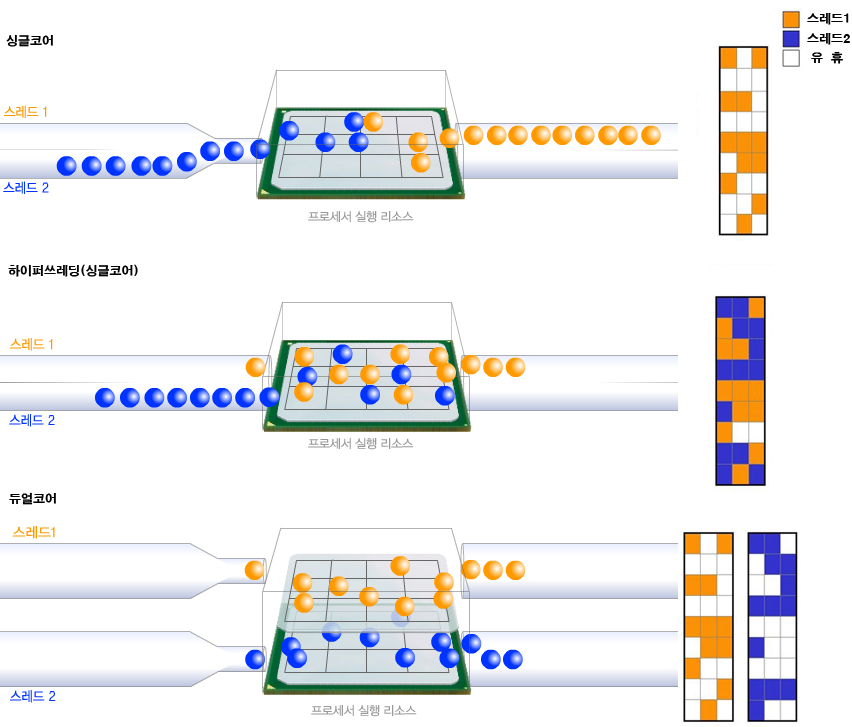 |
| 그림4. 병렬처리의 효율성 |
- 강좌 URL : http://www.gurubee.net/lecture/2479
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.