press x to close
select cust_nm, birthday from customer where cust_id = :cust_id
call count cpu elapsed disk query current rows
----- ------ ----- ------- ---- ----- ------ -----
Parse 1 0.00 0.00 0 0 0 0
Execute 5000 0.18 0.14 0 0 0 0
Fetch 5000 0.21 0.25 0 20000 0 50000
----- ------ ----- ------- ---- ----- ------ -----
total 10001 0.39 0.40 0 20000 0 50000
public class JavaLoopQuery{
public static void insertData( Connection con
, String param1
, String param2
, String param3
, long param4) throws Exception{
String SQLStmt = "INSERT INTO 납입방법별_월요금집계 "
+ "(고객번호, 납입월, 납입방법코드, 납입금액) "
+ "VALUES(?, ?, ?, ?)";
PreparedStatement st = con.prepareStatement(SQLStmt);
st.setString(1, param1);
st.setString(2, param2);
st.setString(3, param3);
st.setLong(4, param4);
st.execute();
st.close();
}
public static void execute(Connection con, String input_month) throws Exception {
String SQLStmt = "SELECT 고객번호, 납입월, 지로, 자동이체, 신용카드, 핸드폰, 인터넷 "
+ "FROM 월요금납부실적 "
+ "WHERE 납입월 = ?";
PreparedStatement stmt = con.prepareStatement(SQLStmt);
stmt.setString(1, input_month);
ResultSet rs = stmt.executeQuery();
while(rs.next()){
String 고객번호 = rs.getString(1);
String 납입월 = rs.getString(2);
long 지로 = rs.getLong(3);
long 자동이체 = rs.getLong(4);
long 신용카드 = rs.getLong(5);
long 핸드폰 = rs.getLong(6);
long 인터넷 = rs.getLong(7);
if(지로 > 0) insertData (con, 고객번호, 납입월, "A", 지로);
if(자동이체 > 0) insertData (con, 고객번호, 납입월, "B", 자동이체);
if(신용카드 > 0) insertData (con, 고객번호, 납입월, "C", 신용카드);
if(핸드폰 > 0) insertData (con, 고객번호, 납입월, "D", 핸드폰);
if(인터넷 > 0) insertData (con, 고객번호, 납입월, "E", 인터넷);
}
rs.close();
stmt.close();
}
static Connection getConnection() throws Exception { ...... }
static void releaseConnection(Connection con) throws Exception { ...... }
public static void main(String[] args) throws Exception{
Connection con = getConnection();
execute(con, "200903");
releaseConnection(con);
}
}
public class JavaOneSQL{
public static void execute(Connection con, String input_month) throws Exception {
String SQLStmt = "INSERT INTO 납입방법별_월요금집계"
+ "(납입월,고객번호,납입방법코드,납입금액) "
+ "SELECT x.납입월, x.고객번호, CHR(64 + Y.NO) 납입방법코드 "
+ " , DECODE(Y.NO, 1, 지로, 2, 자동이체, 3, 신용카드, 4, 핸드폰, 5, 인터넷) "
+ "FROM 월요금납부실적 x, (SELECT LEVEL NO FROM DUAL CONNECT BY LEVEL <= 5) y "
+ "WHERE x.납입월 = ? "
+ "AND y.NO IN ( DECODE(지로, 0, NULL, 1), DECODE(자동이체, 0, NULL, 2) "
+ " , DECODE(신용카드, 0, NULL, 3) , DECODE(핸드폰, 0, NULL, 4) "
+ " , DECODE(인터넷, 0, NULL, 5) )" ;
PreparedStatement stmt = con.prepareStatement(SQLStmt);
stmt.setString(1, input_month);
stmt.executeQuery(); stmt.close();
}
static Connection getConnection() throws Exception { ...... }
static void releaseConnection(Connection con) throws Exception { ...... }
public static void main(String[] args) throws Exception{
Connection con = getConnection();
execute(con, "200903");
releaseConnection(con);
}
}
void insertWishList ( String p_custid , String p_goods_no ) {
SQLStmt = "insert into wishlist "
+ "select custid, goods_no "
+ "from cart "
+ "where custid = ? "
+ "and goods_no = ? " ;
stmt = con.preparedStatement(SQLStmt);
stmt.setString(1, p_custid);
stmt.setString(2, p_goods_no); stmt.execute();
}
void insertWishList ( String p_custid , String[] p_goods_no ) {
SQLStmt = "insert into wishlist "
+ "select custid, goods_no "
+ "from cart "
+ "where custid = ? "
+ "and goods_no in ( ?, ?, ?, ?, ? )" ;
stmt = con.preparedStatement(SQLStmt);
stmt.setString(1, p_custid);
for(int i=0; i < 5; i++){
stmt.setString(i+2, p_goods_no[i]);
}
stmt.execute();
}
1 public class JavaArrayProcessing{
2 public static void insertData( Connection con
3 , PreparedStatement st
4 , String param1
5 , String param2
6 , String param3
7 , long param4) throws Exception{
8 st.setString(1, param1);
9 st.setString(2, param2);
10 st.setString(3, param3);
11 st.setLong(4, param4);
12 st.addBatch();
13 }
14
15 public static void execute(Connection con, String input_month)
16 throws Exception {
17 long rows = 0;
18 String SQLStmt1 = "SELECT 고객번호, 납입월"
19 + ", 지로, 자동이체, 신용카드, 핸드폰, 인터넷 "
20 + "FROM 월요금납부실적 "
21 + "WHERE 납입월 = ?";
22
23 String SQLStmt2 = "INSERT INTO 납입방법별_월요금집계 "
24 + "(고객번호, 납입월, 납입방법코드, 납입금액) "
25 + "VALUES(?, ?, ?, ?)";
26
27 con.setAutoCommit(false);
28
29 PreparedStatement stmt1 = con.prepareStatement(SQLStmt1);
30 PreparedStatement stmt2 = con.prepareStatement(SQLStmt2);
31 stmt1.setFetchSize(1000);
32 stmt1.setString(1, input_month);
33 ResultSet rs = stmt1.executeQuery();
34 while(rs.next()){
35 String 고객번호 = rs.getString(1);
36 String 납입월 = rs.getString(2);
37 long 지로 = rs.getLong(3);
38 long 자동이체 = rs.getLong(4);
39 long 신용카드 = rs.getLong(5);
40 long 핸드폰 = rs.getLong(6);
41 long 인터넷 = rs.getLong(7);
42
43 if(지로 > 0)
44 insertData (con, stmt2, 고객번호, 납입월, "A", 지로);
45
46 if(자동이체 > 0)
47 insertData (con, stmt2, 고객번호, 납입월, "B", 자동이체);
48
49 if(신용카드 > 0)
50 insertData (con, stmt2, 고객번호, 납입월, "C", 신용카드);
51
52 if(핸드폰 > 0)
53 insertData (con, stmt2, 고객번호, 납입월, "D", 핸드폰);
54
55 if(인터넷 > 0)
56 insertData (con, stmt2, 고객번호, 납입월, "E", 인터넷);
57
58 if(++rows%1000 == 0) stmt2.executeBatch();
59
60 }
61
62 rs.close();
63 stmt1.close();
64
65 stmt2.executeBatch();
66 stmt2.close();
67
68 con.commit();
69 con.setAutoCommit(true);
70 }
71
72 static Connection getConnection() throws Exception { }
73 static void releaseConnection(Connection con) throws Exception { ...... }
74
75 public static void main(String[] args) throws Exception{
76 Connection con = getConnection();
77 execute(con, "200903");
78 releaseConnection(con);
79 }
80 }
DECLARE
l_fetch_size NUMBER DEFAULT 1000; -- 1,000건씩 Array 처리
CURSOR c IS
SELECT empno, ename, job, sal, deptno, hiredate
FROM emp;
...
BEGIN
OPEN C;
LOOP
FETCH c BULK COLLECT
INTO p_empno, p_ename, p_job, p_sal, p_deptno, p_hiredate
LIMIT l_fetch_size;
FORALL i IN p_empno.first..p_empno.last
INSERT INTO emp2
VALUES ( p_empno (i)
, p_ename (i)
, p_job (i)
, p_sal (i)
, p_deptno (i)
, p_hiredate (i) );
EXIT WHEN c%NOTFOUND;
END LOOP;
CLOSE C;
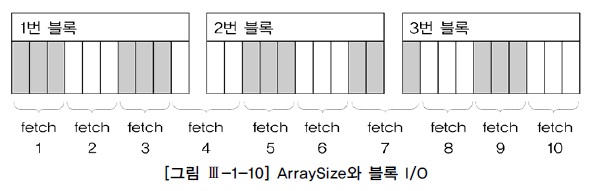
set arraysize 100
call count cpu elapsed disk query current rows
----- ----- ----- ------- ----- ----- ----- ------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.02 2 2 0 0
Fetch 301 0.14 0.18 9 315 0 30000
----- ----- ----- ------- ----- ----- ----- ------
total 303 0.14 0.20 11 317 0 30000
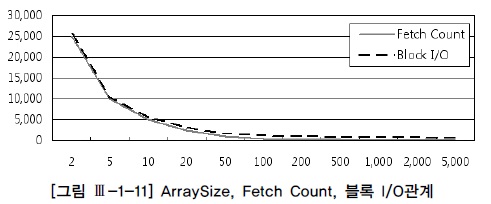
| arraysize | fetch 횟수 | 블록I/O |
|---|---|---|
| 3 | 10 | 12 |
| 10 | 3 | 3 |
| 30 | 1 | 1 |
SQL*Plus 이외의 프로그램 언어에서 Array 단위 Fetch 기능 활용 방법
for item in cursor
loop
......
end loop;
String sql = "select custid, name from customer";
PreparedStatement stmt = conn.prepareStatement(sql);
stmt.setFetchSize(100); -- Statement에서 조정
ResultSet rs = stmt.executeQuery();
// rs.setFetchSize(100); -- ResultSet에서 조정할 수도 있다.
while( rs.next() ) {
int empno = rs.getInt(1);
String ename = rs.getString(2);
System.out.println(empno + ":" + ename);
}
rs.close();
stmt.close();
select channel_id, sum(quantity_sold) auantity_cold
from order a, sales@lk_sales b
where a.order_date between :1 and :2
and b.order_no = a.order no
group by channel_id
Rows Row Source Operation
----- ---------------------------------------------
5 SORT GROUP BY
10981 NESTED LOOPS
500000 REMOTE
10981 TABLE ACCESS BY INDEX ROWID ORDER
500000 INDEX UNIQUE SCAN (ORDER_PK)
select /*+ driving_site(b) */
channel_id, sum(quantity_sold) auantity_cold
from order a, sales@lk_sales b
where a.order_date between :1 and :2
and b.order_no = a.order_no
group by channel_id
Rows Row Source Operation
---- ---------------------------------------------
5 SORT GROUP BY
10981 NESTED LOOPS
939 TABLE ACCESS (BY INDEX ROWID) OF 'ORDER'
939 INDEX (RANGE SCAN) OF 'ORDER_IDX2' (NON-UNIQUE)
10981 REMOTE
create or replace function date_to_char(p_dt date) return varchar2 as
begin
return to_char(p_dt, 'yyyy/mm/dd hh24:mi:ss');
end;
/
- 강좌 URL : http://www.gurubee.net/lecture/2393
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.