press x to close
정의
★ 하나의 인스턴스는 하나의 데이터베이스를 엑세스(Single), 여러개의 인스턴스는 하나의 데이터베이스를 엑세스(RAC)
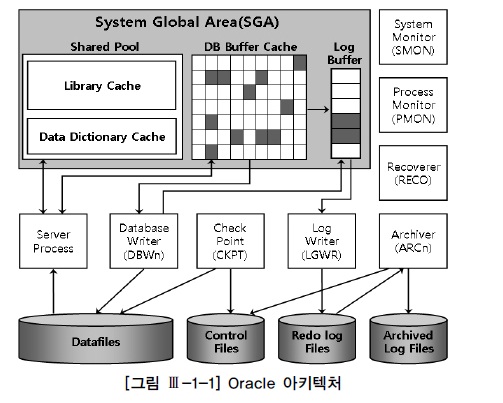
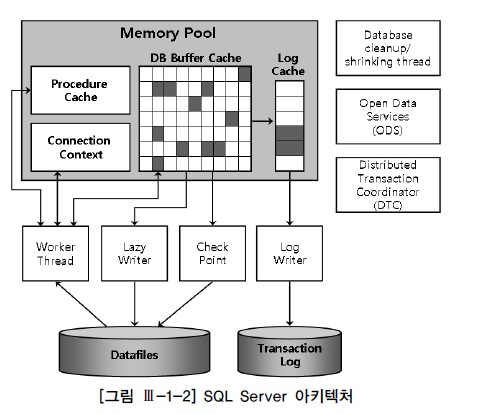
정의
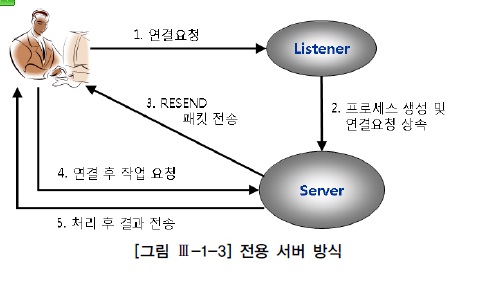
1) 전용서버 방식(Dedicated Server)
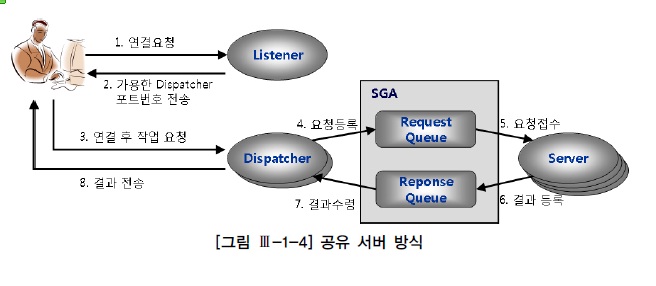
| ORACLE | SQL Server | 설명 |
|---|---|---|
| SMON(System Monitor) | Database cleanup / Shrinking Thread | 장애가 발생한 시스템을 재기동할 때 인스턴스 복구를 수행하고, 임시 세그먼트와 익스텐트를 모니터링한다 |
| PMON(Process Minitor) | Open Data Services(OPS) | 이상이 생긴 프로세스가 사용하던 리소스를 복구한다 |
| DBWn(Database Writers) | Lazywriter Thread | 버퍼 캐시에 있는 더티 버퍼를 데이터 파일에 기록 |
| LGWR (Log Writer) | Log writer Thread | 로그 버퍼 엔트리를 redo 로그 파일에 기록한다 |
| ARCn(Archiver) | N/A | 꽉찬 리두로그가 덮어 쓰여지기 전에 archive로그 디렉토리로 백업한다 |
| CKPT(Checkpoint) | Database Checkpoint Thread | checkpoint 프로시스는 이전의 checkpoint 가 일어났던 마지막 시점 이후의 데이터베이스 변경 사항을 데이터파일에 기록하도록 트리거링하고, 기록이 완료되면 현재 어디까지 기록했는지를 컨트롤 파일과 데이터 파일 헤더에 기록한다. 좀더 자세히 설명하면 wirte Ahead Logging 방식을 사용하는 DBMS는 리두로그에 기록해 둔 버퍼 블록에 대한 변경사항 중 현재 어디까지를 데이터 파일에 기록했는지 체크 포인트정보를 관리해야 한다. 이는 버퍼캐시와 데이터 파일이 동기화된 시점을 가리키며, 장애가 발생하면 마지막 체크포인트 이후 로그 데이터만 디스크에 기록함으로써 인스턴스를 복구할수 있도록 하는 용도로 사용된다.이 정보를 갱신하는 주기가 길수록 장애 발생시 인스턴스 복구 시간도길어진다. |
| RECO(Recoverer) | Distributed Transaction Coordinator(DTC) | 분산 트랜잭션 과정에 발생한 문제를 해결한다 |

| 항목 | 오라클 | SQL Server |
|---|---|---|
| 명칭 | 블록 | 페이지 |
| 블록크기 | 2KB,4KB, 8KB, 16KB, 32KB, 64KB | 8KB |
| 항목 | 오라클 | SQL Server |
|---|---|---|
| 크기 | 다양한크기의 익스텐트 | 항상 64KB(페이지크기가 8KB이므로) |
| 오브젝트 | 단일오브젝트사용 | 2개이상의오브젝트 |
| 오라클 | SQL Server |
|---|---|
| 세그먼트 | 힙구조 또는 인덱스구조 오브젝트 |
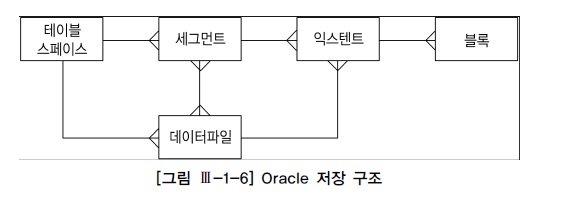
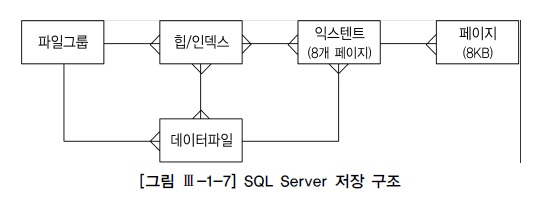
| 오라클 | SQL Server |
|---|---|
| 테이블스페이스 | 파일그룹 |
create temporary tablespace big_temp
tempfile '/usr/local/oracle/oradata/ora10g/big_temp.dbf' size 2000m;
alter user scott temporary tablespace big_temp;
| 오라클 | SQL Server |
|---|---|
| System Global Area(SGA) | Memory Pool |
위와 같은 이유로 버퍼캐시가 필요함
| 오라클 | SQL Server |
|---|---|
| Shared Pool | Procedure Cache |
| 구분 | Sort Area 할당위치 |
|---|---|
| DML | CGA 영역에 할당 |
| SELECT | 수행중간단계에 필요한 sort area는 CGA에 할당, 최종 결과집합을 출력하기 직전 단계에서 필요한 sort area는 UGA에 할당 |
| 오라클 | SQL Server |
|---|---|
| 대기이벤트(Wait Event) | 대기유형(Wait Type) |
Reponse Time = Service Time + Wait Time
CPU Time + Queue Time
- 강좌 URL : http://www.gurubee.net/lecture/2391
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.