press x to close
이번 퀴즈로 배워보는 SQL 시간에는 한 시험실에 입장하는 수험생의 인원에 따라 좌석배치도를 만들어 주는 쿼리를 작성해 본다. 지면 특성상 문제와 정답 그리고 해설이 같이 있다.
진정으로 자신의 SQL 실력을 키우고 싶다면 스스로 문제를 해결 한 후 정답과 해설을 참조하길 바란다. 공부를 잘 하는 학생의 문제집은 항상 문제지면의 밑바닥은 까맣지만 정답과 해설지면은 하얗다는 사실을 잊지 말자.
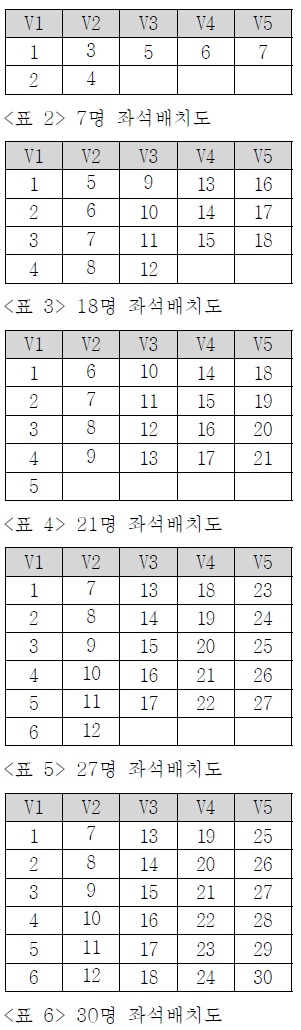
[문제] 시험실 배정인원(6 ~ 30)을 입력받아 시험실 좌석배치도를 출력하는 쿼리를 작성하세요.
하나의 시험실에는 25명의 수험생이 입장하도록 되어 있습니다. 좌석배치의 원리는 왼쪽 좌석부터 앞에서 뒤로 채우며 5줄의 좌석을 채웁니다. 25명이 시험을 치를 경우 다음과 같은 5*5 좌석배치도가 나오게 됩니다.
| V1 | V2 | V3 | V4 | V5 |
|---|---|---|---|---|
| 1 | 6 | 11 | 16 | 21 |
| 2 | 7 | 12 | 17 | 22 |
| 3 | 8 | 13 | 18 | 23 |
| 4 | 9 | 14 | 19 | 24 |
| 5 | 10 | 15 | 20 | 25 |
그러나 각 시험실마다 25명씩 인원을 배정하다 보면 마지막 시험실의 인원은 25명이 정확하게 떨어지질 않게 됩니다.
또한 마지막 시험실 인원이 5명 이하인 경우엔 이 인원을 위한 시험실을 따로 배정하지 않고 직전 시험실에서 함께 시험을 치루도록 합니다.
이렇게 시험실에 인원을 배정하게 될 경우 마지막 시험실에 배정되는 인원은 최소 6명부터 최대 30명까지가 됩니다.
[표 1] ~ [표 6]는 입력된 인원에 따른 좌석배치도 결과를 나타냅니다.
[문제] 시험실 배정인원(6 ~ 30)을 입력받아 시험실 좌석배치도를 출력하는 쿼리를 작성하세요.
문제를 스스로 해결해 보셨나요? 이제 정답을 알아보겠습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | -- Inwon 바인드 변수를 10으로 설정 한 경우SELECT MIN(DECODE(x, 1, v)) v1 , MIN(DECODE(x, 2, v)) v2 , MIN(DECODE(x, 3, v)) v3 , MIN(DECODE(x, 4, v)) v4 , MIN(DECODE(x, 5, v)) v5 FROM (SELECT v , x , ROW_NUMBER() OVER(PARTITION BY x ORDER BY v) y FROM (SELECT v , NTILE(5) OVER(ORDER BY v) x FROM (SELECT LEVEL v FROM dual CONNECT BY LEVEL <= :Inwon) ) ) GROUP BY y ORDER BY 1; V1 V2 V3 V4 V5----- ---------- ---------- ---------- ---------- 1 3 5 7 9 2 4 6 8 10 |
1 2 3 4 5 6 7 | SQL> VAR inwon numberSQL> BEGIN :inwon := 10; END; /SQL> PRINT inwon; INWON---------- 10 |
우선 입력 받은 인원수 만큼의 일련번호를 생성해야 합니다. 이는 다음과 같이 Connect By Level <= 인원수 를 이용하시면 됩니다.
1 | SELECT LEVEL v FROM dual CONNECT BY LEVEL <= :Inwon; |
이렇게 생성된 자료를 5열에 적절히 나누어 배치시켜야 하는데요. 우선은 가변적인 인원에 대한 복잡한 조건 없이, 고정으로 25명이 정해져 있을 때 어떻게 풀어나가야 하는지부터 살펴보겠습니다.
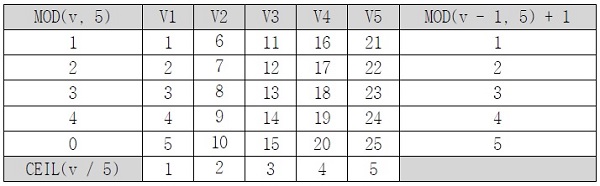
[표 1] 의 자료를 잘 보고 5*5 행렬에서 행과 열을 나누는 규칙을 찾아내야 합니다. 행을 구분하는 기준은 해당 번호를 5로 나눈 나머지 값으로 구별이 가능합니다. 같은 열에 있는 번호를 5로 나눈 값을 올림 처리하면 같은 값이 나오는 것이 확인됩니다.
이를 표로 그려보면 [표 7] 의 그림이 나오게 됩니다. [표 7]의 맨 오른쪽 컬럼은 나머지 값이 1,2,3,4,0 이 나오는 것을 1,2,3,4,5가 나오도록 해주는 팁을 보여줍니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | SELECT MIN(DECODE(x, 1, v)) v1 , MIN(DECODE(x, 2, v)) v2 , MIN(DECODE(x, 3, v)) v3 , MIN(DECODE(x, 4, v)) v4 , MIN(DECODE(x, 5, v)) v5 FROM (SELECT v , CEIL(v / 5) x , MOD(v - 1, 5) + 1 y FROM (SELECT LEVEL v FROM dual CONNECT BY LEVEL <= 25) ) GROUP BY y ORDER BY 1; V1 V2 V3 V4 V5----- ---------- ---------- ---------- ---------- 1 6 11 16 21 2 7 12 17 22 3 8 13 18 23 4 9 14 19 24 5 10 15 20 25 |
[리스트 2] 의 쿼리를 보면 x, y 의 좌표를 계산 한 후에, y 값으로 Group By 하고, x 값 에 따라 행을 열로 변환하는 피벗 쿼리를 작성하였습니다.
오라클 버전이 11G라면 좀더 간단하게 피벗쿼리를 작성할 수 있습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | SELECT * FROM (SELECT v , CEIL(v / 5) x , MOD(v - 1, 5) + 1 y FROM (SELECT LEVEL v FROM dual CONNECT BY LEVEL <= 25) ) PIVOT (MIN(v) FOR x IN (1 x1, 2 x2, 3 x3, 4 x4, 5 x5)) ORDER BY 1; Y X1 X2 X3 X4 X5---- ---------- ---------- ---------- ---------- ---------- 1 1 6 11 16 21 2 2 7 12 17 22 3 3 8 13 18 23 4 4 9 14 19 24 5 5 10 15 20 25 |
간단하게 와 함수를 이용해 MOD CEIL x 좌표와 y 좌표를 구할 수 있었습니다.
25명 고정인 경우에는 간단하게 x, y 좌표를 구할 수 있었습니다. 그러나 문제에서 제시한 것과 같이 인원수가 6~30 으로 가변적일 경우 어떻게 처리를 해야 할까요?
[표 2]~[표 5] 를 보면 5개 열의 행수가 같지 않고 다른 것을 확인 할 수 있습니다. [표 3] 을 예를 들면 앞 3개 열은 4행이고, 나머지 2개열은 3행입니다.
이러한 특징까지 고려하여 x, y 좌표를 구해야 합니다. 다음 [리스트 4] 쿼리를 살펴 보겠습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | SELECT MIN(DECODE(x,1,v)) v1 , MIN(DECODE(x,2,v)) v2 , MIN(DECODE(x,3,v)) v3 , MIN(DECODE(x,4,v)) v4 , MIN(DECODE(x,5,v)) v5 FROM (SELECT v , CASE WHEN v <= v_m * v_c THEN CEIL(v / v_c) ELSE CEIL((v - v_m) / v_f) END x , CASE WHEN v <= v_m * v_c THEN MOD(v - 1, v_c) + 1 ELSE MOD(v - v_m - 1, v_f) + 1 END y FROM (SELECT LEVEL v , MOD(:Inwon, 5) v_m -- 긴 행의 열수 , CEIL(:Inwon / 5) v_c -- 긴 행의 행수 , FLOOR(:Inwon / 5) v_f -- 짧은 행의 행수 FROM dual CONNECT BY LEVEL <= :Inwon ) )GROUP BY yORDER BY y;-- Inwon을 18로 대입한 경우 V1 V2 V3 V4 V5---- ---------- ---------- ---------- ---------- 1 5 9 13 16 2 6 10 14 17 3 7 11 15 18 4 8 12 |
위 쿼리에서 v_m은 전체 인원을 5로 나눈 나머지로 결국 앞서 말한 긴행의 열수가 됩니다.
v_c 는 전체 인원을 5로 나누어 올림한 값으로 긴 행의 행수, v_f 는 전체 인원을 5로 나누어 버림한 값으로 짧은 행의 행수가 됩니다.
이해를 돕기 위해 [표 3]의 값을 대입해서 설명하도록 하겠습니다.

먼저 이렇게 계산식에서 자주 사용될 값들을 우선 인라인뷰로 묶었습니다.
다음에는 v_m * v_c 값을 v 와 비교합니다. v_m * v_c = 12 는 긴행이 되는 앞번호의 개수를 의미합니다.
Case 문은 앞번호인지 뒷번호인지에 따라 x, y 를 계산하는 계산식을 달리하고 있습니다.
즉, 12보다 작은 수는 4*3 배열로 앞 3개열을 채우고,12보다 큰수는 3*3 배열로 뒤 2개 열을 채우게 되는 것입니다.
앞번호는 v_c 4를 기준으로 mod 와 ceil 함수를 이용하여 x, y 값을 구하며, 뒷번호는 앞 3개 열을 의미하는 v_m 값인 3을 차감한 후에 짧은 행의 행수 v_f 값인 3을 기준으로 mod 와 ceil 함수를 이용하여 x, y 값을 구하게 됩니다.
여기까지 설명 잘 따라 오셨나요? 설명하는 저도 참 어렵네요.결국 어렵사리 x, y의 좌표를 구해냈습니다.
x, y 좌표만 구하면 피벗하는 방법은 앞서 25행 했던 방식과 동일합니다.
그런데 [리스트 4]의 쿼리는 너무 복잡하며, 설명하기도 힘들고 이해하기도 어려울 듯 합니다. 이렇게 어려운 방법 말고 획기적인 방법이 없을까요?
분석함수중에 딱 이 문제를 위한 함수가 하나 있었네요. 바로 NTILE 함수입니다.
NTILE 함수를 처음 접하시는 분도 계실 테지만, 분석함수에 대해 조금 공부하셨던 분이라면 아마 알고 계실 것입니다.
NTILE RANK, ROW_NUMBER 순위를 구하는 분석함수중 하나입니다. 순위를 구하는 분석함수는 ORDER BY 절이 필수로 들어가게 되며,정렬된 결과에 대해 NTILE에서 정한 숫자만큼의 구룹으로 나누어주는 함수입니다.
NTILE(5) 를 줄 경우 1번부터 5번까지 5개의 그룹으로 균등하게 나누어지며, 균등하게 배분하고 남은 수만큼은 앞 그룹부터 채우게 됩니다.
앞서 설명했던 [표 3] 을 예를 들면 18개 번호는 1부터 3까지 균등한 개수로 나누어 지게 되는데 5개 그룹에 3개씩 나누면 15개가 나누어 지고 나머지 3개는 1,2,3번 그룹에 배정되 게 됩니다.
즉, 4,4,4,3,3 의 개수로 1번부터 5번까지 그룹으로 나누어 지게 되는데 이때 정렬순서는 번호순서대로 그룹번호가 부여되게 되는 것입니다.
[리스트 4]의 쿼리에서 v_m, v_c, v_f 를 구하고 이를 다시 계산하고 Case 문을 이용해 복잡하게 구했던 x 좌표값을 NTILE 함수 한줄로 아주 간단하게 구할 수 있게 되었습니다.
1 | NTILE(5) OVER(ORDER BY v) x |
y의 값은 NTILE 을 이용해 구한 x 를 기준으로 다시 순위함수인 ROW_NUMBER 을 이용해 구했습니다.
1 | ROW_NUMBER() OVER(PARTITION BY x ORDER BY v) y |
x, y 좌표값을 구했으니 피벗은 동일한 방법으로 하면 되겠지요.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | SELECT MIN(DECODE(x, 1, v)) v1 , MIN(DECODE(x, 2, v)) v2 , MIN(DECODE(x, 3, v)) v3 , MIN(DECODE(x, 4, v)) v4 , MIN(DECODE(x, 5, v)) v5 FROM (SELECT v , x , ROW_NUMBER() OVER(PARTITION BY x ORDER BY v) y FROM (SELECT v , NTILE(5) OVER(ORDER BY v) x FROM (SELECT LEVEL v FROM dual CONNECT BY LEVEL <= :Inwon) ) ) GROUP BY y ORDER BY 1;-- Inwon을 18로 대입한 경우 V1 V2 V3 V4 V5----- ---------- ---------- ---------- ---------- 1 5 9 13 16 2 6 10 14 17 3 7 11 15 18 4 8 12 |
이번 퀴즈는 NTILE 함수를 활용하는 방법을 배워보았습니다. 부수적으로 분석함수가 없이도 문제를 풀어 보았지만 분석함수를 사용할 수 없는 특수한(?) 상황이 아니라면 NTILE 로 간단하게 푸는 것이 좋겠지요.
- 강좌 URL : http://www.gurubee.net/lecture/2282
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | -- 왕 단순 무식..WITH T( a ) AS( SELECT LEVEL FROM DUAL CONNECT BY LEVEL <= 30 )SELECT MIN(DECODE(grp,1,a)) V1, MIN(DECODE(grp,2,a)) V2, MIN(DECODE(grp,3,a)) V3, MIN(DECODE(grp,4,a)) V4, MIN(DECODE(grp,5,a)) V5FROM(SELECT CEIL(a /max_value) as grp , ROW_NUMBER() OVER(PARTITION BY CEIL(a /max_value) ORDER BY a ) rn , aFROM (SELECT (ROUND(MAX(a) OVER() / 5 )) max_value , a FROM T ) )GROUP BY rnORDER BY rn |
헉.. 틀렸당.. ㅜㅜ
마농님... 알고리즘 잘 짜셔서 게임 개발하셔도 될 것 같아요.... ㅎ.ㅎ