press x to close
이번 퀴즈로 배워보는 SQL 시간에는 분석함수(Analytic Function)를 이용하지 않고 랭킹 쿼리를 어떻게 작성하는지 알아본다.
지면 특성상 문제와 정답 그리고 해설이 같이 있다. 진정으로 자신의 SQL 실력을 키우고 싶다면 스스로 문제를 해결 한 후 정답과 해설을 참조하길 바란다.
공부를 잘 하는 학생의 문제집은 항상 문제지면의 밑바닥은 까맣지만 정답과 해설지면은 하얗다는 사실을 잊지 말자.
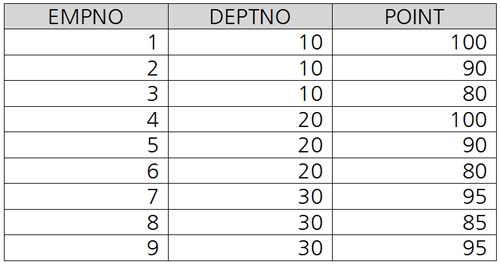
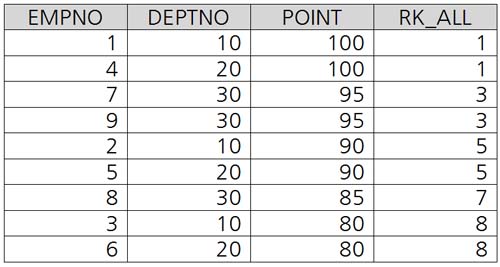
사원 테이블([그림 1] 참조)에서 각 사원 별 점수에 대한 전체 순위와 부서별 순위를 구한 뒤 <표 2>와 같은 랭킹 쿼리 결과를 보여주는 쿼리를 작성하세요.
쿼리 작성조건입니다.

1 2 3 4 5 6 7 8 9 10 11 12 13 | WITH test_rank AS( SELECT 1 empno, 10 deptno, 100 point FROM dual UNION ALL SELECT 2, 10, 90 FROM dual UNION ALL SELECT 3, 10, 80 FROM dual UNION ALL SELECT 4, 20, 100 FROM dual UNION ALL SELECT 5, 20, 90 FROM dual UNION ALL SELECT 6, 20, 80 FROM dual UNION ALL SELECT 7, 30, 95 FROM dual UNION ALL SELECT 8, 30, 85 FROM dual UNION ALL SELECT 9, 30, 95 FROM dual)-- 이곳에 들어갈 쿼리를 작성해 주세요. |
문제를 스스로 해결해 보셨나요? 이제 정답을 알아보겠습니다.
1 2 3 4 5 6 7 8 9 10 | SELECT a.empno , a.deptno , a.point , COUNT(b.empno) + 1 rk_all , COUNT(DECODE(a.deptno,b.deptno,1)) + 1 rk_dept FROM test_rank a , test_rank b WHERE a.point < b.point(+) GROUP BY a.empno, a.deptno, a.point ORDER BY deptno, rk_dept, empno; |
어떤가요? 여러분이 만들어본 리스트와 같은가요? 틀렸다고 좌절할 필요는 없답니다. 첫 술에 배부를 순 없는 것이니까요. 해설을 꼼꼼히 보고 자신이 잘못한 점을 비교해 보는 것이 더 중요합니다.
이 문제는 랭킹의 기본 원리를 바탕으로 셀프조인을 이용해 결과를 도출하는 문제입니다.
문제를 풀기 위해선 셀프조인과 아우터조인 그리고 그룹바이에 대한 이해는 기본이고 이를 응용할 줄도 알아야 합니다. 독자들을 위해 기본적인 내용부터 응용까지 차근차근 접근해보겠습니다.
1 2 3 4 5 6 7 8 | SELECT empno , deptno , point , RANK() OVER(ORDER BY point DESC) rk_all , RANK() OVER(PARTITION BY deptno ORDER BY point DESC) rk_dept FROM test_rank ORDER BY deptno, rk_dept, empno; |
위 쿼리를 실행하면 [그림 2]의 랭킹 쿼리 결과가 나오게 됩니다.
분석함수 중 RANK 함수는 순위를 구하는 함수입니다. 구분 항목별 정렬기준에 따른 순위를 구할 때 다음과 같이 사용합니다.
RANK() OVER(PARTITION BY 구분항목 ORDER BY 정렬항목)
구분항목이 없으면 전체 순위가 되고 구분항목이 있으면 구분항목별 순위가 됩니다.
순위는 특성상 1등이 두 명일 경우 2등이 없이 바로 3등으로 넘어갑니다.
분석함수 중 하나인 RANK 함수의 사용법과 순위의 특성을 간단하게나마 살펴봤습니다. 지금부터 분석함수를 사용하지 않고 순위를 구하는 방법에 대해서 알아보겠습니다.
우선 우리는 ‘순위’의 개념을 다른 각도로 살펴볼 필요가 있습니다. 먼저 1등인 직원은 자신보다 큰 점수를 가진 직원이 없습니다. 2등인 직원은 자신보다 큰 점수를 가진 직원이 1명 있는 셈입니다. 그렇다면 5등인 직원은 어떨까요? 맞습니다. 자신보다 큰 점수를 가진 직원이 4명 있는 것입니다.
우리가 발견한 이 일정한 규칙을 기반으로 쿼리를 작성하면 됩니다. 다시 말하면 사원 테이블을 기준으로 점수가 더 큰 직원을 찾은 다음, 직원 수에 1을 더하면 순위가 나오는 것입니다.
1 2 3 4 5 6 7 8 9 10 | SELECT a.empno , a.deptno , a.point , COUNT(b.empno) + 1 rk_all FROM test_rank a , test_rank b WHERE a.point < b.point(+) GROUP BY a.empno, a.deptno, a.point ORDER BY rk_all, empno; |
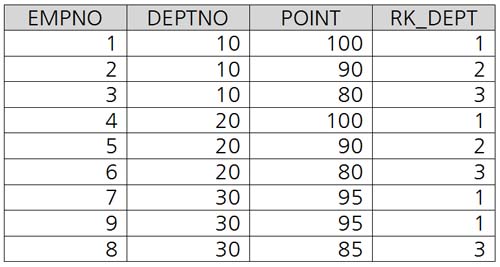
쿼리의 실행결과를 보면 전체 순위가 잘 나타난 것을 볼 수 있습니다. 여기에 사용된 기법은 세 가지입니다. 혹시 독자 여러분은 눈치 채셨나요?
- 셀프 조인 : From 절을 보시면 동일 테이블이 두 번 사용됐고 각각 a와 b로 별칭을 줬습니다. a의 점수보다 큰 점수를 가진 자료를 b에서 찾는 조건으로 조인합니다. 이와 같이 서로 같은 테이블끼리 조인하는 방법이 셀프조인입니다.
- 아우터 조인 : 여기서 아우터 조인을 왜 사용했을까요? 만약 아우터 조인을 사용하지 않았다면 우리는 1등을 찾을 수 없게 됩니다. 왜냐하면 1등에 해당하는 직원보다 큰 점수를 가진 직원이 없기 때문이죠. 즉 기준이 되는 직원보다 큰 점수를 가진 직원이 없더라도 해당 직원을 조회에서 누락시키지 않으려면 아우터 조인을 사용해야 합니다.
- COUNT(b.empno) : COUNT(*)가 아닌 COUNT(b.empno)를 사용한 이유는 무엇일까요? 이는 아우터 조인과 무관하지 않습니다.
아우터 조인의 결과로 1등에 해당하는 직원이 나왔습니다. 만약 COUNT(*)을 사용하면 1이 나오므로 1을 더하면 2등이 돼버립니다. 1등보다 큰 직원이 없으므로 b.empno는 Null이 되기 때문에 이를 카운트하면 0이 나오면서 자연스럽게 1등인 직원을 찾을 수 있게 되는 것입니다.
자 그럼 부서별 순위는 어떻게 구하면 될까요? 간단합니다. 위에서 사용한 조인 조건(점수가 더 큰 직원) 외에 부서가 동일한지 확인하는 조인조건만 추가하면 됩니다.
1 2 3 4 5 6 7 8 9 10 11 | SELECT a.empno , a.deptno , a.point , COUNT(b.empno) + 1 rk_dept FROM test_rank a , test_rank b WHERE a.point < b.point(+) AND a.deptno = b.deptno(+) GROUP BY a.empno, a.deptno, a.point ORDER BY deptno, rk_dept, empno; |
이제 전체 순위와 부서별 순위를 구했으니 두 개의 쿼리를 하나로 합쳐 보여주는 방법만 생각하면 됩니다. 어떻게 해야 할까요? 두 쿼리를 인라인 뷰로 해서 다시 조인할까요? 물론 그렇게 해도 결과는 나오겠지만 동일한 테이블을 네 번이나 읽어야 하고 쿼리도 복잡해집니다.
두 쿼리를 합치기 위해선 공통점과 차이점을 찾아야 합니다. <쿼리 3>과 <쿼리 4>의 차이점은 딱 한 가지, (a.deptno = b.deptno(+)) 조건만 다른 것을 알 수 있습니다. 만약 이 조건이 빠지게 된다면 하나의 쿼리로 합쳐질 수 있습니다.
그러나 이 조건이 조건절에서 빠진다면 부서별 순위는 제대로 나오지 않게 되겠죠. 동일 부서만 카운트해야 하는데 조건이 빠지게 되면 타 부서 직원까지 카운트하게 됩니다. 이 때 생각할 수 있는 방법이 Select 절에서의 조건 제어입니다.
조건을 줘서 결과를 구분할 수 있는 Decode 함수를 이용하면 문제가 해결됩니다.
1 2 3 4 5 6 7 8 9 10 | SELECT a.empno , a.deptno , a.point , COUNT(DECODE(a.deptno,b.deptno,1)) + 1 rk_dept FROM test_rank a , test_rank b WHERE a.point < b.point(+) GROUP BY a.empno, a.deptno, a.point ORDER BY deptno, rk_dept, empno; |
<쿼리 5> 쿼리를 보시면 Decode를 이용해 조건절에서 동일 부서로 거르지 못한 자료 중 동일 부서에 해당하는 자료만을 카운트하는 것을 알 수 있습니다.
자 이제 <쿼리 3>과 <쿼리 5>의 쿼리를 하나로 만들어 볼까요?
1 2 3 4 5 6 7 8 9 10 11 | SELECT a.empno , a.deptno , a.point , COUNT(b.empno) + 1 rk_all , COUNT(DECODE(a.deptno,b.deptno,1)) + 1 rk_dept FROM test_rank a , test_rank b WHERE a.point < b.point(+) GROUP BY a.empno, a.deptno, a.point ORDER BY deptno, rk_dept, empno; |
정답이 완성됐습니다. 지금까지 우리는 순위를 구하기 위해서 먼저 우선순위의 특성을 이해하고 그 특성에 맞게 쿼리를 작성했습니다. 또 전체 순위와 부서별 순위를 함께 보여주기 위해 Where 절의 조건을 버리고 Select 절에서 Decode로 제어하는 방법도 알아봤습니다.
알고 나면 쉽지만 알아내기 어려운 문제였습니다. 무엇보다 발상의 전환이 필요한 문제였습니다.
우리는 기준 점수보다 큰 점수를 가진 사원의 수를 이용해 순위를 구했습니다. 이 방법을 Self Join 과 Outer Join을 이용해 구했는데요. 다른 방법은 없을까요?
아우터 조인 방법은 Select절에서의 스칼라 서브쿼리로도 변경이 가능합니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | SELECT a.empno , a.deptno , a.point , (SELECT COUNT(*) + 1 FROM test_rank b WHERE a.point < b.point ) rk_all , (SELECT COUNT(*) + 1 FROM test_rank b WHERE a.point < b.point AND a.deptno = b.deptno ) rk_dept FROM test_rank a ORDER BY deptno, rk_dept, empno; |
<쿼리 7>을 보시면 랭킹을 구하기 위한 셀프 조인이 Select절 안의 서브쿼리 안에서 이루어 지는 것을 확인 할 수 있습니다. <쿼리 1>의 쿼리와 기본적인 개념은 동일합니다.
다만 아우터 조인방식을 사용했는지, 스칼라 서브쿼리 방식을 사용했는지만 다를 뿐이죠.
단, 스칼라 서브쿼리를 이용한 방법은 정답은 아닙니다. 퀴즈의 전제조건이 8.0버전에서의 쿼리인데, 불행하게도 해당 버전에서는 스칼라 서브쿼리를 지원하지 않습니다.
이번 퀴즈를 통해 랭킹을 구하는 세가지 다른 방법을 알아봤습니다.
한 가지만 아는 것보다는 여러 가지 방법을 익혀두고 원리를 이해한다면, 앞으로 다양한 조건의 응용문제에 대응하여 최적의 쿼리를 작성하는데 많은 도움이 될 것입니다.
- 강좌 URL : http://www.gurubee.net/lecture/2192
- 구루비 강좌는 개인의 학습용으로만 사용 할 수 있으며, 다른 웹 페이지에 게재할 경우에는 출처를 꼭 밝혀 주시면 고맙겠습니다.~^^
- 구루비 강좌는 서비스 제공을 위한 목적이나, 학원 홍보, 수익을 얻기 위한 용도로 사용 할 수 없습니다.
좋은 글 감사합니다 ^^
select a.empno,a.deptno,a.point,
count(case when a.point-b.point<0 then 1 end)+1 as rk_all,
count(case when a.deptno=b.deptno and a.point-b.point<0 then 1 end)+1 as rk_dept
from test_rank a
cross join test_rank b
group by a.empno,a.deptno,a.point
order by a.deptno,rk_dept,a.empno desc;
헛! 답이랑 비슷한듯하면서 다르게 되버렸네.