데이터베이스 노하우/팁/자료실
by 루카스 [PostgreSQL 노하우/팁/자료] PostgreSQL Tuning Basic [2024.07.12 08:31:11]
이미 자료에 있을 수 있겠지만, PostgreSQL 튜닝을 쉽게 알아보고자 한다.
1. PostgreSQL 넌 뜨겁구나
상용 DBMS는 대부분 DBMS에서 사용하는 메모리 부분이나 세션관련된 파라미터는 AUTO이다. 우리가 처음 수동 변속기 차량을 운전하면 어렵다고 느끼게 된다 이유는 클러치를 밟아야 하고 또 속도나 엔진의 RPM에 따른 변속을 해주어야한다. 그렇지 못하면 차량이 울컥하거나 심하면 엔진이 꺼진다. 하지만 오토변속기는 클러치나 변속 타이밍에 신경을 써야할 필요가 없기에 운전에 대한 부담이 적기에 한결 운전하기 편하고 집중 할 수 있다.
아쉽게도 오늘의 주인공은 수동이다. 하지만 수동이 단점만 있는 것인가 그렇지는 않다 수동이기에 가볍고 메모리의 효율도 좋고 최적의 설정시 좋은 성능을 발휘 한다.
급변하고 급속하게 커지고 있는 데이터 시장에서 DBMS는 더 다양하고 더 많은 데이터를 저장 할 것을 강하게 요구받고 있다. 수동이지만 날렵한 이번 주인공인 PostgreSQL의 파리미터 설정을 통해 급변하는 데이터 시장의 요구를 대응해보자. 레이싱 경기를 치루는 고성능 스포츠카 차량의 대부분은 수동임을 기억하자.
2. 어디부터 볼까
DBMS(PostgreSQL)의 설정 변수는 매우 다양하다. 서버 스펙, 네트워크 및 설정, 스토리지 서버, DBMS를 구동하기 위한 OS 환경변수, DBMS의 기초인 인스턴스 환경변수, DB부분의 환경변수 등 공개된 변수와 공개되지 않은 변수까지 더하면 약 백여가지에 이른다. 우린 이 모든 것을 한번에 보기는 불가능에 가깝다. 그래서 조금씩 알아가보기로 하며, 위의 변수들은 어렵고 지루할 수 있는 이야기들이다. 하지만 반드시 성능을 위해 알아야하는 이야기이기에 쉽게 풀어가보려 한다.
3.메모리 부터 풀어보자
메모리는 DBMS에 매우 중요한 요소이다, 수많은 요소들이 DBMS에 많은 영향을 미치지만 메모리는 가장 큰 영향을 미치는 요소들 중에 하나이다. 이에 DBMS와 메모리는 매우 깊고 중요한 관계이다. 데이터의 다양성, 사이즈, 다양한 데이터 처리, 처리 속도에 대한 요구의 증가로 메모리 부분의 중요도는 더욱 증가하고 있다. 그래서 우리는 메모리 부문 부터 알아보기로 하자.
DBMS에서 사용되는 heap, cash, mem 라고 부르는 것에 대하여 이야기 할 것이다. 왜 같은 메모리인데 다르게 부르고 또 어떻게 사용되는지 간단하게 집고 넘어가자.
heap : DBMS 인스턴스의 다양한 활동을 지원하기 위한 필요한 정보를 주로 저장하는 데 사용되는 메모리의 한부분이다.
cash : DB에서 가장 자주 사용되는 데이터나 메타 데이터를 빠르게 접근할 수 있도록 설정되어 있는 메모리의 한 부분으로서 DB엔진이 가장 빠르게 접근 할 수 있는 주소에 배치되어진다. DB의 운영에 필요한 메타 정보, 통계정보, Explain 정보 등이 있다.
mem : 일반적인 DB가 사용하는 메모리 공간으로, 예를 들면 데이터가 상주하는 bufferpool이나 temp 공간 등이 있다.
각각의 DBMS 별로 사용되는 용어나 작동하는 방식은 각각 다를 수 있다.
4. DBMS와 메모리 그리고 스토리지, 그 둘의 끈끈함
메모리와 스토리지는 떨어 질 수 없다. 그래서 둘의 관계를 한번 간단하게 살펴보고자 한다.
요즘 DBMS들의 성능이 많이 좋아지고 평준화가 되어가고 있다. 그 이유 중 하나는 많은 사용자들이 스토리지 서버에 사용되는 저장장치를 HDD에서 SSD로 옮겨가면서 HDD의 RPM과 헤드의 물리적인 요소를 탈피함으로 물리적 한계를 극복한 논리적인 저장으로의 변화에 따른 속도의 증가로 서버용 스토리지의 성능은 눈부시게 향상 되었기 때문이다(눈물이 날 정도 이다. 오래 DB쪽에 일을 했다면 HDD 스토리지로 인한 스트레스는 아마 아시리라 생각한다).
메모리 역시 CPU의 클럭이 증가함에 따라 메모리의 클럭 역시 높아지고 있다. DDR3, 4, 5로 발전하면서 클럭이 비약적으로 높아짐에 따라 메모리 속도 역시 빨라지고 있다. 하지만 둘의 속도는 여전히 차이가 나고 있다.
메모리와 스토리지는 서로 필수 불가결한 존재이기에 둘 간의 성능 차이가 많이 난다면 여러운 환경에 직면하게 된다. 메모리는 DDR5(5600MHz)인데 스토리지 서버의 저장 장치를 HDD(아직 SSD는 가격이 비싸다)를 사용한다면 DBMS의 성능에 크나큰 장애가 될 것이다. 그 이유는, 메모리는 휘발성이라는 매우 큰 단점이 있기 때문에 비휘발성인 스토리지에 저장을 해야한다. 메모리에서 스토리지에 쓰는 시간이 오래 걸린다면 I/O wait가 많이 발생하고 commit이나 log 쓰기, 데이터 저장, temp 작업 등이 느려지기에 DB 성능의 발목을 잡는다. 또한, DBMS 작업의 대부분이 메모리에서 일어나는데 데이터를 메모리에 올리는 상황에서도 느린 스토리지로 인해 메모리에 데이터의 적재가 늦어지면 DB의 성능이 느려진다. 그로인한 DB 옵티마이저(Optimizer)의 오판을 불러오기도 한다는 것을 기억하자.
PostgreSQL 메모리 구조
DBMS의 메모리 구조는 상당히 복잡하다. 메모리의 구조를 알지 못한다면 튜닝의 포인트를 잡을 수가 없다. 그러니 간단하게 메모리의 구조를 집고 넘어가자. DBMS의 제품별로 메모리 구조나 용어가 서로 크게 다를 수 있다. 크게 공유 메모리를 강조하는 쪽과 비공유 메모리를 강조하는 쪽으로 나누어지는데 우리가 다룰 PostgreSQL은 비공유를 강조하는 쪽에 가깝다.
Postgresql은 크게 Local Memory와 Shared Memory로 나눌 수 있다.
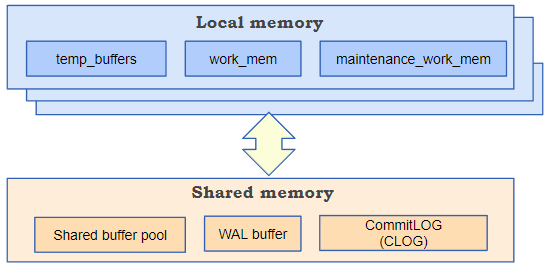
Local Memory : 개별 Backend process가 개별로 할당을 받아 사용하는 비공유 메모리로, 전체 Connection의 수를 고려하여 설정해야한다. 하위로는 Maintenance_work_mem, Temp_buffer, Work_mem, Catalog_cache, Optimizer, Executer 등이 있다.
Shared Memory : 모든 process가 공유해서 사용하는 공간으로, 전체 물리 메모리와 세션수를 고려하여 설정을 해야한다. 하위로는 Sheard Buffers, WAL Buffers, CLOG buffers, Lock Space, Other Buffers가 있다.
PostgreSQL 메모리별 역할
Local Memory 메모리에 포함되는 메모리
Maintenance_work_mem : VACUUM, CREATE INDEX, and Restoring database dumps 작업시 사용되는 메모리로, work_mem보다 크게 설정하는 것을 권장한다.(기본 64MB)
Temp_buffer : 세션에서 사용할 수 있는 Temp buffer 메모리의 양을 설정한다. Temp buffer의 활용도는 생각보다 많다는 것을 기억하자. 세션의 작업 형태나 SQL의 업무에 따라 다르기에 적절한 양의 설정이 필요하다. Temp_buffer에 설정된 양까지 각 세션에서 사용할 수 있다.
Work_mem : 세션의 작업시 사용되는 메모리로, Sort(Order by, Distinct, Merge join), Hash 등에 사용되며 세션 작업 별로 지정된 메모리가 할당되기에 총 세션수와 총 물리 메모리를 고려해 설정해한다.
Catalog_cache : system catalog 메타 데이터를 조회할 때 사용하는 메모리로, 자주 사용되는 영역으로 별도의 메모리로 관리하는 메모리이다.
Optimizer / Executer : SQL를 실행계획을 생성하고 실행하는데 필요한 메모리영역이다.
Shared Memory 메모리에 포함되는 메모리
Shared Buffers : Disk의 I/O에 가장 크게 영향을 미치는 메모리로, Disk로부터 데이터를 메모리로, 메모리에서 Disk로, 데이터의 변경 등에 사용되는 buffer로 DB의 성능에 큰 영향을 주는 메모리이다.
WAL Buffers : 각각의 세션들에서 수행되는 트랜잭션에 변경된 데이터에 대한 변경 로그를 캐싱하는 메모리로, Disk에 쓰기 전에 WAL 데이터의 버퍼링 하는 메모리이다.
CLOG buffers : CLOG는 Commit Log로 CLOG는 CC(Concurrency Control) 메커니즘에 대한 모든 트랜잭션의 상태(예 : in_progress, committed, aborted)를 유지한다.
Lock Space : Lock와 관련된 정보를 저장하는 메모리로, DBMS에서 사용되는 모든 Lock정보를 기록합니다. 데이터의 정합성을 유지할 때 중요한 역할을 하는 것이 Lock이다.
이번에는 DBMS에서 사용되는 메모리에 대하여 간단하게 살펴 보았다.
다음 편부터 실질 적인 메모리 부분 파라미터들의 종류와 역활에 대하여 그리고 그 파라미터들의 변경을 통해 성능이 어떻게 변하는지(튜닝) 알아보도록 하자
좋은글 감사합니다. 기회가 된다면 I/O 측면에서도 자료가 있다면 공유 부탁드립니다 + ㅁ +)/
OLTP에서 가장 중요한 조회(SELECT), 조회 성능에 가장 중요한 디스크 i/O, 컴퓨터 부품 중에 가장 비약적으로 속도가 빨라진 것이 I/O 인데, 이를 다룬 한국 자료는 거의 전무합니다.
특히 M.2 SSD 경우 GEN5를 지원하며 곱하기에 곱하기로 I/O 속도가 빨라지고 있으며 여기에 MSSQL를 설치하면, 어떤 DBMS를 설치하면 굉장히 빠른 속도를 기록하고 있고, 테이블 기준, 천만건 단위는 풀스캔은 정말 빠릅니다. 외국 자료 경우 관련 벤치마크 자료가 계속 업데이트 되고 있네용.